 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Attend Relevant Regions in Videos from Eye Fixations
Paper and Code
Nov 22, 2018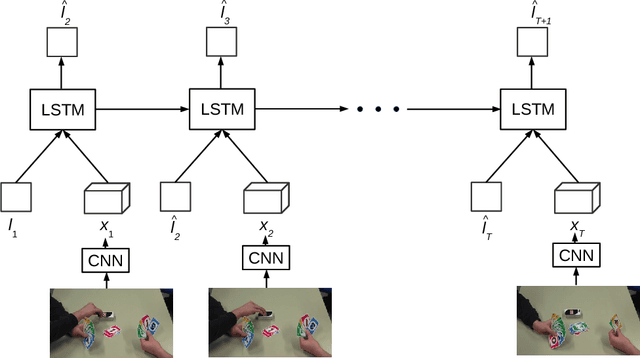
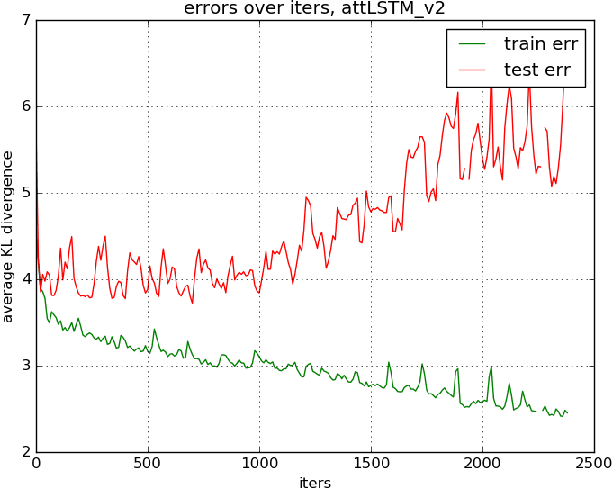
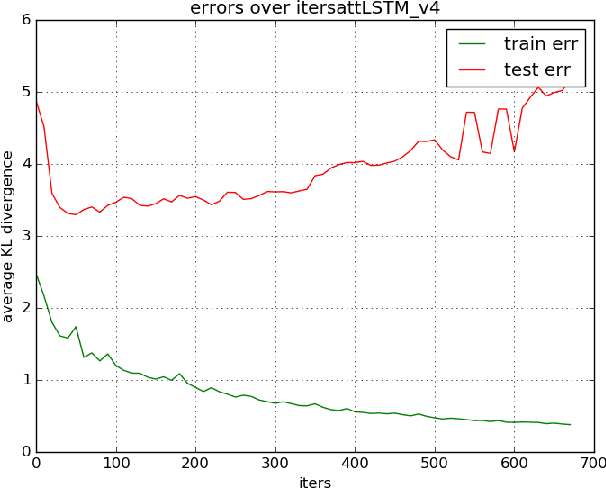

Attentively important regions in video frames account for a majority part of the semantics in each frame. This information is helpful in many applications not only for entertainment (such as auto generating commentary and tourist guide) but also for robotic control which holds a larascope supported for laparoscopic surgery. However, it is not always straightforward to define and locate such semantic regions in videos. In this work, we attempt to address the problem of attending relevant regions in videos by leveraging the eye fixations labels with a RNN-based visual attention model. Our experimental results suggest that this approach holds a good potential to learn to attend semantic regions in videos while its performance also heavily relies on the quality of eye fixations labels.