 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Informed Surrogates for Navigating Power-Performance Trade-offs in HPC
Jan 21, 2026High-Performance Computing (HPC) schedulers must balance user performance with facility-wide resource constraints. The task boils down to selecting the optimal number of nodes for a given job. We present a surrogate-assisted multi-objective Bayesian optimization (MOBO) framework to automate this complex decision. Our core hypothesis is that surrogate models informed by attention-based embeddings of job telemetry can capture performance dynamics more effectively than standard regression techniques. We pair this with an intelligent sample acquisition strategy to ensure the approach is data-efficient. On two production HPC datasets, our embedding-informed method consistently identified higher-quality Pareto fronts of runtime-power trade-offs compared to baselines. Furthermore, our intelligent data sampling strategy drastically reduced training costs while improving the stability of the results. To our knowledge, this is the first work to successfully apply embedding-informed surrogates in a MOBO framework to the HPC scheduling problem, jointly optimizing for performance and power on production workloads.
WANDER: An Explainable Decision-Support Framework for HPC
Jun 04, 2025High-performance computing (HPC) systems expose many interdependent configuration knobs that impact runtime, resource usage, power, and variability. Existing predictive tools model these outcomes, but do not support structured exploration, explanation, or guided reconfiguration. We present WANDER, a decision-support framework that synthesizes alternate configurations using counterfactual analysis aligned with user goals and constraints. We introduce a composite trade-off score that ranks suggestions based on prediction uncertainty, consistency between feature-target relationships using causal models, and similarity between feature distributions against historical data. To our knowledge, WANDER is the first such system to unify prediction, exploration, and explanation for HPC tuning under a common query interface. Across multiple datasets WANDER generates interpretable and trustworthy, human-readable alternatives that guide users to achieve their performance objectives.
On The Role of Prompt Construction In Enhancing Efficacy and Efficiency of LLM-Based Tabular Data Generation
Sep 06, 2024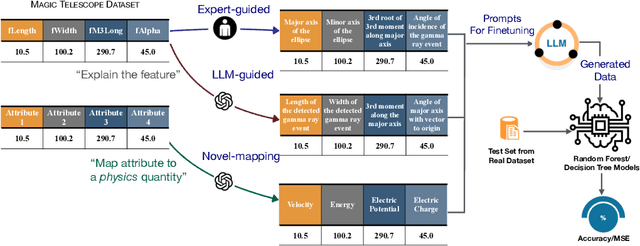
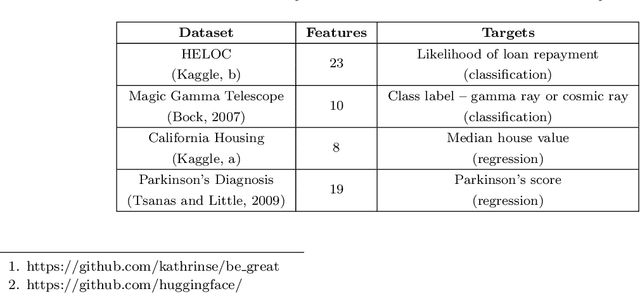
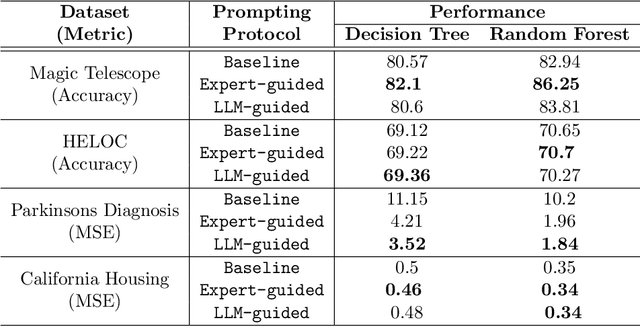
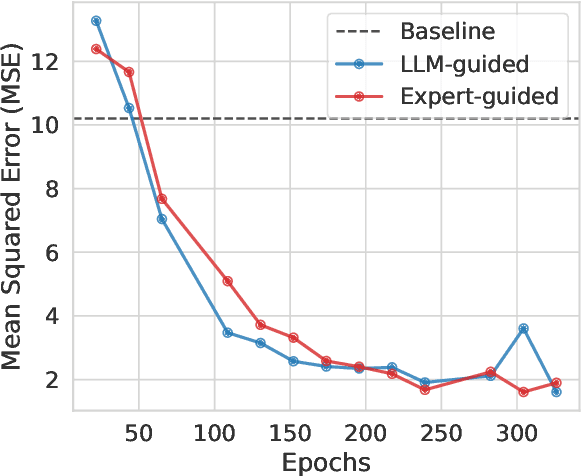
LLM-based data generation for real-world tabular data can be challenged by the lack of sufficient semantic context in feature names used to describe columns. We hypothesize that enriching prompts with domain-specific insights can improve both the quality and efficiency of data generation. To test this hypothesis, we explore three prompt construction protocols: Expert-guided, LLM-guided, and Novel-Mapping. Through empirical studies with the recently proposed GReaT framework, we find that context-enriched prompts lead to significantly improved data generation quality and training efficiency.