 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleanformer: A microphone array configuration-invariant, streaming, multichannel neural enhancement frontend for ASR
Apr 28, 2022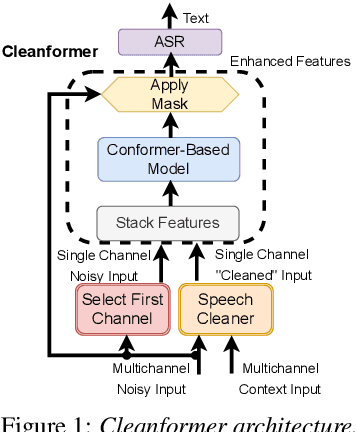
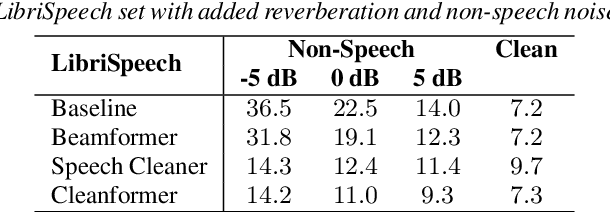
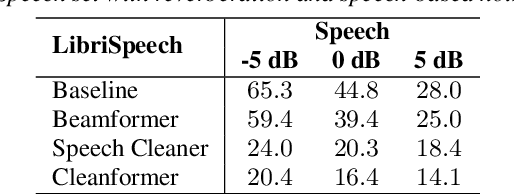
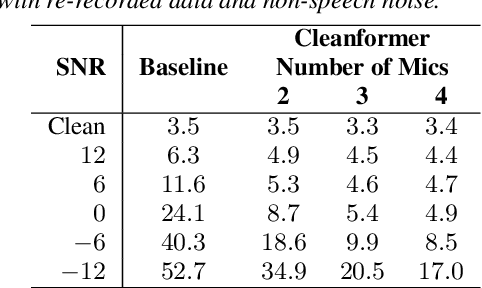
This work introduces the Cleanformer, a streaming multichannel neural based enhancement frontend for automatic speech recognition (ASR). This model has a conformer-based architecture which takes as inputs a single channel each of raw and enhanced signals, and uses self-attention to derive a time-frequency mask. The enhanced input is generated by a multichannel adaptive noise cancellation algorithm known as Speech Cleaner, which makes use of noise context to derive its filter taps. The time-frequency mask is applied to the noisy input to produce enhanced output features for ASR. Detailed evaluations are presented with simulated and re-recorded datasets in speech-based and non-speech-based noise that show significant reduction in word error rate (WER) when using a large-scale state-of-the-art ASR model. It also will be shown to significantly outperform enhancement using a beamformer with ideal steering. The enhancement model is agnostic of the number of microphones and array configuration and, therefore, can be used with different microphone arrays without the need for retraining. It is demonstrated that performance improves with more microphones, up to 4, with each additional microphone providing a smaller marginal benefit. Specifically, for an SNR of -6dB, relative WER improvements of about 80\% are shown in both noise conditions.