 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Informed Surrogates for Navigating Power-Performance Trade-offs in HPC
Jan 21, 2026High-Performance Computing (HPC) schedulers must balance user performance with facility-wide resource constraints. The task boils down to selecting the optimal number of nodes for a given job. We present a surrogate-assisted multi-objective Bayesian optimization (MOBO) framework to automate this complex decision. Our core hypothesis is that surrogate models informed by attention-based embeddings of job telemetry can capture performance dynamics more effectively than standard regression techniques. We pair this with an intelligent sample acquisition strategy to ensure the approach is data-efficient. On two production HPC datasets, our embedding-informed method consistently identified higher-quality Pareto fronts of runtime-power trade-offs compared to baselines. Furthermore, our intelligent data sampling strategy drastically reduced training costs while improving the stability of the results. To our knowledge, this is the first work to successfully apply embedding-informed surrogates in a MOBO framework to the HPC scheduling problem, jointly optimizing for performance and power on production workloads.
HPC Digital Twins for Evaluating Scheduling Policies, Incentive Structures and their Impact on Power and Cooling
Aug 28, 2025



Schedulers are critical for optimal resource utilization in high-performance computing. Traditional methods to evaluate schedulers are limited to post-deployment analysis, or simulators, which do not model associated infrastructure. In this work, we present the first-of-its-kind integration of scheduling and digital twins in HPC. This enables what-if studies to understand the impact of parameter configurations and scheduling decisions on the physical assets, even before deployment, or regarching changes not easily realizable in production. We (1) provide the first digital twin framework extended with scheduling capabilities, (2) integrate various top-tier HPC systems given their publicly available datasets, (3) implement extensions to integrate external scheduling simulators. Finally, we show how to (4) implement and evaluate incentive structures, as-well-as (5) evaluate machine learning based scheduling, in such novel digital-twin based meta-framework to prototype scheduling. Our work enables what-if scenarios of HPC systems to evaluate sustainability, and the impact on the simulated system.
WANDER: An Explainable Decision-Support Framework for HPC
Jun 04, 2025High-performance computing (HPC) systems expose many interdependent configuration knobs that impact runtime, resource usage, power, and variability. Existing predictive tools model these outcomes, but do not support structured exploration, explanation, or guided reconfiguration. We present WANDER, a decision-support framework that synthesizes alternate configurations using counterfactual analysis aligned with user goals and constraints. We introduce a composite trade-off score that ranks suggestions based on prediction uncertainty, consistency between feature-target relationships using causal models, and similarity between feature distributions against historical data. To our knowledge, WANDER is the first such system to unify prediction, exploration, and explanation for HPC tuning under a common query interface. Across multiple datasets WANDER generates interpretable and trustworthy, human-readable alternatives that guide users to achieve their performance objectives.
On The Role of Prompt Construction In Enhancing Efficacy and Efficiency of LLM-Based Tabular Data Generation
Sep 06, 2024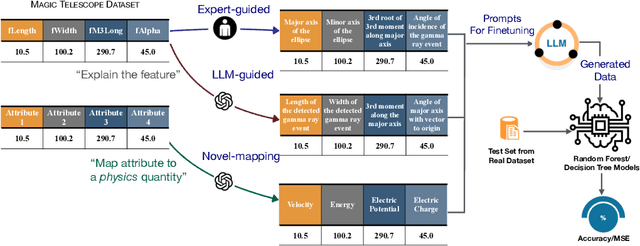
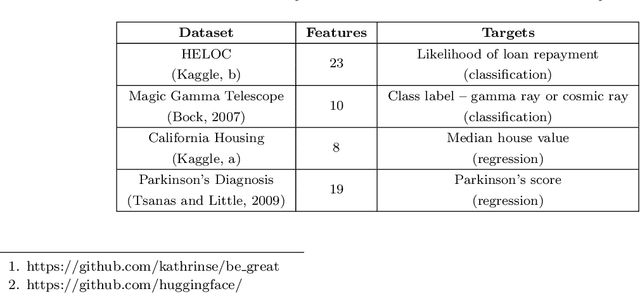
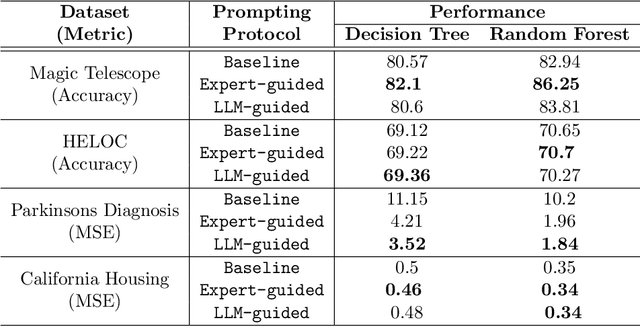
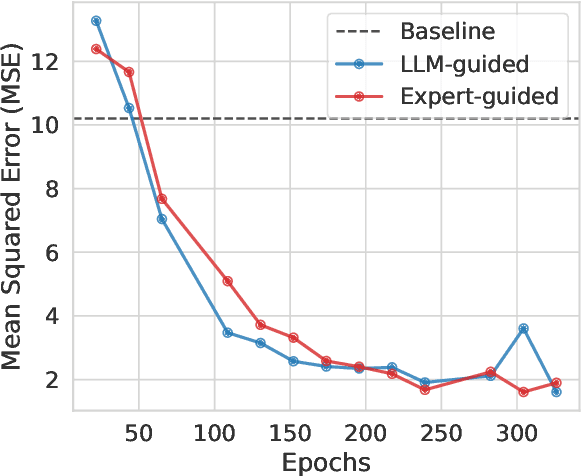
LLM-based data generation for real-world tabular data can be challenged by the lack of sufficient semantic context in feature names used to describe columns. We hypothesize that enriching prompts with domain-specific insights can improve both the quality and efficiency of data generation. To test this hypothesis, we explore three prompt construction protocols: Expert-guided, LLM-guided, and Novel-Mapping. Through empirical studies with the recently proposed GReaT framework, we find that context-enriched prompts lead to significantly improved data generation quality and training efficiency.
Novel Representation Learning Technique using Graphs for Performance Analytics
Jan 19, 2024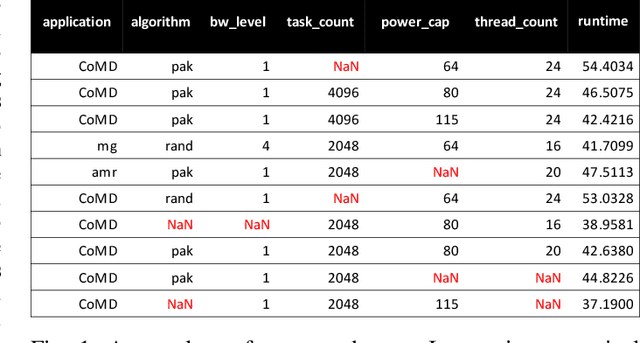
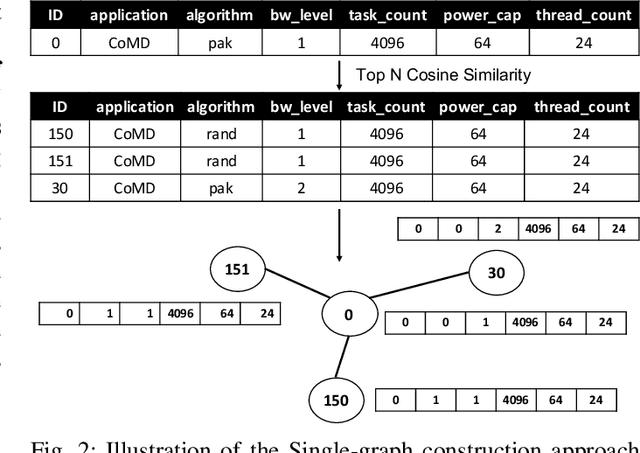
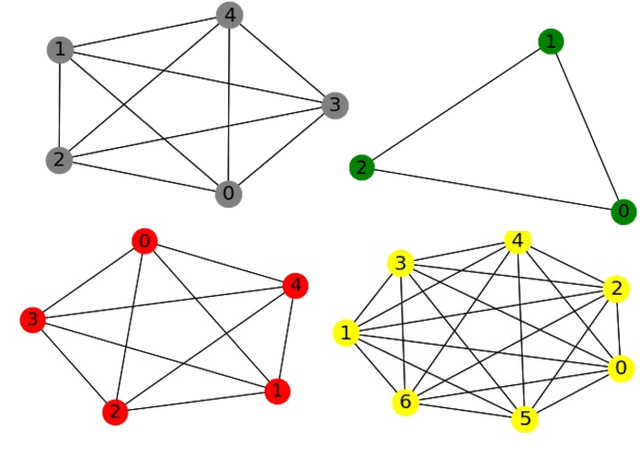
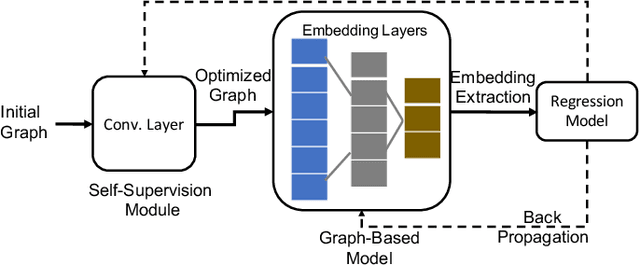
The performance analytics domain in High Performance Computing (HPC) uses tabular data to solve regression problems, such as predicting the execution time. Existing Machine Learning (ML) techniques leverage the correlations among features given tabular datasets, not leveraging the relationships between samples directly. Moreover, since high-quality embeddings from raw features improve the fidelity of the downstream predictive models, existing methods rely on extensive feature engineering and pre-processing steps, costing time and manual effort. To fill these two gaps, we propose a novel idea of transforming tabular performance data into graphs to leverage the advancement of Graph Neural Network-based (GNN) techniques in capturing complex relationships between features and samples. In contrast to other ML application domains, such as social networks, the graph is not given; instead, we need to build it. To address this gap, we propose graph-building methods where nodes represent samples, and the edges are automatically inferred iteratively based on the similarity between the features in the samples. We evaluate the effectiveness of the generated embeddings from GNNs based on how well they make even a simple feed-forward neural network perform for regression tasks compared to other state-of-the-art representation learning techniques. Our evaluation demonstrates that even with up to 25% random missing values for each dataset, our method outperforms commonly used graph and Deep Neural Network (DNN)-based approaches and achieves up to 61.67% & 78.56% improvement in MSE loss over the DNN baseline respectively for HPC dataset and Machine Learning Datasets.
Comparative Code Structure Analysis using Deep Learning for Performance Prediction
Feb 12, 2021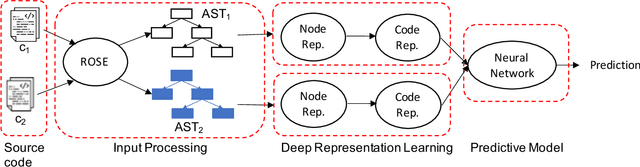
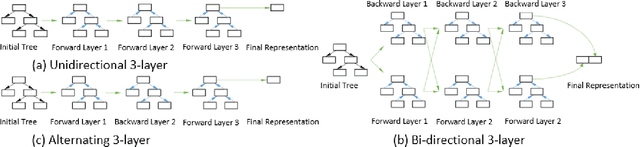
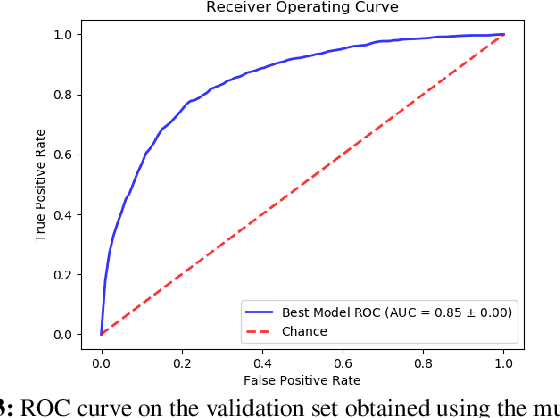
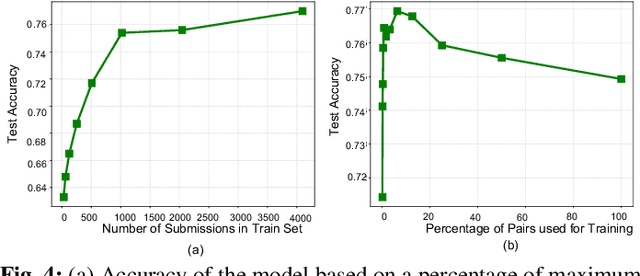
Performance analysis has always been an afterthought during the application development process, focusing on application correctness first. The learning curve of the existing static and dynamic analysis tools are steep, which requires understanding low-level details to interpret the findings for actionable optimizations. Additionally, application performance is a function of an infinite number of unknowns stemming from the application-, runtime-, and interactions between the OS and underlying hardware, making it difficult, if not impossible, to model using any deep learning technique, especially without a large labeled dataset. In this paper, we address both of these problems by presenting a large corpus of a labeled dataset for the community and take a comparative analysis approach to mitigate all unknowns except their source code differences between different correct implementations of the same problem. We put the power of deep learning to the test for automatically extracting information from the hierarchical structure of abstract syntax trees to represent source code. This paper aims to assess the feasibility of using purely static information (e.g., abstract syntax tree or AST) of applications to predict performance change based on the change in code structure. This research will enable performance-aware application development since every version of the application will continue to contribute to the corpora, which will enhance the performance of the model. Our evaluations of several deep embedding learning methods demonstrate that tree-based Long Short-Term Memory (LSTM) models can leverage the hierarchical structure of source-code to discover latent representations and achieve up to 84% (individual problem) and 73% (combined dataset with multiple of problems) accuracy in predicting the change in performance.