 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWANDER: An Explainable Decision-Support Framework for HPC
Jun 04, 2025High-performance computing (HPC) systems expose many interdependent configuration knobs that impact runtime, resource usage, power, and variability. Existing predictive tools model these outcomes, but do not support structured exploration, explanation, or guided reconfiguration. We present WANDER, a decision-support framework that synthesizes alternate configurations using counterfactual analysis aligned with user goals and constraints. We introduce a composite trade-off score that ranks suggestions based on prediction uncertainty, consistency between feature-target relationships using causal models, and similarity between feature distributions against historical data. To our knowledge, WANDER is the first such system to unify prediction, exploration, and explanation for HPC tuning under a common query interface. Across multiple datasets WANDER generates interpretable and trustworthy, human-readable alternatives that guide users to achieve their performance objectives.
Novel Representation Learning Technique using Graphs for Performance Analytics
Jan 19, 2024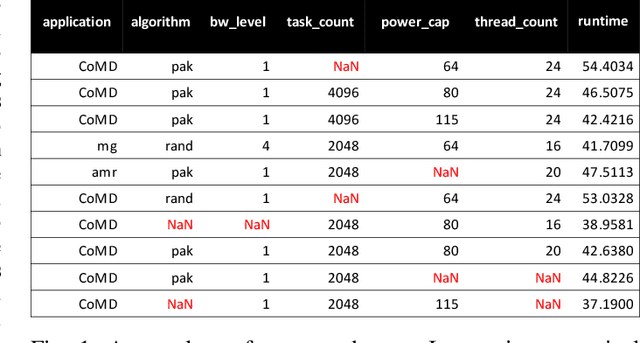
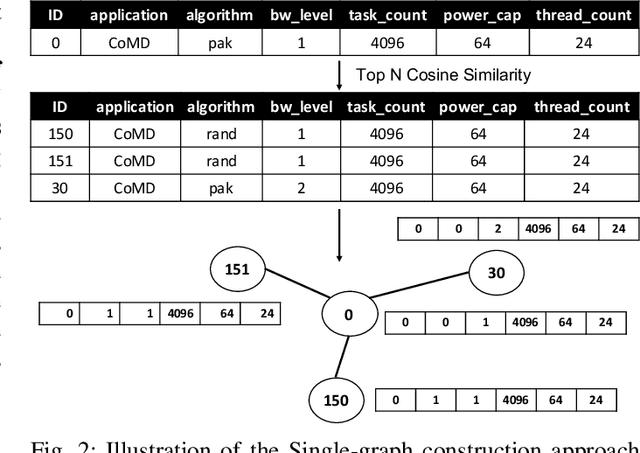
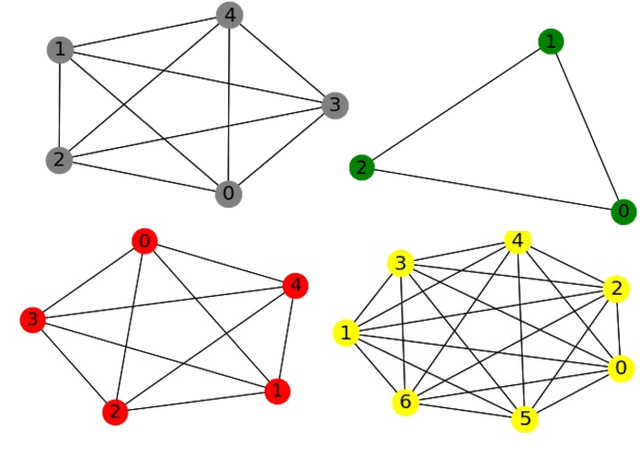
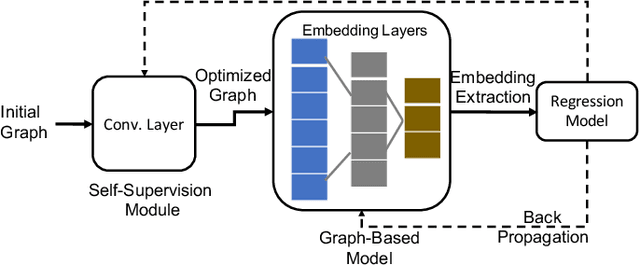
The performance analytics domain in High Performance Computing (HPC) uses tabular data to solve regression problems, such as predicting the execution time. Existing Machine Learning (ML) techniques leverage the correlations among features given tabular datasets, not leveraging the relationships between samples directly. Moreover, since high-quality embeddings from raw features improve the fidelity of the downstream predictive models, existing methods rely on extensive feature engineering and pre-processing steps, costing time and manual effort. To fill these two gaps, we propose a novel idea of transforming tabular performance data into graphs to leverage the advancement of Graph Neural Network-based (GNN) techniques in capturing complex relationships between features and samples. In contrast to other ML application domains, such as social networks, the graph is not given; instead, we need to build it. To address this gap, we propose graph-building methods where nodes represent samples, and the edges are automatically inferred iteratively based on the similarity between the features in the samples. We evaluate the effectiveness of the generated embeddings from GNNs based on how well they make even a simple feed-forward neural network perform for regression tasks compared to other state-of-the-art representation learning techniques. Our evaluation demonstrates that even with up to 25% random missing values for each dataset, our method outperforms commonly used graph and Deep Neural Network (DNN)-based approaches and achieves up to 61.67% & 78.56% improvement in MSE loss over the DNN baseline respectively for HPC dataset and Machine Learning Datasets.