 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Code Structure Analysis using Deep Learning for Performance Prediction
Feb 12, 2021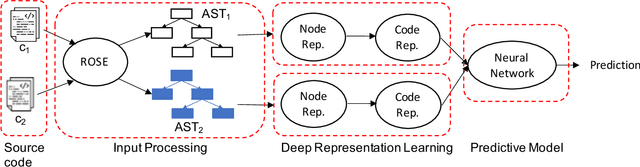
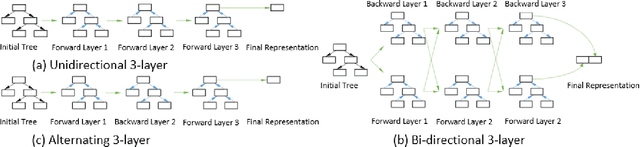
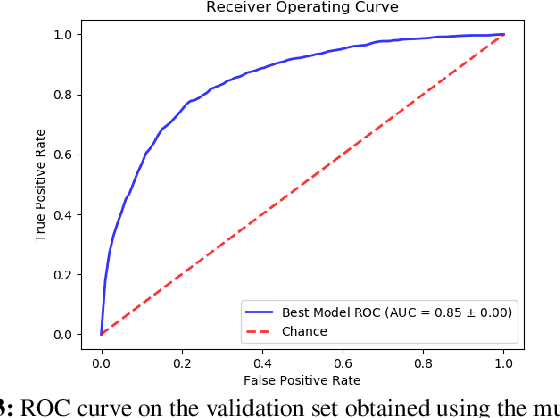
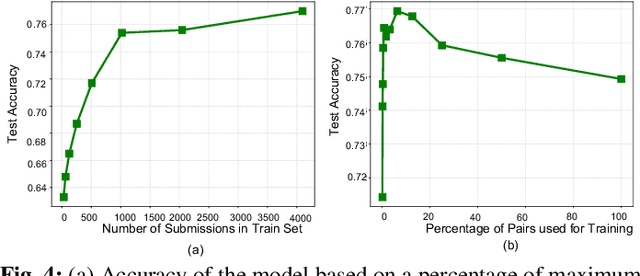
Performance analysis has always been an afterthought during the application development process, focusing on application correctness first. The learning curve of the existing static and dynamic analysis tools are steep, which requires understanding low-level details to interpret the findings for actionable optimizations. Additionally, application performance is a function of an infinite number of unknowns stemming from the application-, runtime-, and interactions between the OS and underlying hardware, making it difficult, if not impossible, to model using any deep learning technique, especially without a large labeled dataset. In this paper, we address both of these problems by presenting a large corpus of a labeled dataset for the community and take a comparative analysis approach to mitigate all unknowns except their source code differences between different correct implementations of the same problem. We put the power of deep learning to the test for automatically extracting information from the hierarchical structure of abstract syntax trees to represent source code. This paper aims to assess the feasibility of using purely static information (e.g., abstract syntax tree or AST) of applications to predict performance change based on the change in code structure. This research will enable performance-aware application development since every version of the application will continue to contribute to the corpora, which will enhance the performance of the model. Our evaluations of several deep embedding learning methods demonstrate that tree-based Long Short-Term Memory (LSTM) models can leverage the hierarchical structure of source-code to discover latent representations and achieve up to 84% (individual problem) and 73% (combined dataset with multiple of problems) accuracy in predicting the change in performance.