 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Symmetrization for Equivariance with Orbit Distance Minimization
Nov 13, 2023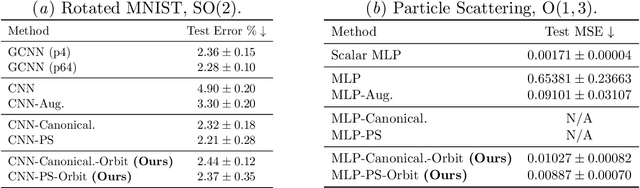

We present a general framework for symmetrizing an arbitrary neural-network architecture and making it equivariant with respect to a given group. We build upon the proposals of Kim et al. (2023); Kaba et al. (2023) for symmetrization, and improve them by replacing their conversion of neural features into group representations, with an optimization whose loss intuitively measures the distance between group orbits. This change makes our approach applicable to a broader range of matrix groups, such as the Lorentz group O(1, 3), than these two proposals. We experimentally show our method's competitiveness on the SO(2) image classification task, and also its increased generality on the task with O(1, 3). Our implementation will be made accessible at https://github.com/tiendatnguyen-vision/Orbit-symmetrize.
Learning Probabilistic Symmetrization for Architecture Agnostic Equivariance
Jun 05, 2023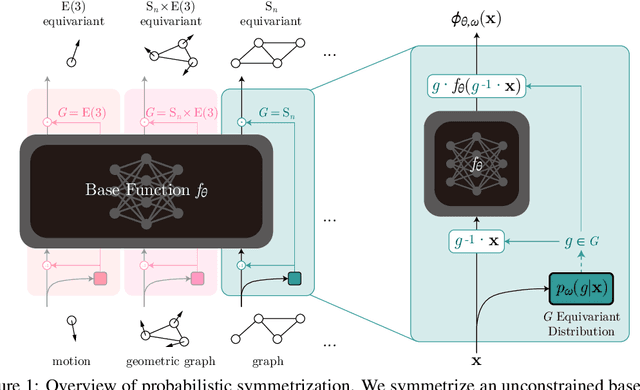
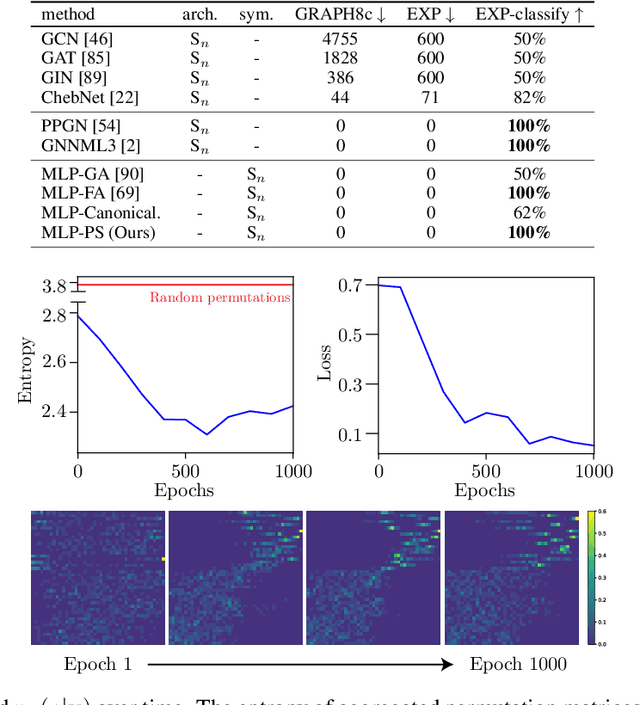
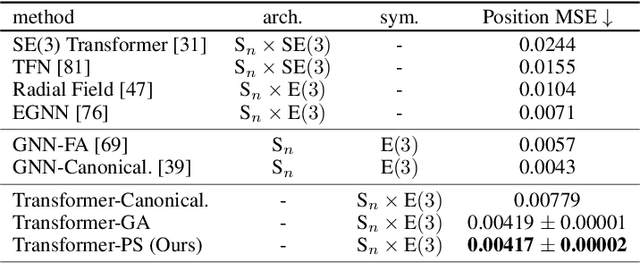

We present a novel framework to overcome the limitations of equivariant architectures in learning functions with group symmetries. In contrary to equivariant architectures, we use an arbitrary base model (such as an MLP or a transformer) and symmetrize it to be equivariant to the given group by employing a small equivariant network that parameterizes the probabilistic distribution underlying the symmetrization. The distribution is end-to-end trained with the base model which can maximize performance while reducing sample complexity of symmetrization. We show that this approach ensures not only equivariance to given group but also universal approximation capability in expectation. We implement our method on a simple patch-based transformer that can be initialized from pretrained vision transformers, and test it for a wide range of symmetry groups including permutation and Euclidean groups and their combinations. Empirical tests show competitive results against tailored equivariant architectures, suggesting the potential for learning equivariant functions for diverse groups using a non-equivariant universal base architecture. We further show evidence of enhanced learning in symmetric modalities, like graphs, when pretrained from non-symmetric modalities, like vision. Our implementation will be open-sourced at https://github.com/jw9730/lps.
Pure Transformers are Powerful Graph Learners
Jul 06, 2022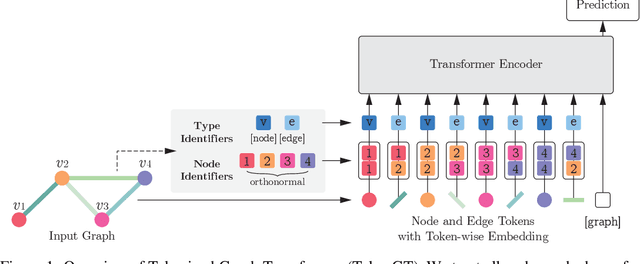
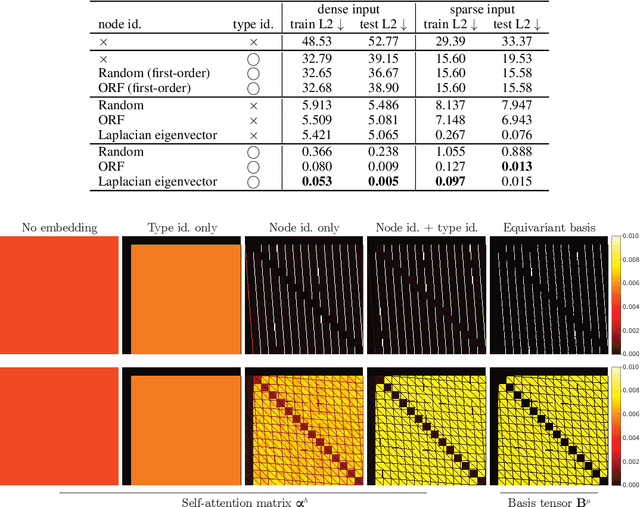
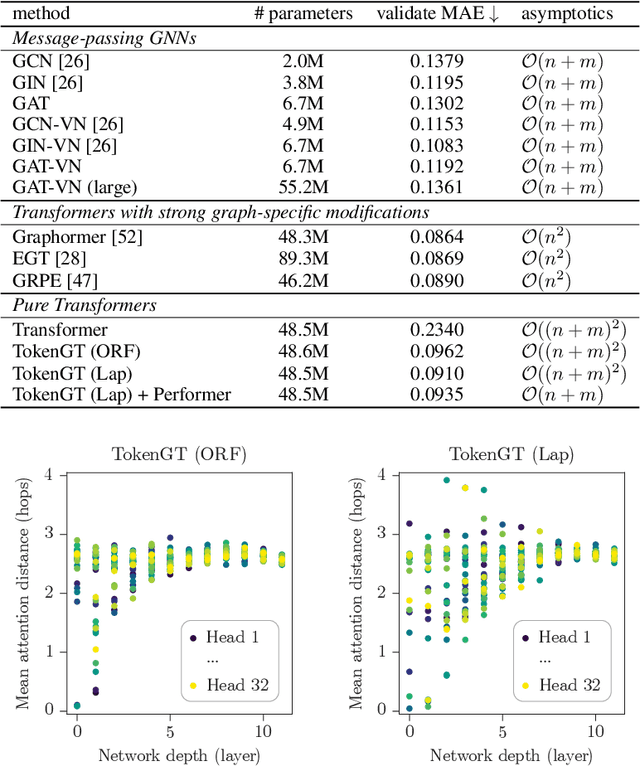

We show that standard Transformers without graph-specific modifications can lead to promising results in graph learning both in theory and practice. Given a graph, we simply treat all nodes and edges as independent tokens, augment them with token embeddings, and feed them to a Transformer. With an appropriate choice of token embeddings, we prove that this approach is theoretically at least as expressive as an invariant graph network (2-IGN) composed of equivariant linear layers, which is already more expressive than all message-passing Graph Neural Networks (GNN). When trained on a large-scale graph dataset (PCQM4Mv2), our method coined Tokenized Graph Transformer (TokenGT) achieves significantly better results compared to GNN baselines and competitive results compared to Transformer variants with sophisticated graph-specific inductive bias. Our implementation is available at https://github.com/jw9730/tokengt.