Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Role of Prompt Construction In Enhancing Efficacy and Efficiency of LLM-Based Tabular Data Generation
Paper and Code
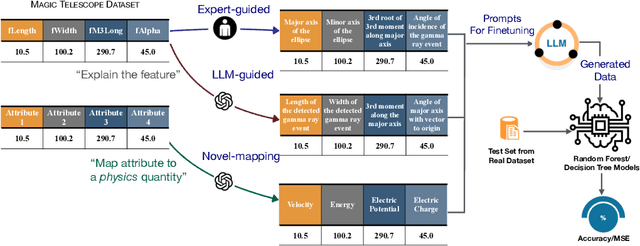
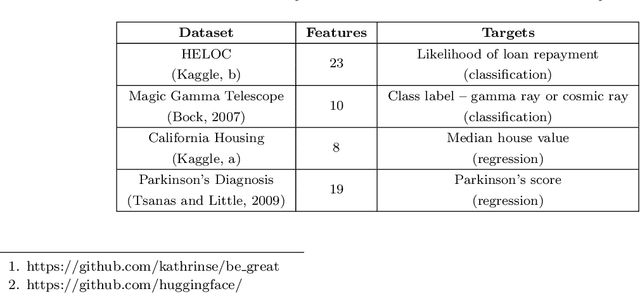
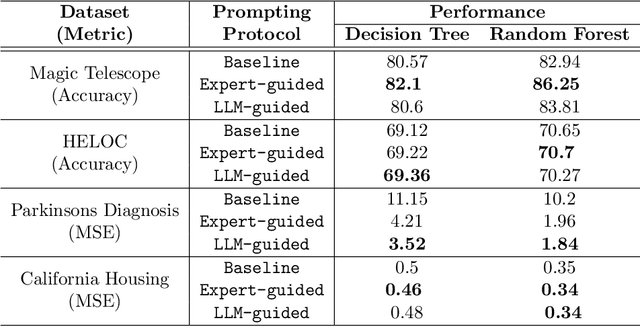
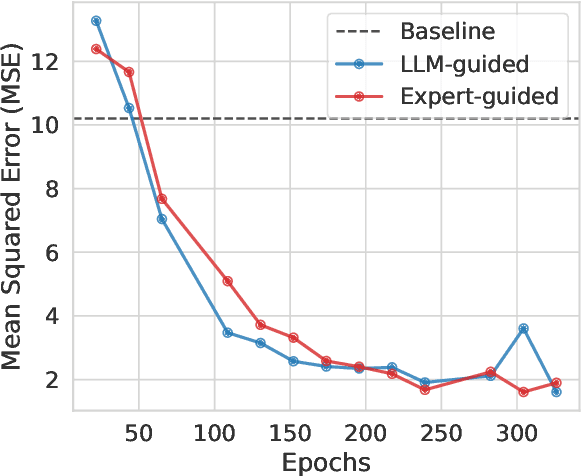
LLM-based data generation for real-world tabular data can be challenged by the lack of sufficient semantic context in feature names used to describe columns. We hypothesize that enriching prompts with domain-specific insights can improve both the quality and efficiency of data generation. To test this hypothesis, we explore three prompt construction protocols: Expert-guided, LLM-guided, and Novel-Mapping. Through empirical studies with the recently proposed GReaT framework, we find that context-enriched prompts lead to significantly improved data generation quality and training efficiency.
View paper on