 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universally-Deployable ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement, and Voice Separation
Sep 14, 2022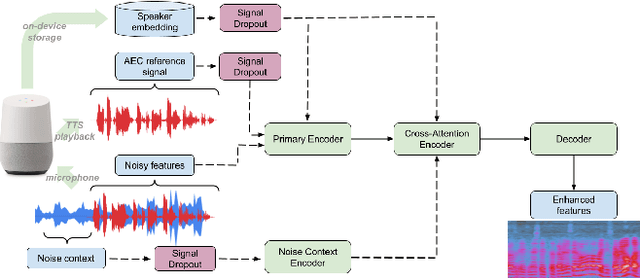

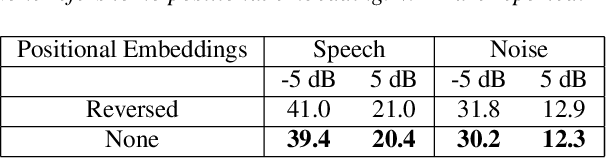
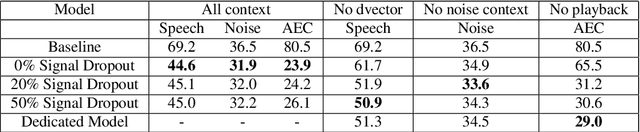
Recent work has shown that it is possible to train a single model to perform joint acoustic echo cancellation (AEC), speech enhancement, and voice separation, thereby serving as a unified frontend for robust automatic speech recognition (ASR). The joint model uses contextual information, such as a reference of the playback audio, noise context, and speaker embedding. In this work, we propose a number of novel improvements to such a model. First, we improve the architecture of the Cross-Attention Conformer that is used to ingest noise context into the model. Second, we generalize the model to be able to handle varying lengths of noise context. Third, we propose Signal Dropout, a novel strategy that models missing contextual information. In the absence of one or more signals, the proposed model performs nearly as well as task-specific models trained without these signals; and when such signals are present, our system compares well against systems that require all context signals. Over the baseline, the final model retains a relative word error rate reduction of 25.0% on background speech when speaker embedding is absent, and 61.2% on AEC when device playback is absent.
Cleanformer: A microphone array configuration-invariant, streaming, multichannel neural enhancement frontend for ASR
Apr 28, 2022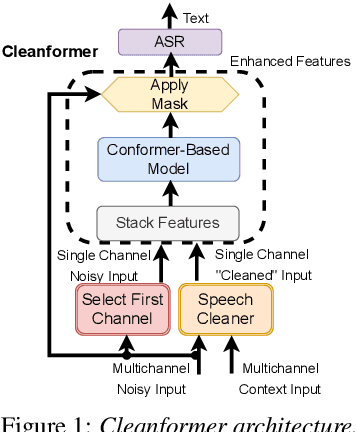
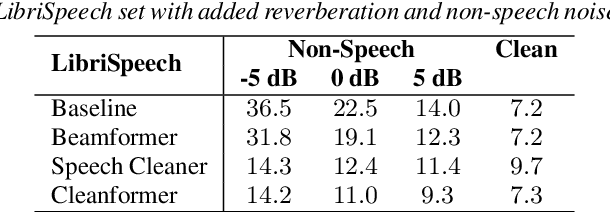
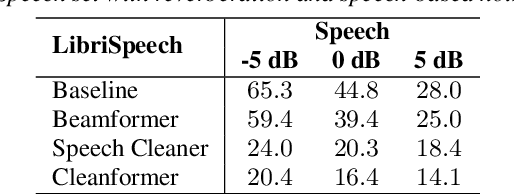
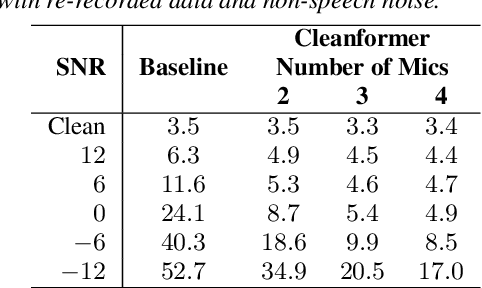
This work introduces the Cleanformer, a streaming multichannel neural based enhancement frontend for automatic speech recognition (ASR). This model has a conformer-based architecture which takes as inputs a single channel each of raw and enhanced signals, and uses self-attention to derive a time-frequency mask. The enhanced input is generated by a multichannel adaptive noise cancellation algorithm known as Speech Cleaner, which makes use of noise context to derive its filter taps. The time-frequency mask is applied to the noisy input to produce enhanced output features for ASR. Detailed evaluations are presented with simulated and re-recorded datasets in speech-based and non-speech-based noise that show significant reduction in word error rate (WER) when using a large-scale state-of-the-art ASR model. It also will be shown to significantly outperform enhancement using a beamformer with ideal steering. The enhancement model is agnostic of the number of microphones and array configuration and, therefore, can be used with different microphone arrays without the need for retraining. It is demonstrated that performance improves with more microphones, up to 4, with each additional microphone providing a smaller marginal benefit. Specifically, for an SNR of -6dB, relative WER improvements of about 80\% are shown in both noise conditions.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022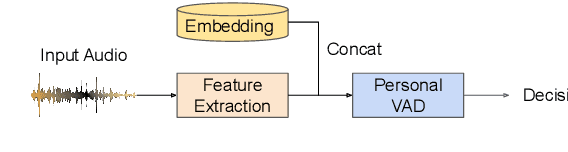
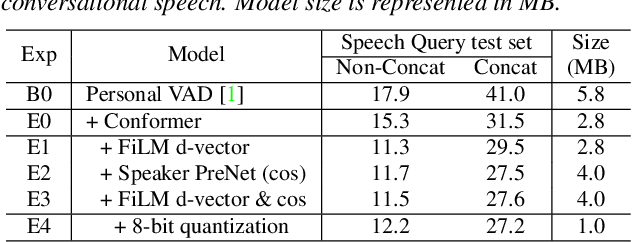
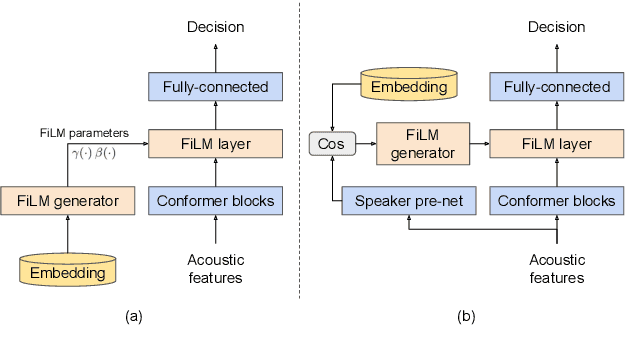
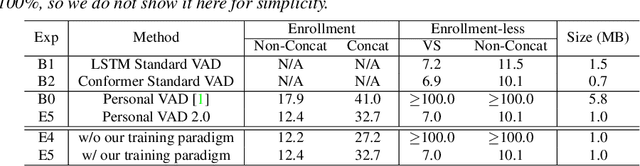
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
A Conformer-based ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement and Speech Separation
Nov 18, 2021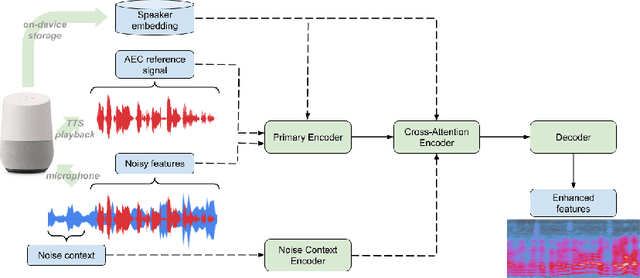
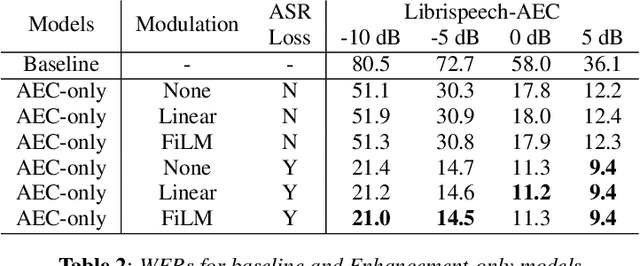
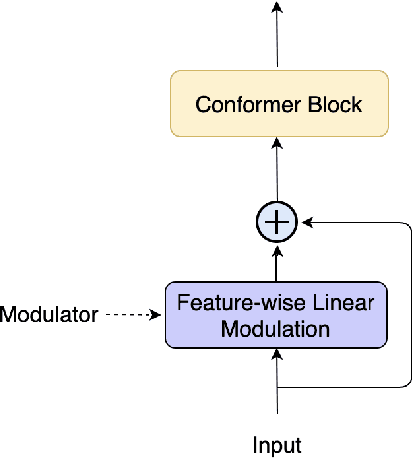
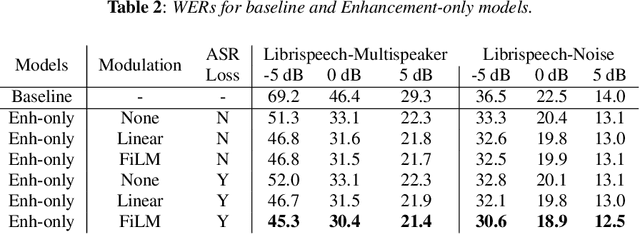
We present a frontend for improving robustness of automatic speech recognition (ASR), that jointly implements three modules within a single model: acoustic echo cancellation, speech enhancement, and speech separation. This is achieved by using a contextual enhancement neural network that can optionally make use of different types of side inputs: (1) a reference signal of the playback audio, which is necessary for echo cancellation; (2) a noise context, which is useful for speech enhancement; and (3) an embedding vector representing the voice characteristic of the target speaker of interest, which is not only critical in speech separation, but also helpful for echo cancellation and speech enhancement. We present detailed evaluations to show that the joint model performs almost as well as the task-specific models, and significantly reduces word error rate in noisy conditions even when using a large-scale state-of-the-art ASR model. Compared to the noisy baseline, the joint model reduces the word error rate in low signal-to-noise ratio conditions by at least 71% on our echo cancellation dataset, 10% on our noisy dataset, and 26% on our multi-speaker dataset. Compared to task-specific models, the joint model performs within 10% on our echo cancellation dataset, 2% on the noisy dataset, and 3% on the multi-speaker dataset.
Cross-attention conformer for context modeling in speech enhancement for ASR
Oct 30, 2021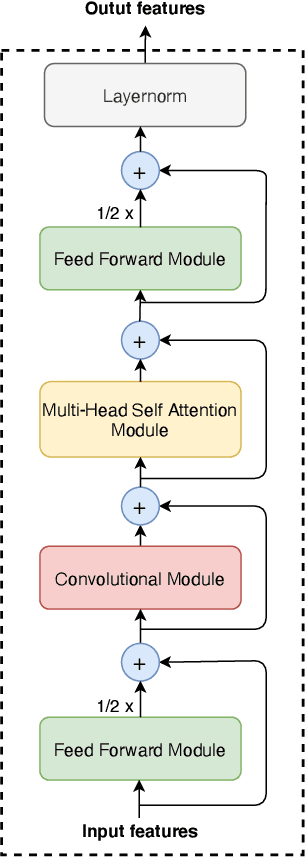

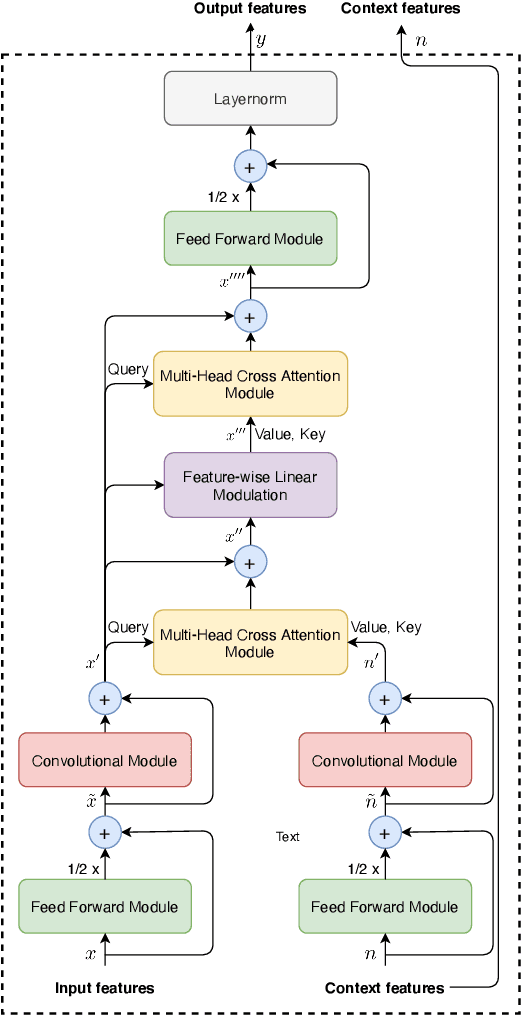
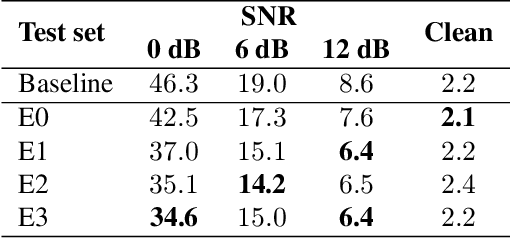
This work introduces \emph{cross-attention conformer}, an attention-based architecture for context modeling in speech enhancement. Given that the context information can often be sequential, and of different length as the audio that is to be enhanced, we make use of cross-attention to summarize and merge contextual information with input features. Building upon the recently proposed conformer model that uses self attention layers as building blocks, the proposed cross-attention conformer can be used to build deep contextual models. As a concrete example, we show how noise context, i.e., short noise-only audio segment preceding an utterance, can be used to build a speech enhancement feature frontend using cross-attention conformer layers for improving noise robustness of automatic speech recognition.