 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation of smartphone-captured radiographs utilizing a deep learning-based approach
Sep 13, 2020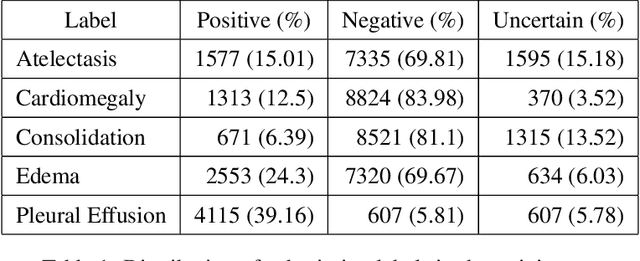
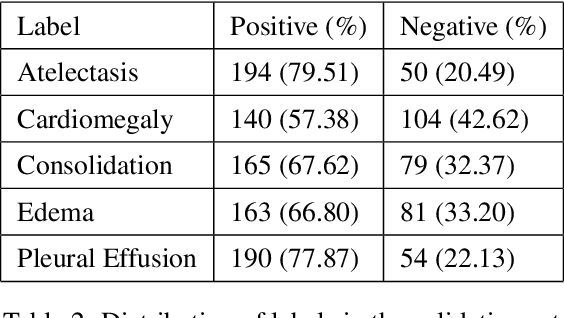
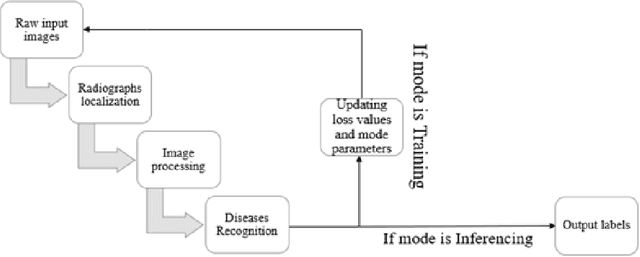
Recently, computer-aided diagnostic systems (CADs) that could automatically interpret medical images effectively have been the emerging subject of recent academic attention. For radiographs, several deep learning-based systems or models have been developed to study the multi-label diseases recognition tasks. However, none of them have been trained to work on smartphone-captured chest radiographs. In this study, we proposed a system that comprises a sequence of deep learning-based neural networks trained on the newly released CheXphoto dataset to tackle this issue. The proposed approach achieved promising results of 0.684 in AUC and 0.699 in average F1 score. To the best of our knowledge, this is the first published study that showed to be capable of processing smartphone-captured radiographs.
A novel approach to remove foreign objects from chest X-ray images
Aug 16, 2020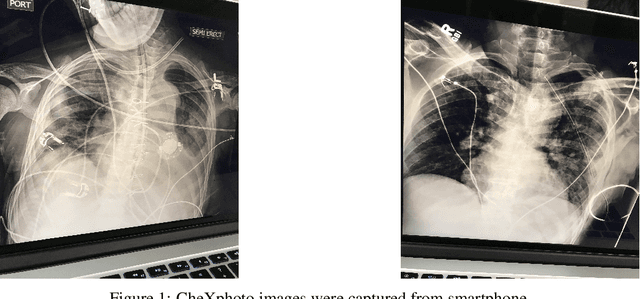


We initially proposed a deep learning approach for foreign objects inpainting in smartphone-camera captured chest radiographs utilizing the cheXphoto dataset. Foreign objects which can significantly affect the quality of a computer-aided diagnostic prediction are captured under various settings. In this paper, we used multi-method to tackle both removal and inpainting chest radiographs. Firstly, an object detection model is trained to separate the foreign objects from the given image. Subsequently, the binary mask of each object is extracted utilizing a segmentation model. Each pair of the binary mask and the extracted object are then used for inpainting purposes. Finally, the in-painted regions are now merged back to the original image, resulting in a clean and non-foreign-object-existing output. To conclude, we achieved state-of-the-art accuracy. The experimental results showed a new approach to the possible applications of this method for chest X-ray images detection.
Learning to Attend Relevant Regions in Videos from Eye Fixations
Nov 22, 2018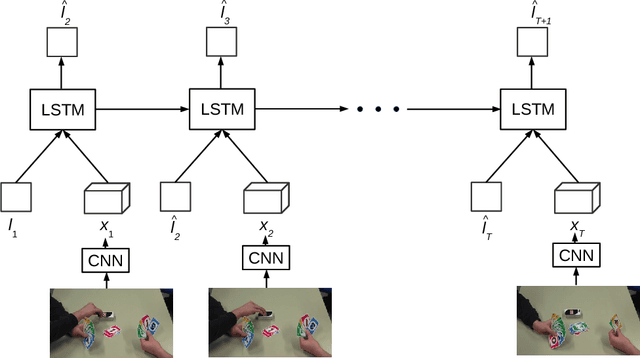
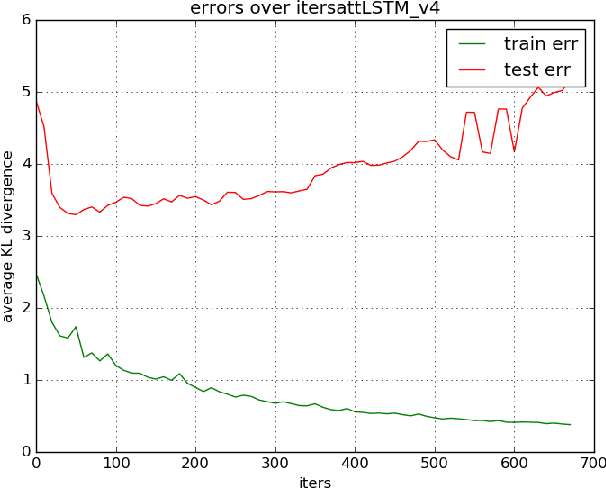

Attentively important regions in video frames account for a majority part of the semantics in each frame. This information is helpful in many applications not only for entertainment (such as auto generating commentary and tourist guide) but also for robotic control which holds a larascope supported for laparoscopic surgery. However, it is not always straightforward to define and locate such semantic regions in videos. In this work, we attempt to address the problem of attending relevant regions in videos by leveraging the eye fixations labels with a RNN-based visual attention model. Our experimental results suggest that this approach holds a good potential to learn to attend semantic regions in videos while its performance also heavily relies on the quality of eye fixations labels.
Layer-wise Learning of Stochastic Neural Networks with Information Bottleneck
Sep 12, 2018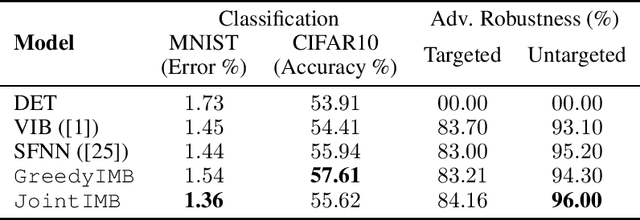
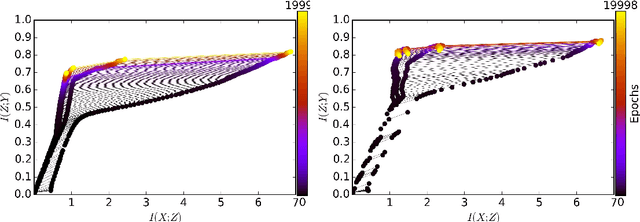

Deep neural networks (DNNs) offer flexible modeling capability for various important machine learning problems. Given the same neural modeling capability, the success of DNNs is attributed to how effectively we could learn the networks. Currently, the maximum likelihood estimate (MLE) principle has been a de-facto standard for learning DNNs. However, the MLE principle is not explicitly tailored to the hierarchical structure of DNNs. In this work, we propose the Parametric Information Bottleneck (PIB) framework as a fully information-theoretic learning principle of DNNs. Motivated by the Information Bottleneck principle, our framework efficiently induces relevant information under compression constraint into each layer of DNNs via multi-objective learning. Consequently, PIB generalizes the MLE principle in DNNs, indeed empirically exploits the neural representations better than MLE and a partially information-theoretic treatment, and offers better generalization and adversarial robustness on MNIST and CIFAR10.