 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Learning of Stochastic Neural Networks with Information Bottleneck
Paper and Code
Sep 12, 2018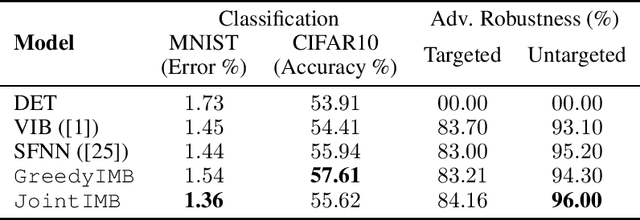
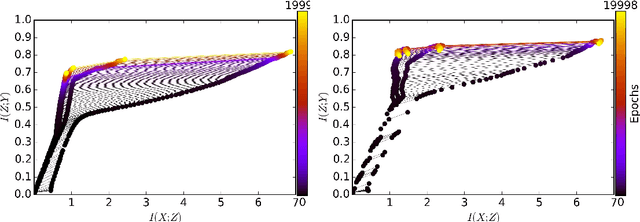

Deep neural networks (DNNs) offer flexible modeling capability for various important machine learning problems. Given the same neural modeling capability, the success of DNNs is attributed to how effectively we could learn the networks. Currently, the maximum likelihood estimate (MLE) principle has been a de-facto standard for learning DNNs. However, the MLE principle is not explicitly tailored to the hierarchical structure of DNNs. In this work, we propose the Parametric Information Bottleneck (PIB) framework as a fully information-theoretic learning principle of DNNs. Motivated by the Information Bottleneck principle, our framework efficiently induces relevant information under compression constraint into each layer of DNNs via multi-objective learning. Consequently, PIB generalizes the MLE principle in DNNs, indeed empirically exploits the neural representations better than MLE and a partially information-theoretic treatment, and offers better generalization and adversarial robustness on MNIST and CIFAR10.