 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-preserving Speech Emotion Recognition through Semi-Supervised Federated Learning
Paper and Code
Feb 05, 2022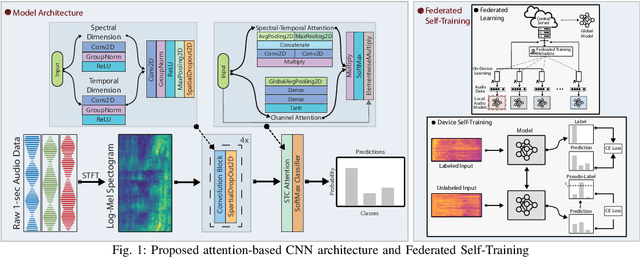
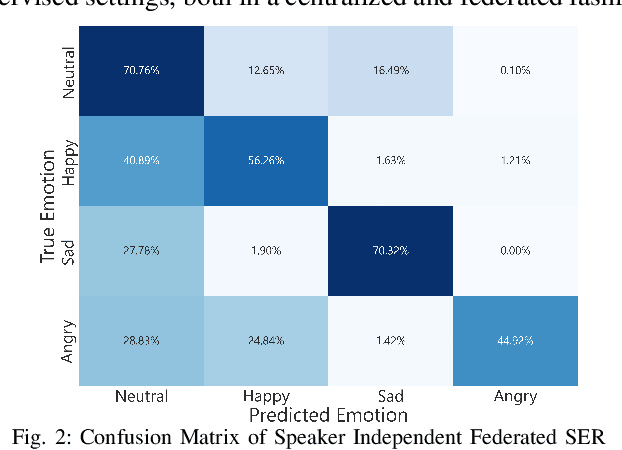
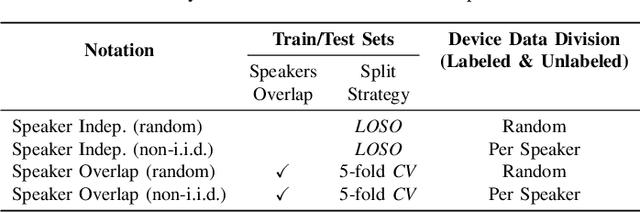
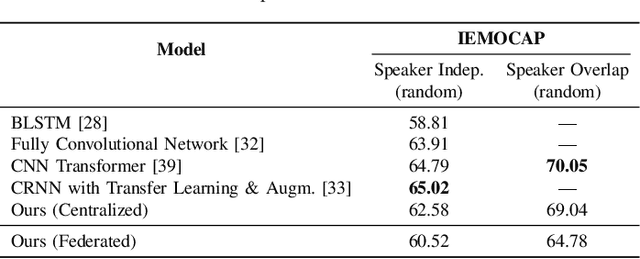
Speech Emotion Recognition (SER) refers to the recognition of human emotions from natural speech. If done accurately, it can offer a number of benefits in building human-centered context-aware intelligent systems. Existing SER approaches are largely centralized, without considering users' privacy. Federated Learning (FL) is a distributed machine learning paradigm dealing with decentralization of privacy-sensitive personal data. In this paper, we present a privacy-preserving and data-efficient SER approach by utilizing the concept of FL. To the best of our knowledge, this is the first federated SER approach, which utilizes self-training learning in conjunction with federated learning to exploit both labeled and unlabeled on-device data. Our experimental evaluations on the IEMOCAP dataset shows that our federated approach can learn generalizable SER models even under low availability of data labels and highly non-i.i.d. distributions. We show that our approach with as few as 10% labeled data, on average, can improve the recognition rate by 8.67% compared to the fully-supervised federated counterparts.