 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Edge Computing and AI Enabled Web3 Metaverse over 6G Wireless Communications: A Deep Reinforcement Learning Approach
Dec 11, 2023The Metaverse is gaining attention among academics as maturing technologies empower the promises and envisagements of a multi-purpose, integrated virtual environment. An interactive and immersive socialization experience between people is one of the promises of the Metaverse. In spite of the rapid advancements in current technologies, the computation required for a smooth, seamless and immersive socialization experience in the Metaverse is overbearing, and the accumulated user experience is essential to be considered. The computation burden calls for computation offloading, where the integration of virtual and physical world scenes is offloaded to an edge server. This paper introduces a novel Quality-of-Service (QoS) model for the accumulated experience in multi-user socialization on a multichannel wireless network. This QoS model utilizes deep reinforcement learning approaches to find the near-optimal channel resource allocation. Comprehensive experiments demonstrate that the adoption of the QoS model enhances the overall socialization experience.
FedPEAT: Convergence of Federated Learning, Parameter-Efficient Fine Tuning, and Emulator Assisted Tuning for Artificial Intelligence Foundation Models with Mobile Edge Computing
Oct 26, 2023



The emergence of foundation models, including language and vision models, has reshaped AI's landscape, offering capabilities across various applications. Deploying and fine-tuning these large models, like GPT-3 and BERT, presents challenges, especially in the current foundation model era. We introduce Emulator-Assisted Tuning (EAT) combined with Parameter-Efficient Fine-Tuning (PEFT) to form Parameter-Efficient Emulator-Assisted Tuning (PEAT). Further, we expand this into federated learning as Federated PEAT (FedPEAT). FedPEAT uses adapters, emulators, and PEFT for federated model tuning, enhancing model privacy and memory efficiency. Adapters adjust pre-trained models, while emulators give a compact representation of original models, addressing both privacy and efficiency. Adaptable to various neural networks, our approach also uses deep reinforcement learning for hyper-parameter optimization. We tested FedPEAT in a unique scenario with a server participating in collaborative federated tuning, showcasing its potential in tackling foundation model challenges.
Orchestration of Emulator Assisted Mobile Edge Tuning for AI Foundation Models: A Multi-Agent Deep Reinforcement Learning Approach
Oct 26, 2023


The efficient deployment and fine-tuning of foundation models are pivotal in contemporary artificial intelligence. In this study, we present a groundbreaking paradigm integrating Mobile Edge Computing (MEC) with foundation models, specifically designed to enhance local task performance on user equipment (UE). Central to our approach is the innovative Emulator-Adapter architecture, segmenting the foundation model into two cohesive modules. This design not only conserves computational resources but also ensures adaptability and fine-tuning efficiency for downstream tasks. Additionally, we introduce an advanced resource allocation mechanism that is fine-tuned to the needs of the Emulator-Adapter structure in decentralized settings. To address the challenges presented by this system, we employ a hybrid multi-agent Deep Reinforcement Learning (DRL) strategy, adept at handling mixed discrete-continuous action spaces, ensuring dynamic and optimal resource allocations. Our comprehensive simulations and validations underscore the practical viability of our approach, demonstrating its robustness, efficiency, and scalability. Collectively, this work offers a fresh perspective on deploying foundation models and balancing computational efficiency with task proficiency.
Mobile Edge Adversarial Detection for Digital Twinning to the Metaverse with Deep Reinforcement Learning
Mar 18, 2023



Real-time Digital Twinning of physical world scenes onto the Metaverse is necessary for a myriad of applications such as augmented-reality (AR) assisted driving. In AR assisted driving, physical environment scenes are first captured by Internet of Vehicles (IoVs) and are uploaded to the Metaverse. A central Metaverse Map Service Provider (MMSP) will aggregate information from all IoVs to develop a central Metaverse Map. Information from the Metaverse Map can then be downloaded into individual IoVs on demand and be delivered as AR scenes to the driver. However, the growing interest in developing AR assisted driving applications which relies on digital twinning invites adversaries. These adversaries may place physical adversarial patches on physical world objects such as cars, signboards, or on roads, seeking to contort the virtual world digital twin. Hence, there is a need to detect these physical world adversarial patches. Nevertheless, as real-time, accurate detection of adversarial patches is compute-intensive, these physical world scenes have to be offloaded to the Metaverse Map Base Stations (MMBS) for computation. Hence in our work, we considered an environment with moving Internet of Vehicles (IoV), uploading real-time physical world scenes to the MMBSs. We formulated a realistic joint variable optimization problem where the MMSPs' objective is to maximize adversarial patch detection mean average precision (mAP), while minimizing the computed AR scene up-link transmission latency and IoVs' up-link transmission idle count, through optimizing the IoV-MMBS allocation and IoV up-link scene resolution selection. We proposed a Heterogeneous Action Proximal Policy Optimization (HAPPO) (discrete-continuous) algorithm to tackle the proposed problem. Extensive experiments shows HAPPO outperforms baseline models when compared against key metrics.
Detection of Uncertainty in Exceedance of Threshold (DUET): An Adversarial Patch Localizer
Mar 18, 2023Development of defenses against physical world attacks such as adversarial patches is gaining traction within the research community. We contribute to the field of adversarial patch detection by introducing an uncertainty-based adversarial patch localizer which localizes adversarial patch on an image, permitting post-processing patch-avoidance or patch-reconstruction. We quantify our prediction uncertainties with the development of \textit{\textbf{D}etection of \textbf{U}ncertainties in the \textbf{E}xceedance of \textbf{T}hreshold} (DUET) algorithm. This algorithm provides a framework to ascertain confidence in the adversarial patch localization, which is essential for safety-sensitive applications such as self-driving cars and medical imaging. We conducted experiments on localizing adversarial patches and found our proposed DUET model outperforms baseline models. We then conduct further analyses on our choice of model priors and the adoption of Bayesian Neural Networks in different layers within our model architecture. We found that isometric gaussian priors in Bayesian Neural Networks are suitable for patch localization tasks and the presence of Bayesian layers in the earlier neural network blocks facilitates top-end localization performance, while Bayesian layers added in the later neural network blocks contribute to better model generalization. We then propose two different well-performing models to tackle different use cases.
Virtual Reality in Metaverse over Wireless Networks with User-centered Deep Reinforcement Learning
Mar 08, 2023The Metaverse and its promises are fast becoming reality as maturing technologies are empowering the different facets. One of the highlights of the Metaverse is that it offers the possibility for highly immersive and interactive socialization. Virtual reality (VR) technologies are the backbone for the virtual universe within the Metaverse as they enable a hyper-realistic and immersive experience, and especially so in the context of socialization. As the virtual world 3D scenes to be rendered are of high resolution and frame rate, these scenes will be offloaded to an edge server for computation. Besides, the metaverse is user-center by design, and human users are always the core. In this work, we introduce a multi-user VR computation offloading over wireless communication scenario. In addition, we devised a novel user-centered deep reinforcement learning approach to find a near-optimal solution. Extensive experiments demonstrate that our approach can lead to remarkable results under various requirements and constraints.
User-centric Heterogeneous-action Deep Reinforcement Learning for Virtual Reality in the Metaverse over Wireless Networks
Feb 03, 2023The Metaverse is emerging as maturing technologies are empowering the different facets. Virtual Reality (VR) technologies serve as the backbone of the virtual universe within the Metaverse to offer a highly immersive user experience. As mobility is emphasized in the Metaverse context, VR devices reduce their weights at the sacrifice of local computation abilities. In this paper, for a system consisting of a Metaverse server and multiple VR users, we consider two cases of (i) the server generating frames and transmitting them to users, and (ii) users generating frames locally and thus consuming device energy. Moreover, in our multi-user VR scenario for the Metaverse, users have different characteristics and demands for Frames Per Second (FPS). Then the channel access arrangement (including the decisions on frame generation location), and transmission powers for the downlink communications from the server to the users are jointly optimized to improve the utilities of users. This joint optimization is addressed by deep reinforcement learning (DRL) with heterogeneous actions. Our proposed user-centric DRL algorithm is called User-centric Critic with Heterogenous Actors (UCHA). Extensive experiments demonstrate that our UCHA algorithm leads to remarkable results under various requirements and constraints.
Asynchronous Hybrid Reinforcement Learning for Latency and Reliability Optimization in the Metaverse over Wireless Communications
Dec 30, 2022
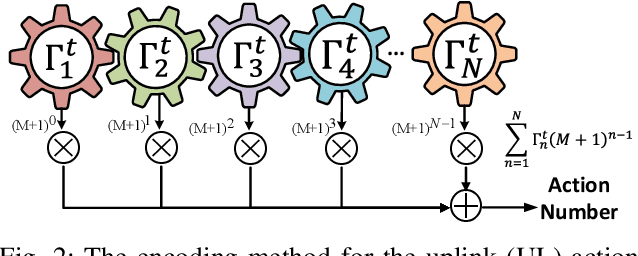


Technology advancements in wireless communications and high-performance Extended Reality (XR) have empowered the developments of the Metaverse. The demand for Metaverse applications and hence, real-time digital twinning of real-world scenes is increasing. Nevertheless, the replication of 2D physical world images into 3D virtual world scenes is computationally intensive and requires computation offloading. The disparity in transmitted scene dimension (2D as opposed to 3D) leads to asymmetric data sizes in uplink (UL) and downlink (DL). To ensure the reliability and low latency of the system, we consider an asynchronous joint UL-DL scenario where in the UL stage, the smaller data size of the physical world scenes captured by multiple extended reality users (XUs) will be uploaded to the Metaverse Console (MC) to be construed and rendered. In the DL stage, the larger-size 3D virtual world scenes need to be transmitted back to the XUs. The decisions pertaining to computation offloading and channel assignment are optimized in the UL stage, and the MC will optimize power allocation for users assigned with a channel in the UL transmission stage. Some problems arise therefrom: (i) interactive multi-process chain, specifically Asynchronous Markov Decision Process (AMDP), (ii) joint optimization in multiple processes, and (iii) high-dimensional objective functions, or hybrid reward scenarios. To ensure the reliability and low latency of the system, we design a novel multi-agent reinforcement learning algorithm structure, namely Asynchronous Actors Hybrid Critic (AAHC). Extensive experiments demonstrate that compared to proposed baselines, AAHC obtains better solutions with preferable training time.
Unified, User and Task (UUT) Centered Artificial Intelligence for Metaverse Edge Computing
Dec 19, 2022


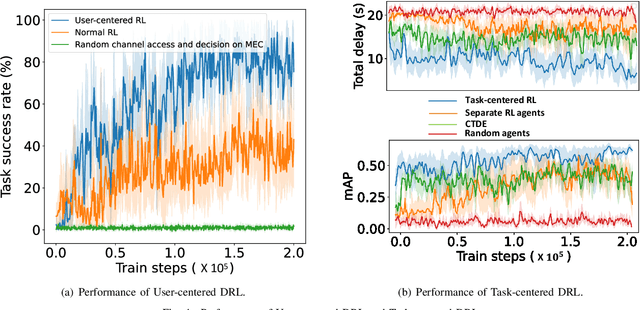
The Metaverse can be considered the extension of the present-day web, which integrates the physical and virtual worlds, delivering hyper-realistic user experiences. The inception of the Metaverse brings forth many ecosystem services such as content creation, social entertainment, in-world value transfer, intelligent traffic, healthcare. These services are compute-intensive and require computation offloading onto a Metaverse edge computing server (MECS). Existing Metaverse edge computing approaches do not efficiently and effectively handle resource allocation to ensure a fluid, seamless and hyper-realistic Metaverse experience required for Metaverse ecosystem services. Therefore, we introduce a new Metaverse-compatible, Unified, User and Task (UUT) centered artificial intelligence (AI)- based mobile edge computing (MEC) paradigm, which serves as a concept upon which future AI control algorithms could be built to develop a more user and task-focused MEC.
Time Minimization in Hierarchical Federated Learning
Oct 07, 2022

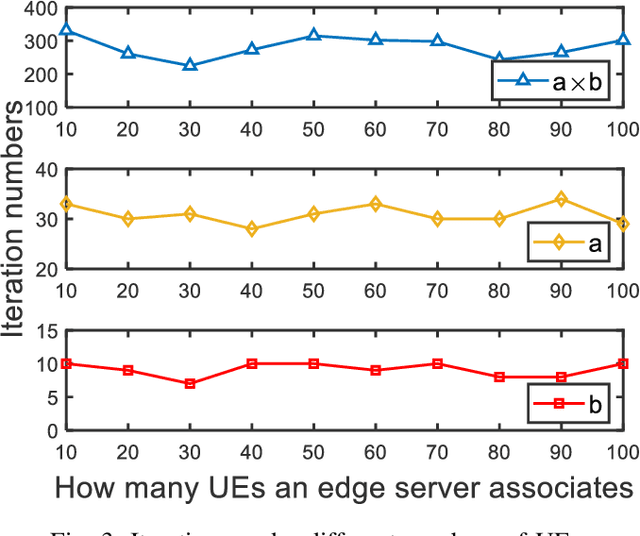

Federated Learning is a modern decentralized machine learning technique where user equipments perform machine learning tasks locally and then upload the model parameters to a central server. In this paper, we consider a 3-layer hierarchical federated learning system which involves model parameter exchanges between the cloud and edge servers, and the edge servers and user equipment. In a hierarchical federated learning model, delay in communication and computation of model parameters has a great impact on achieving a predefined global model accuracy. Therefore, we formulate a joint learning and communication optimization problem to minimize total model parameter communication and computation delay, by optimizing local iteration counts and edge iteration counts. To solve the problem, an iterative algorithm is proposed. After that, a time-minimized UE-to-edge association algorithm is presented where the maximum latency of the system is reduced. Simulation results show that the global model converges faster under optimal edge server and local iteration counts. The hierarchical federated learning latency is minimized with the proposed UE-to-edge association strategy.