 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Agent Traces to Trust: Evidence Tracing and Execution Provenance in LLM Agents
Jun 03, 2026Large language model (LLM)-based agents increasingly solve complex tasks by interacting with external tools, retrieval systems, memory modules, environments, and other agents. These capabilities expand agent autonomy, but also make agent behavior harder to verify, debug, and audit. Final-answer accuracy alone cannot explain how an output was produced, which evidence supported each claim, whether tool calls were justified, how memory influenced later decisions, or where execution failures originated. Evidence tracing and execution provenance address this gap by modeling how retrieved evidence, tool outputs, memory items, environment observations, intermediate claims, actions, and final answers are connected throughout agent execution. This survey provides a systematic review and conceptual framework for evidence tracing and execution provenance in LLM agents. We organize related work around a unified provenance perspective that connects retrieval grounding, claim support, tool-use safety, memory lineage, observability, debugging, audit, and recovery. We introduce a taxonomy covering trace sources, evidence and execution units, provenance relations, tracing granularity and timing, representation forms, and trust functions. We review key methodological directions, including provenance representation, evidence attribution, tool-use provenance, runtime guardrails, provenance-bearing memory, trace-based observability, and failure diagnosis. We also map existing benchmarks, datasets, and evaluation metrics to provenance-related capabilities, and discuss how evaluation can move from final-answer correctness toward process-level accountability. Finally, we outline open challenges, including unified trace schemas, claim-level and semantic provenance, provenance-aware safety mechanisms, realistic execution-trace benchmarks, recovery-oriented evaluation, and privacy-aware audit infrastructure.
M3S-Net: Multimodal Feature Fusion Network Based on Multi-scale Data for Ultra-short-term PV Power Forecasting
Feb 23, 2026The inherent intermittency and high-frequency variability of solar irradiance, particularly during rapid cloud advection, present significant stability challenges to high-penetration photovoltaic grids. Although multimodal forecasting has emerged as a viable mitigation strategy, existing architectures predominantly rely on shallow feature concatenation and binary cloud segmentation, thereby failing to capture the fine-grained optical features of clouds and the complex spatiotemporal coupling between visual and meteorological modalities. To bridge this gap, this paper proposes M3S-Net, a novel multimodal feature fusion network based on multi-scale data for ultra-short-term PV power forecasting. First, a multi-scale partial channel selection network leverages partial convolutions to explicitly isolate the boundary features of optically thin clouds, effectively transcending the precision limitations of coarse-grained binary masking. Second, a multi-scale sequence to image analysis network employs Fast Fourier Transform (FFT)-based time-frequency representation to disentangle the complex periodicity of meteorological data across varying time horizons. Crucially, the model incorporates a cross-modal Mamba interaction module featuring a novel dynamic C-matrix swapping mechanism. By exchanging state-space parameters between visual and temporal streams, this design conditions the state evolution of one modality on the context of the other, enabling deep structural coupling with linear computational complexity, thus overcoming the limitations of shallow concatenation. Experimental validation on the newly constructed fine-grained PV power dataset demonstrates that M3S-Net achieves a mean absolute error reduction of 6.2% in 10-minute forecasts compared to state-of-the-art baselines. The dataset and source code will be available at https://github.com/she1110/FGPD.
Fine-Grained Zero-Shot Learning with Attribute-Centric Representations
Dec 13, 2025Recognizing unseen fine-grained categories demands a model that can distinguish subtle visual differences. This is typically achieved by transferring visual-attribute relationships from seen classes to unseen classes. The core challenge is attribute entanglement, where conventional models collapse distinct attributes like color, shape, and texture into a single visual embedding. This causes interference that masks these critical distinctions. The post-hoc solutions of previous work are insufficient, as they operate on representations that are already mixed. We propose a zero-shot learning framework that learns AttributeCentric Representations (ACR) to tackle this problem by imposing attribute disentanglement during representation learning. ACR is achieved with two mixture-of-experts components, including Mixture of Patch Experts (MoPE) and Mixture of Attribute Experts (MoAE). First, MoPE is inserted into the transformer using a dual-level routing mechanism to conditionally dispatch image patches to specialized experts. This ensures coherent attribute families are processed by dedicated experts. Finally, the MoAE head projects these expert-refined features into sparse, partaware attribute maps for robust zero-shot classification. On zero-shot learning benchmark datasets CUB, AwA2, and SUN, our ACR achieves consistent state-of-the-art results.
MPCM-Net: Multi-scale network integrates partial attention convolution with Mamba for ground-based cloud image segmentation
Nov 12, 2025Ground-based cloud image segmentation is a critical research domain for photovoltaic power forecasting. Current deep learning approaches primarily focus on encoder-decoder architectural refinements. However, existing methodologies exhibit several limitations:(1)they rely on dilated convolutions for multi-scale context extraction, lacking the partial feature effectiveness and interoperability of inter-channel;(2)attention-based feature enhancement implementations neglect accuracy-throughput balance; and (3)the decoder modifications fail to establish global interdependencies among hierarchical local features, limiting inference efficiency. To address these challenges, we propose MPCM-Net, a Multi-scale network that integrates Partial attention Convolutions with Mamba architectures to enhance segmentation accuracy and computational efficiency. Specifically, the encoder incorporates MPAC, which comprises:(1)a MPC block with ParCM and ParSM that enables global spatial interaction across multi-scale cloud formations, and (2)a MPA block combining ParAM and ParSM to extract discriminative features with reduced computational complexity. On the decoder side, a M2B is employed to mitigate contextual loss through a SSHD that maintains linear complexity while enabling deep feature aggregation across spatial and scale dimensions. As a key contribution to the community, we also introduce and release a dataset CSRC, which is a clear-label, fine-grained segmentation benchmark designed to overcome the critical limitations of existing public datasets. Extensive experiments on CSRC demonstrate the superior performance of MPCM-Net over state-of-the-art methods, achieving an optimal balance between segmentation accuracy and inference speed. The dataset and source code will be available at https://github.com/she1110/CSRC.
USF-Net: A Unified Spatiotemporal Fusion Network for Ground-Based Remote Sensing Cloud Image Sequence Extrapolation
Nov 12, 2025Ground-based remote sensing cloud image sequence extrapolation is a key research area in the development of photovoltaic power systems. However, existing approaches exhibit several limitations:(1)they primarily rely on static kernels to augment feature information, lacking adaptive mechanisms to extract features at varying resolutions dynamically;(2)temporal guidance is insufficient, leading to suboptimal modeling of long-range spatiotemporal dependencies; and(3)the quadratic computational cost of attention mechanisms is often overlooked, limiting efficiency in practical deployment. To address these challenges, we propose USF-Net, a Unified Spatiotemporal Fusion Network that integrates adaptive large-kernel convolutions and a low-complexity attention mechanism, combining temporal flow information within an encoder-decoder framework. Specifically, the encoder employs three basic layers to extract features. Followed by the USTM, which comprises:(1)a SiB equipped with a SSM that dynamically captures multi-scale contextual information, and(2)a TiB featuring a TAM that effectively models long-range temporal dependencies while maintaining computational efficiency. In addition, a DSM with a TGM is introduced to enable unified modeling of temporally guided spatiotemporal dependencies. On the decoder side, a DUM is employed to address the common "ghosting effect." It utilizes the initial temporal state as an attention operator to preserve critical motion signatures. As a key contribution, we also introduce and release the ASI-CIS dataset. Extensive experiments on ASI-CIS demonstrate that USF-Net significantly outperforms state-of-the-art methods, establishing a superior balance between prediction accuracy and computational efficiency for ground-based cloud extrapolation. The dataset and source code will be available at https://github.com/she1110/ASI-CIS.
Towards Causal Classification: A Comprehensive Study on Graph Neural Networks
Jan 27, 2024The exploration of Graph Neural Networks (GNNs) for processing graph-structured data has expanded, particularly their potential for causal analysis due to their universal approximation capabilities. Anticipated to significantly enhance common graph-based tasks such as classification and prediction, the development of a causally enhanced GNN framework is yet to be thoroughly investigated. Addressing this shortfall, our study delves into nine benchmark graph classification models, testing their strength and versatility across seven datasets spanning three varied domains to discern the impact of causality on the predictive prowess of GNNs. This research offers a detailed assessment of these models, shedding light on their efficiency, and flexibility in different data environments, and highlighting areas needing advancement. Our findings are instrumental in furthering the understanding and practical application of GNNs in diverse datacentric fields
Exploring Causal Learning through Graph Neural Networks: An In-depth Review
Nov 25, 2023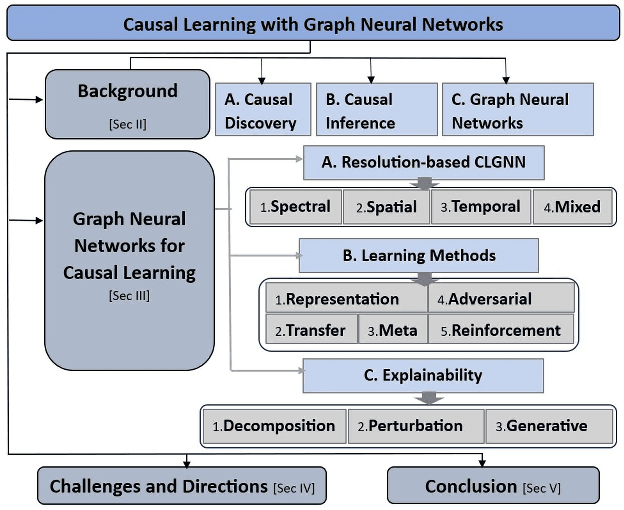
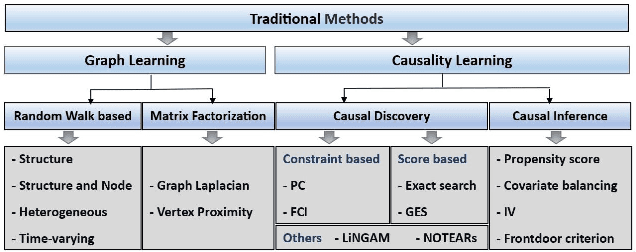
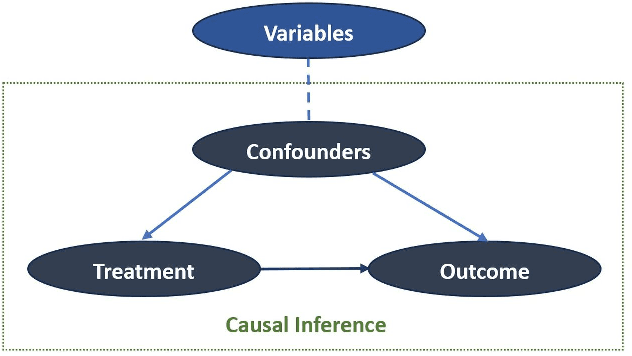
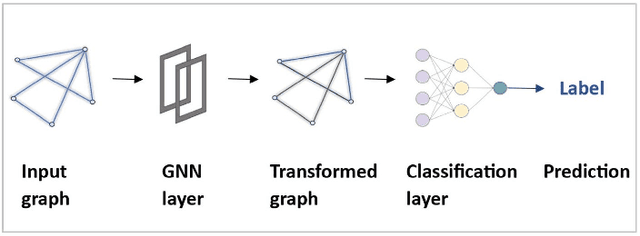
In machine learning, exploring data correlations to predict outcomes is a fundamental task. Recognizing causal relationships embedded within data is pivotal for a comprehensive understanding of system dynamics, the significance of which is paramount in data-driven decision-making processes. Beyond traditional methods, there has been a surge in the use of graph neural networks (GNNs) for causal learning, given their capabilities as universal data approximators. Thus, a thorough review of the advancements in causal learning using GNNs is both relevant and timely. To structure this review, we introduce a novel taxonomy that encompasses various state-of-the-art GNN methods employed in studying causality. GNNs are further categorized based on their applications in the causality domain. We further provide an exhaustive compilation of datasets integral to causal learning with GNNs to serve as a resource for practical study. This review also touches upon the application of causal learning across diverse sectors. We conclude the review with insights into potential challenges and promising avenues for future exploration in this rapidly evolving field of machine learning.
FRAMU: Attention-based Machine Unlearning using Federated Reinforcement Learning
Sep 24, 2023Machine Unlearning is an emerging field that addresses data privacy issues by enabling the removal of private or irrelevant data from the Machine Learning process. Challenges related to privacy and model efficiency arise from the use of outdated, private, and irrelevant data. These issues compromise both the accuracy and the computational efficiency of models in both Machine Learning and Unlearning. To mitigate these challenges, we introduce a novel framework, Attention-based Machine Unlearning using Federated Reinforcement Learning (FRAMU). This framework incorporates adaptive learning mechanisms, privacy preservation techniques, and optimization strategies, making it a well-rounded solution for handling various data sources, either single-modality or multi-modality, while maintaining accuracy and privacy. FRAMU's strength lies in its adaptability to fluctuating data landscapes, its ability to unlearn outdated, private, or irrelevant data, and its support for continual model evolution without compromising privacy. Our experiments, conducted on both single-modality and multi-modality datasets, revealed that FRAMU significantly outperformed baseline models. Additional assessments of convergence behavior and optimization strategies further validate the framework's utility in federated learning applications. Overall, FRAMU advances Machine Unlearning by offering a robust, privacy-preserving solution that optimizes model performance while also addressing key challenges in dynamic data environments.