 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFU: Enforcing Federated Unlearning via Functional Encryption
Aug 11, 2025Federated unlearning (FU) algorithms allow clients in federated settings to exercise their ''right to be forgotten'' by removing the influence of their data from a collaboratively trained model. Existing FU methods maintain data privacy by performing unlearning locally on the client-side and sending targeted updates to the server without exposing forgotten data; yet they often rely on server-side cooperation, revealing the client's intent and identity without enforcement guarantees - compromising autonomy and unlearning privacy. In this work, we propose EFU (Enforced Federated Unlearning), a cryptographically enforced FU framework that enables clients to initiate unlearning while concealing its occurrence from the server. Specifically, EFU leverages functional encryption to bind encrypted updates to specific aggregation functions, ensuring the server can neither perform unauthorized computations nor detect or skip unlearning requests. To further mask behavioral and parameter shifts in the aggregated model, we incorporate auxiliary unlearning losses based on adversarial examples and parameter importance regularization. Extensive experiments show that EFU achieves near-random accuracy on forgotten data while maintaining performance comparable to full retraining across datasets and neural architectures - all while concealing unlearning intent from the server. Furthermore, we demonstrate that EFU is agnostic to the underlying unlearning algorithm, enabling secure, function-hiding, and verifiable unlearning for any client-side FU mechanism that issues targeted updates.
Many-Task Federated Fine-Tuning via Unified Task Vectors
Feb 10, 2025



Federated Learning (FL) traditionally assumes homogeneous client tasks; however, in real-world scenarios, clients often specialize in diverse tasks, introducing task heterogeneity. To address this challenge, Many-Task FL (MaT-FL) has emerged, enabling clients to collaborate effectively despite task diversity. Existing MaT-FL approaches rely on client grouping or personalized layers, requiring the server to manage individual models and failing to account for clients handling multiple tasks. We propose MaTU, a MaT-FL approach that enables joint learning of task vectors across clients, eliminating the need for clustering or client-specific weight storage at the server. Our method introduces a novel aggregation mechanism that determines task similarity based on the direction of clients task vectors and constructs a unified task vector encapsulating all tasks. To address task-specific requirements, we augment the unified task vector with lightweight modulators that facilitate knowledge transfer among related tasks while disentangling dissimilar ones. Evaluated across 30 datasets, MaTU achieves superior performance over state-of-the-art MaT-FL approaches, with results comparable to per-task fine-tuning, while delivering significant communication savings.
EncCluster: Scalable Functional Encryption in Federated Learning through Weight Clustering and Probabilistic Filters
Jun 13, 2024Federated Learning (FL) enables model training across decentralized devices by communicating solely local model updates to an aggregation server. Although such limited data sharing makes FL more secure than centralized approached, FL remains vulnerable to inference attacks during model update transmissions. Existing secure aggregation approaches rely on differential privacy or cryptographic schemes like Functional Encryption (FE) to safeguard individual client data. However, such strategies can reduce performance or introduce unacceptable computational and communication overheads on clients running on edge devices with limited resources. In this work, we present EncCluster, a novel method that integrates model compression through weight clustering with recent decentralized FE and privacy-enhancing data encoding using probabilistic filters to deliver strong privacy guarantees in FL without affecting model performance or adding unnecessary burdens to clients. We performed a comprehensive evaluation, spanning various datasets and architectures, to demonstrate EncCluster's scalability across encryption levels. Our findings reveal that EncCluster significantly reduces communication costs - below even conventional FedAvg - and accelerates encryption by more than four times over all baselines; at the same time, it maintains high model accuracy and enhanced privacy assurances.
Communication-Efficient Federated Learning through Adaptive Weight Clustering and Server-Side Distillation
Jan 29, 2024



Federated Learning (FL) is a promising technique for the collaborative training of deep neural networks across multiple devices while preserving data privacy. Despite its potential benefits, FL is hindered by excessive communication costs due to repeated server-client communication during training. To address this challenge, model compression techniques, such as sparsification and weight clustering are applied, which often require modifying the underlying model aggregation schemes or involve cumbersome hyperparameter tuning, with the latter not only adjusts the model's compression rate but also limits model's potential for continuous improvement over growing data. In this paper, we propose FedCompress, a novel approach that combines dynamic weight clustering and server-side knowledge distillation to reduce communication costs while learning highly generalizable models. Through a comprehensive evaluation on diverse public datasets, we demonstrate the efficacy of our approach compared to baselines in terms of communication costs and inference speed. We will make our implementation public upon acceptance.
FedCode: Communication-Efficient Federated Learning via Transferring Codebooks
Nov 15, 2023Federated Learning (FL) is a distributed machine learning paradigm that enables learning models from decentralized local data. While FL offers appealing properties for clients' data privacy, it imposes high communication burdens for exchanging model weights between a server and the clients. Existing approaches rely on model compression techniques, such as pruning and weight clustering to tackle this. However, transmitting the entire set of weight updates at each federated round, even in a compressed format, limits the potential for a substantial reduction in communication volume. We propose FedCode where clients transmit only codebooks, i.e., the cluster centers of updated model weight values. To ensure a smooth learning curve and proper calibration of clusters between the server and the clients, FedCode periodically transfers model weights after multiple rounds of solely communicating codebooks. This results in a significant reduction in communication volume between clients and the server in both directions, without imposing significant computational overhead on the clients or leading to major performance degradation of the models. We evaluate the effectiveness of FedCode using various publicly available datasets with ResNet-20 and MobileNet backbone model architectures. Our evaluations demonstrate a 12.2-fold data transmission reduction on average while maintaining a comparable model performance with an average accuracy loss of 1.3% compared to FedAvg. Further validation of FedCode performance under non-IID data distributions showcased an average accuracy loss of 2.0% compared to FedAvg while achieving approximately a 12.7-fold data transmission reduction.
Intelligent Blockage Recognition using Cellular mmWave Beamforming Data: Feasibility Study
Oct 30, 2022
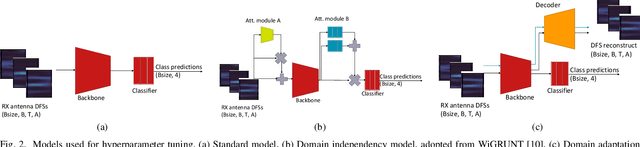


Joint Communication and Sensing (JCAS) is envisioned for 6G cellular networks, where sensing the operation environment, especially in presence of humans, is as important as the high-speed wireless connectivity. Sensing, and subsequently recognizing blockage types, is an initial step towards signal blockage avoidance. In this context, we investigate the feasibility of using human motion recognition as a surrogate task for blockage type recognition through a set of hypothesis validation experiments using both qualitative and quantitative analysis (visual inspection and hyperparameter tuning of deep learning (DL) models, respectively). A surrogate task is useful for DL model testing and/or pre-training, thereby requiring a low amount of data to be collected from the eventual JCAS environment. Therefore, we collect and use a small dataset from a 26 GHz cellular multi-user communication device with hybrid beamforming. The data is converted into Doppler Frequency Spectrum (DFS) and used for hypothesis validations. Our research shows that (i) the presence of domain shift between data used for learning and inference requires use of DL models that can successfully handle it, (ii) DFS input data dilution to increase dataset volume should be avoided, (iii) a small volume of input data is not enough for reasonable inference performance, (iv) higher sensing resolution, causing lower sensitivity, should be handled by doing more activities/gestures per frame and lowering sampling rate, and (v) a higher reported sampling rate to STFT during pre-processing may increase performance, but should always be tested on a per learning task basis.
Federated Learning with Noisy Labels
Aug 19, 2022
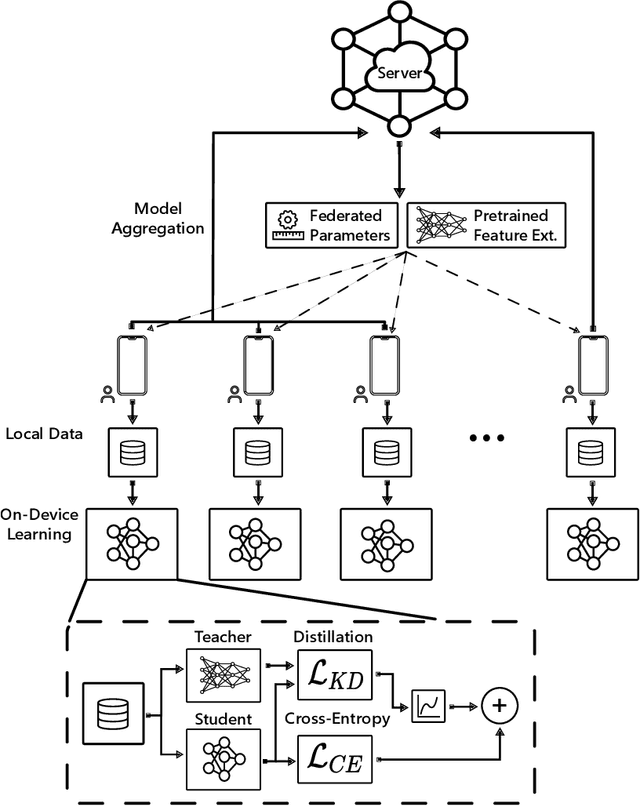
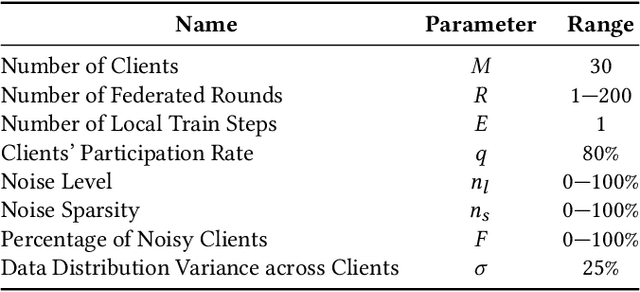
Federated Learning (FL) is a distributed machine learning paradigm that enables learning models from decentralized private datasets, where the labeling effort is entrusted to the clients. While most existing FL approaches assume high-quality labels are readily available on users' devices; in reality, label noise can naturally occur in FL and follows a non-i.i.d. distribution among clients. Due to the non-iid-ness challenges, existing state-of-the-art centralized approaches exhibit unsatisfactory performance, while previous FL studies rely on data exchange or repeated server-side aid to improve model's performance. Here, we propose FedLN, a framework to deal with label noise across different FL training stages; namely, FL initialization, on-device model training, and server model aggregation. Specifically, FedLN computes per-client noise-level estimation in a single federated round and improves the models' performance by correcting (or limiting the effect of) noisy samples. Extensive experiments on various publicly available vision and audio datasets demonstrate a 24% improvement on average compared to other existing methods for a label noise level of 70%. We further validate the efficiency of FedLN in human-annotated real-world noisy datasets and report a 9% increase on average in models' recognition rate, highlighting that FedLN can be useful for improving FL services provided to everyday users.
Privacy-preserving Speech Emotion Recognition through Semi-Supervised Federated Learning
Feb 05, 2022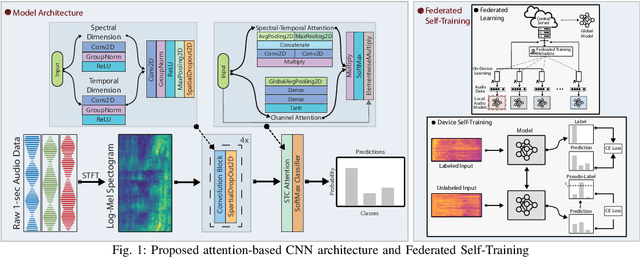
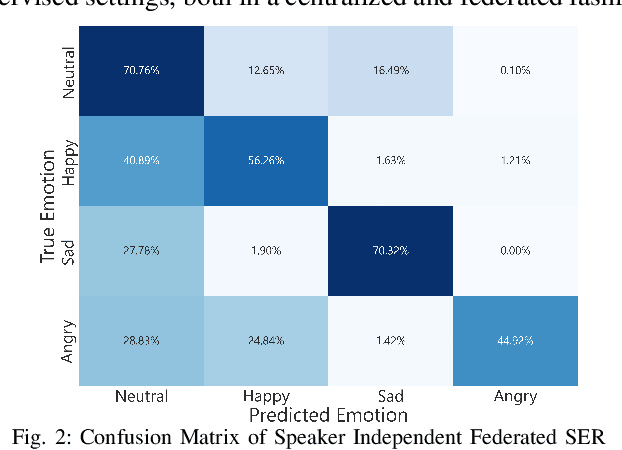
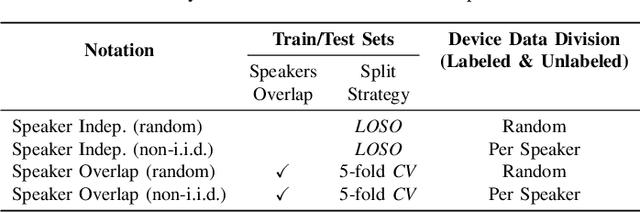
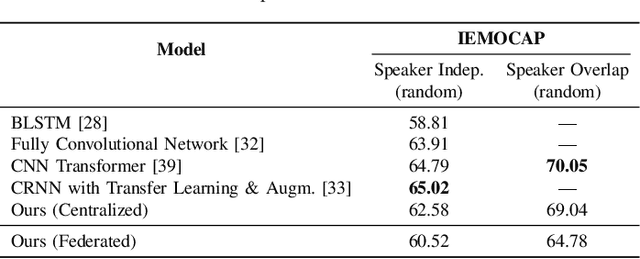
Speech Emotion Recognition (SER) refers to the recognition of human emotions from natural speech. If done accurately, it can offer a number of benefits in building human-centered context-aware intelligent systems. Existing SER approaches are largely centralized, without considering users' privacy. Federated Learning (FL) is a distributed machine learning paradigm dealing with decentralization of privacy-sensitive personal data. In this paper, we present a privacy-preserving and data-efficient SER approach by utilizing the concept of FL. To the best of our knowledge, this is the first federated SER approach, which utilizes self-training learning in conjunction with federated learning to exploit both labeled and unlabeled on-device data. Our experimental evaluations on the IEMOCAP dataset shows that our federated approach can learn generalizable SER models even under low availability of data labels and highly non-i.i.d. distributions. We show that our approach with as few as 10% labeled data, on average, can improve the recognition rate by 8.67% compared to the fully-supervised federated counterparts.
Federated Self-Training for Semi-Supervised Audio Recognition
Jul 14, 2021


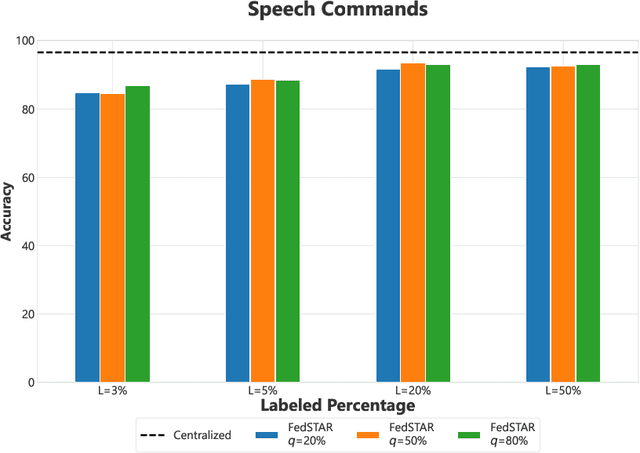
Federated Learning is a distributed machine learning paradigm dealing with decentralized and personal datasets. Since data reside on devices like smartphones and virtual assistants, labeling is entrusted to the clients, or labels are extracted in an automated way. Specifically, in the case of audio data, acquiring semantic annotations can be prohibitively expensive and time-consuming. As a result, an abundance of audio data remains unlabeled and unexploited on users' devices. Most existing federated learning approaches focus on supervised learning without harnessing the unlabeled data. In this work, we study the problem of semi-supervised learning of audio models via self-training in conjunction with federated learning. We propose FedSTAR to exploit large-scale on-device unlabeled data to improve the generalization of audio recognition models. We further demonstrate that self-supervised pre-trained models can accelerate the training of on-device models, significantly improving convergence to within fewer training rounds. We conduct experiments on diverse public audio classification datasets and investigate the performance of our models under varying percentages of labeled and unlabeled data. Notably, we show that with as little as 3% labeled data available, FedSTAR on average can improve the recognition rate by 13.28% compared to the fully supervised federated model.
Millimeter Wave Sensing: A Review of Application Pipelines and Building Blocks
Dec 26, 2020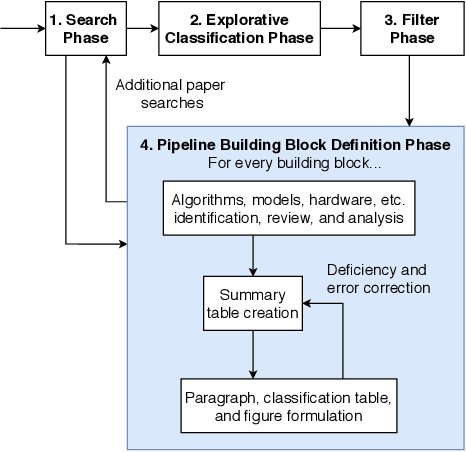
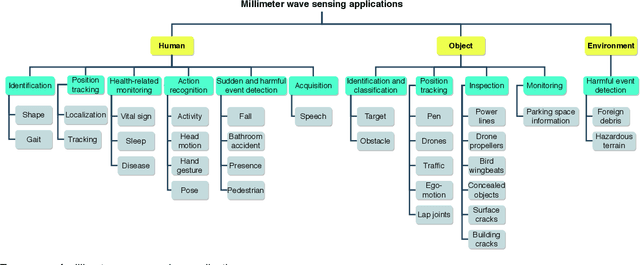
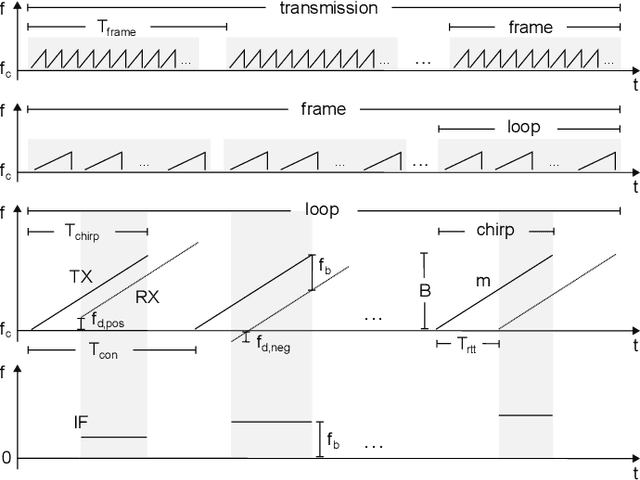

The increasing bandwidth requirement of new wireless applications has lead to standardization of the millimeter wave spectrum for high-speed wireless communication. The millimeter wave spectrum is part of 5G and covers frequencies between 30 and 300 GHz corresponding to wavelengths ranging from 10 to 1 mm. Although millimeter wave is often considered as a communication medium, it has also proved to be an excellent 'sensor', thanks to its narrow beams, operation across a wide bandwidth, and interaction with atmospheric constituents. In this paper, which is to the best of our knowledge the first review that completely covers millimeter wave sensing application pipelines, we provide a comprehensive overview and analysis of different basic application pipeline building blocks, including hardware, algorithms, analytical models, and model evaluation techniques. The review also provides a taxonomy that highlights different millimeter wave sensing application domains. By performing a thorough analysis, complying with the systematic literature review methodology and reviewing 165 papers, we not only extend previous investigations focused only on communication aspects of the millimeter wave technology and using millimeter wave technology for active imaging, but also highlight scientific and technological challenges and trends, and provide a future perspective for applications of millimeter wave as a sensing technology.