 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrate and Debias Layer-wise Sampling for Graph Convolutional Networks
Paper and Code

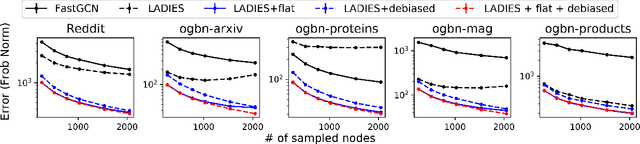
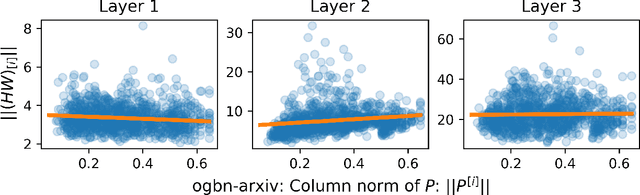

To accelerate the training of graph convolutional networks (GCNs), many sampling-based methods have been developed for approximating the embedding aggregation. Among them, a layer-wise approach recursively performs importance sampling to select neighbors jointly for existing nodes in each layer. This paper revisits the approach from a matrix approximation perspective. We identify two issues in the existing layer-wise sampling methods: sub-optimal sampling probabilities and the approximation bias induced by sampling without replacement. We propose two remedies: new sampling probabilities and a debiasing algorithm, to address these issues, and provide the statistical analysis of the estimation variance. The improvements are demonstrated by extensive analyses and experiments on common benchmarks.