 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Mortgage Default with Machine Learning: AutoML, Class Imbalance, and Leakage Control
Jan 27, 2026Mortgage default prediction is a core task in financial risk management, and machine learning models are increasingly used to estimate default probabilities and provide interpretable signals for downstream decisions. In real-world mortgage datasets, however, three factors frequently undermine evaluation validity and deployment reliability: ambiguity in default labeling, severe class imbalance, and information leakage arising from temporal structure and post-event variables. We compare multiple machine learning approaches for mortgage default prediction using a real-world loan-level dataset, with emphasis on leakage control and imbalance handling. We employ leakage-aware feature selection, a strict temporal split that constrains both origination and reporting periods, and controlled downsampling of the majority class. Across multiple positive-to-negative ratios, performance remains stable, and an AutoML approach (AutoGluon) achieves the strongest AUROC among the models evaluated. An extended and pedagogical version of this work will appear as a book chapter.
Calibrate and Debias Layer-wise Sampling for Graph Convolutional Networks
Jun 01, 2022
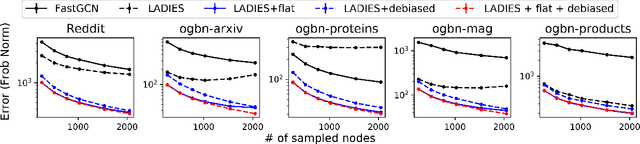
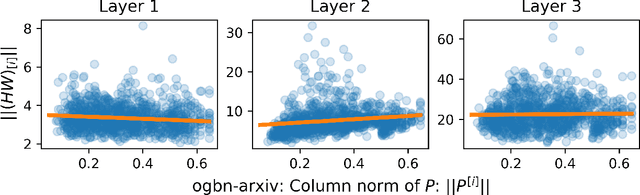

To accelerate the training of graph convolutional networks (GCNs), many sampling-based methods have been developed for approximating the embedding aggregation. Among them, a layer-wise approach recursively performs importance sampling to select neighbors jointly for existing nodes in each layer. This paper revisits the approach from a matrix approximation perspective. We identify two issues in the existing layer-wise sampling methods: sub-optimal sampling probabilities and the approximation bias induced by sampling without replacement. We propose two remedies: new sampling probabilities and a debiasing algorithm, to address these issues, and provide the statistical analysis of the estimation variance. The improvements are demonstrated by extensive analyses and experiments on common benchmarks.
On Variance Estimation of Random Forests
Feb 18, 2022
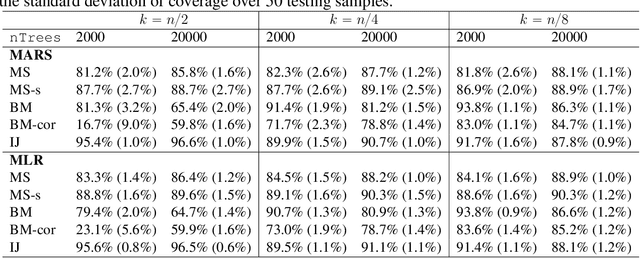
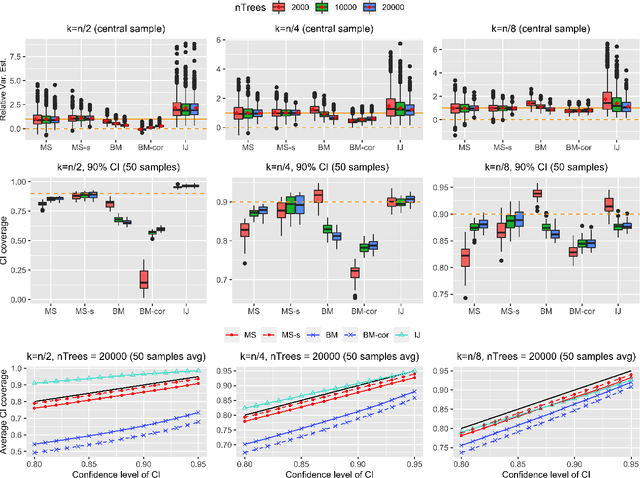
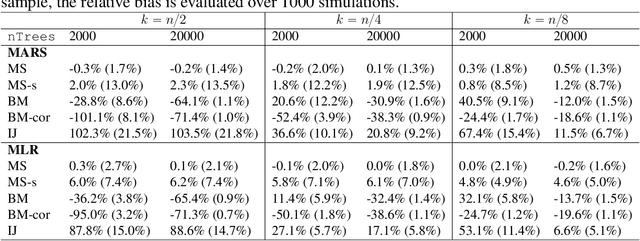
Ensemble methods based on subsampling, such as random forests, are popular in applications due to their high predictive accuracy. Existing literature views a random forest prediction as an infinite-order incomplete U-statistic to quantify its uncertainty. However, these methods focus on a small subsampling size of each tree, which is theoretically valid but practically limited. This paper develops an unbiased variance estimator based on incomplete U-statistics, which allows the tree size to be comparable with the overall sample size, making statistical inference possible in a broader range of real applications. Simulation results demonstrate that our estimators enjoy lower bias and more accurate confidence interval coverage without additional computational costs. We also propose a local smoothing procedure to reduce the variation of our estimator, which shows improved numerical performance when the number of trees is relatively small. Further, we investigate the ratio consistency of our proposed variance estimator under specific scenarios. In particular, we develop a new "double U-statistic" formulation to analyze the Hoeffding decomposition of the estimator's variance.