 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFU: Enforcing Federated Unlearning via Functional Encryption
Aug 11, 2025Federated unlearning (FU) algorithms allow clients in federated settings to exercise their ''right to be forgotten'' by removing the influence of their data from a collaboratively trained model. Existing FU methods maintain data privacy by performing unlearning locally on the client-side and sending targeted updates to the server without exposing forgotten data; yet they often rely on server-side cooperation, revealing the client's intent and identity without enforcement guarantees - compromising autonomy and unlearning privacy. In this work, we propose EFU (Enforced Federated Unlearning), a cryptographically enforced FU framework that enables clients to initiate unlearning while concealing its occurrence from the server. Specifically, EFU leverages functional encryption to bind encrypted updates to specific aggregation functions, ensuring the server can neither perform unauthorized computations nor detect or skip unlearning requests. To further mask behavioral and parameter shifts in the aggregated model, we incorporate auxiliary unlearning losses based on adversarial examples and parameter importance regularization. Extensive experiments show that EFU achieves near-random accuracy on forgotten data while maintaining performance comparable to full retraining across datasets and neural architectures - all while concealing unlearning intent from the server. Furthermore, we demonstrate that EFU is agnostic to the underlying unlearning algorithm, enabling secure, function-hiding, and verifiable unlearning for any client-side FU mechanism that issues targeted updates.
Fine-tuning Multimodal Transformers on Edge: A Parallel Split Learning Approach
Feb 10, 2025



Multimodal transformers integrate diverse data types like images, audio, and text, advancing tasks such as audio-visual understanding and image-text retrieval; yet their high parameterization limits deployment on resource-constrained edge devices. Split Learning (SL), which partitions models at a designated cut-layer to offload compute-intensive operations to the server, offers a promising approach for distributed training of multimodal transformers, though its application remains underexplored. We present MPSL, a parallel SL approach for computational efficient fine-tuning of multimodal transformers in a distributed manner, while eliminating label sharing, client synchronization, and per-client sub-model management. MPSL employs lightweight client-side tokenizers and a unified modality-agnostic encoder, allowing flexible adaptation to task-specific needs. Our evaluation across 7 multimodal datasets demonstrates that MPSL matches or outperforms Federated Learning, reduces client-side computations by 250x, and achieves superior scalability in communication cost with model growth. Through extensive analysis, we highlight task suitability, trade-offs, and scenarios where MPSL excels, inspiring further exploration.
Many-Task Federated Fine-Tuning via Unified Task Vectors
Feb 10, 2025



Federated Learning (FL) traditionally assumes homogeneous client tasks; however, in real-world scenarios, clients often specialize in diverse tasks, introducing task heterogeneity. To address this challenge, Many-Task FL (MaT-FL) has emerged, enabling clients to collaborate effectively despite task diversity. Existing MaT-FL approaches rely on client grouping or personalized layers, requiring the server to manage individual models and failing to account for clients handling multiple tasks. We propose MaTU, a MaT-FL approach that enables joint learning of task vectors across clients, eliminating the need for clustering or client-specific weight storage at the server. Our method introduces a novel aggregation mechanism that determines task similarity based on the direction of clients task vectors and constructs a unified task vector encapsulating all tasks. To address task-specific requirements, we augment the unified task vector with lightweight modulators that facilitate knowledge transfer among related tasks while disentangling dissimilar ones. Evaluated across 30 datasets, MaTU achieves superior performance over state-of-the-art MaT-FL approaches, with results comparable to per-task fine-tuning, while delivering significant communication savings.
EncCluster: Scalable Functional Encryption in Federated Learning through Weight Clustering and Probabilistic Filters
Jun 13, 2024Federated Learning (FL) enables model training across decentralized devices by communicating solely local model updates to an aggregation server. Although such limited data sharing makes FL more secure than centralized approached, FL remains vulnerable to inference attacks during model update transmissions. Existing secure aggregation approaches rely on differential privacy or cryptographic schemes like Functional Encryption (FE) to safeguard individual client data. However, such strategies can reduce performance or introduce unacceptable computational and communication overheads on clients running on edge devices with limited resources. In this work, we present EncCluster, a novel method that integrates model compression through weight clustering with recent decentralized FE and privacy-enhancing data encoding using probabilistic filters to deliver strong privacy guarantees in FL without affecting model performance or adding unnecessary burdens to clients. We performed a comprehensive evaluation, spanning various datasets and architectures, to demonstrate EncCluster's scalability across encryption levels. Our findings reveal that EncCluster significantly reduces communication costs - below even conventional FedAvg - and accelerates encryption by more than four times over all baselines; at the same time, it maintains high model accuracy and enhanced privacy assurances.
Communication-Efficient Federated Learning through Adaptive Weight Clustering and Server-Side Distillation
Jan 29, 2024



Federated Learning (FL) is a promising technique for the collaborative training of deep neural networks across multiple devices while preserving data privacy. Despite its potential benefits, FL is hindered by excessive communication costs due to repeated server-client communication during training. To address this challenge, model compression techniques, such as sparsification and weight clustering are applied, which often require modifying the underlying model aggregation schemes or involve cumbersome hyperparameter tuning, with the latter not only adjusts the model's compression rate but also limits model's potential for continuous improvement over growing data. In this paper, we propose FedCompress, a novel approach that combines dynamic weight clustering and server-side knowledge distillation to reduce communication costs while learning highly generalizable models. Through a comprehensive evaluation on diverse public datasets, we demonstrate the efficacy of our approach compared to baselines in terms of communication costs and inference speed. We will make our implementation public upon acceptance.
Federated Fine-Tuning of Foundation Models via Probabilistic Masking
Nov 29, 2023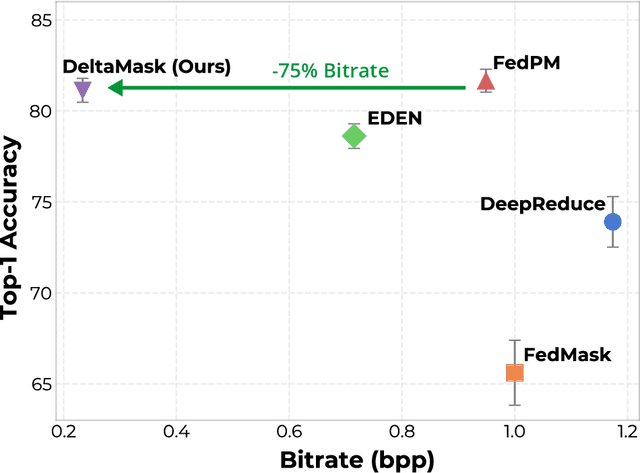

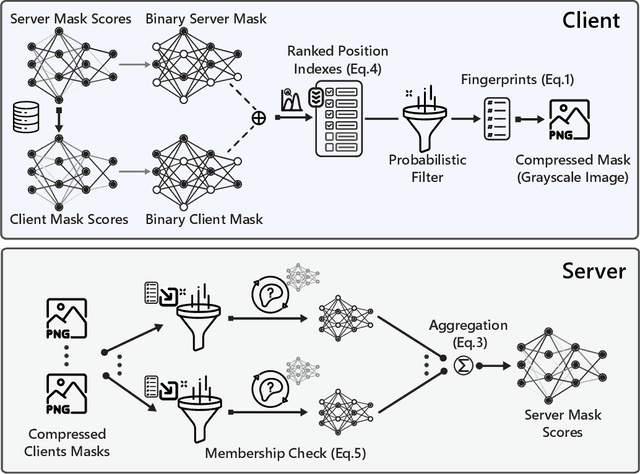

Foundation Models (FMs) have revolutionized machine learning with their adaptability and high performance across tasks; yet, their integration into Federated Learning (FL) is challenging due to substantial communication overhead from their extensive parameterization. Current communication-efficient FL strategies, such as gradient compression, reduce bitrates to around $1$ bit-per-parameter (bpp). However, these approaches fail to harness the characteristics of FMs, with their large number of parameters still posing a challenge to communication efficiency, even at these bitrate regimes. In this work, we present DeltaMask, a novel method that efficiently fine-tunes FMs in FL at an ultra-low bitrate, well below 1 bpp. DeltaMask employs stochastic masking to detect highly effective subnetworks within FMs and leverage stochasticity and sparsity in client masks to compress updates into a compact grayscale image using probabilistic filters, deviating from traditional weight training approaches. Our comprehensive evaluations across various datasets and architectures demonstrate DeltaMask efficiently achieves bitrates as low as 0.09 bpp, enhancing communication efficiency while maintaining FMs performance, as measured on 8 datasets and 5 pre-trained models of various network architectures.
FedCode: Communication-Efficient Federated Learning via Transferring Codebooks
Nov 15, 2023Federated Learning (FL) is a distributed machine learning paradigm that enables learning models from decentralized local data. While FL offers appealing properties for clients' data privacy, it imposes high communication burdens for exchanging model weights between a server and the clients. Existing approaches rely on model compression techniques, such as pruning and weight clustering to tackle this. However, transmitting the entire set of weight updates at each federated round, even in a compressed format, limits the potential for a substantial reduction in communication volume. We propose FedCode where clients transmit only codebooks, i.e., the cluster centers of updated model weight values. To ensure a smooth learning curve and proper calibration of clusters between the server and the clients, FedCode periodically transfers model weights after multiple rounds of solely communicating codebooks. This results in a significant reduction in communication volume between clients and the server in both directions, without imposing significant computational overhead on the clients or leading to major performance degradation of the models. We evaluate the effectiveness of FedCode using various publicly available datasets with ResNet-20 and MobileNet backbone model architectures. Our evaluations demonstrate a 12.2-fold data transmission reduction on average while maintaining a comparable model performance with an average accuracy loss of 1.3% compared to FedAvg. Further validation of FedCode performance under non-IID data distributions showcased an average accuracy loss of 2.0% compared to FedAvg while achieving approximately a 12.7-fold data transmission reduction.
Plug-and-Play Multilingual Few-shot Spoken Words Recognition
May 03, 2023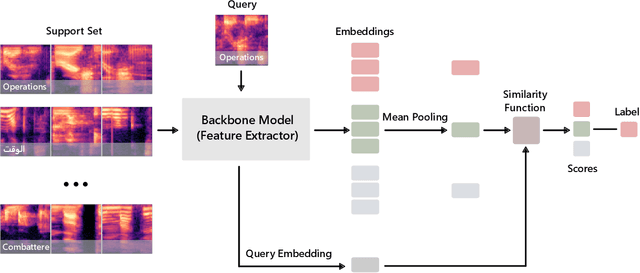

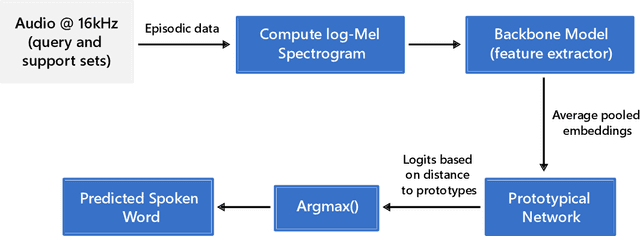
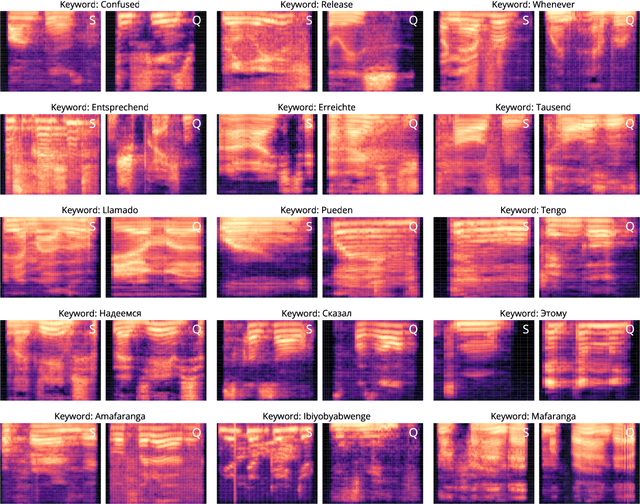
As technology advances and digital devices become prevalent, seamless human-machine communication is increasingly gaining significance. The growing adoption of mobile, wearable, and other Internet of Things (IoT) devices has changed how we interact with these smart devices, making accurate spoken words recognition a crucial component for effective interaction. However, building robust spoken words detection system that can handle novel keywords remains challenging, especially for low-resource languages with limited training data. Here, we propose PLiX, a multilingual and plug-and-play keyword spotting system that leverages few-shot learning to harness massive real-world data and enable the recognition of unseen spoken words at test-time. Our few-shot deep models are learned with millions of one-second audio clips across 20 languages, achieving state-of-the-art performance while being highly efficient. Extensive evaluations show that PLiX can generalize to novel spoken words given as few as just one support example and performs well on unseen languages out of the box. We release models and inference code to serve as a foundation for future research and voice-enabled user interface development for emerging devices.
Federated Learning with Noisy Labels
Aug 19, 2022
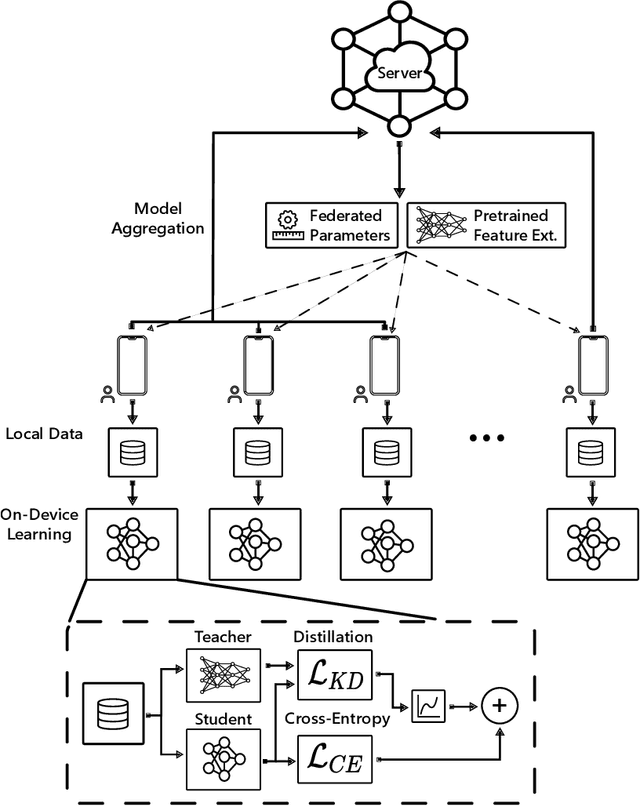
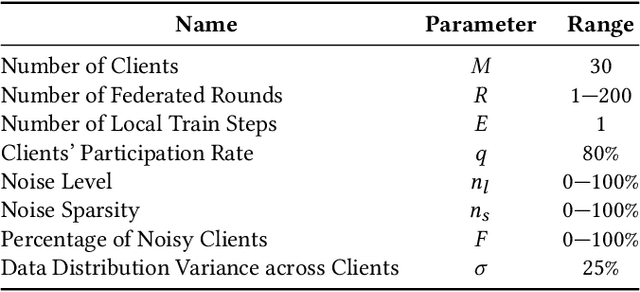
Federated Learning (FL) is a distributed machine learning paradigm that enables learning models from decentralized private datasets, where the labeling effort is entrusted to the clients. While most existing FL approaches assume high-quality labels are readily available on users' devices; in reality, label noise can naturally occur in FL and follows a non-i.i.d. distribution among clients. Due to the non-iid-ness challenges, existing state-of-the-art centralized approaches exhibit unsatisfactory performance, while previous FL studies rely on data exchange or repeated server-side aid to improve model's performance. Here, we propose FedLN, a framework to deal with label noise across different FL training stages; namely, FL initialization, on-device model training, and server model aggregation. Specifically, FedLN computes per-client noise-level estimation in a single federated round and improves the models' performance by correcting (or limiting the effect of) noisy samples. Extensive experiments on various publicly available vision and audio datasets demonstrate a 24% improvement on average compared to other existing methods for a label noise level of 70%. We further validate the efficiency of FedLN in human-annotated real-world noisy datasets and report a 9% increase on average in models' recognition rate, highlighting that FedLN can be useful for improving FL services provided to everyday users.
Privacy-preserving Speech Emotion Recognition through Semi-Supervised Federated Learning
Feb 05, 2022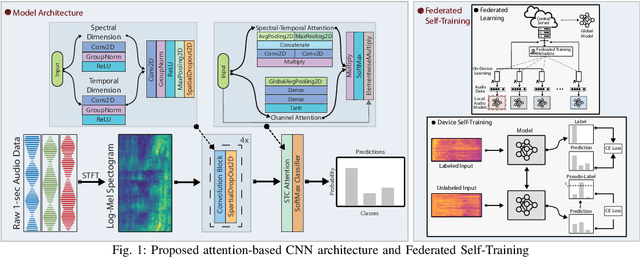
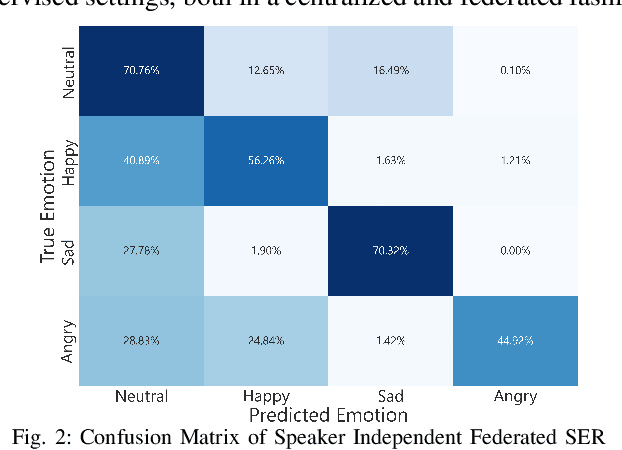
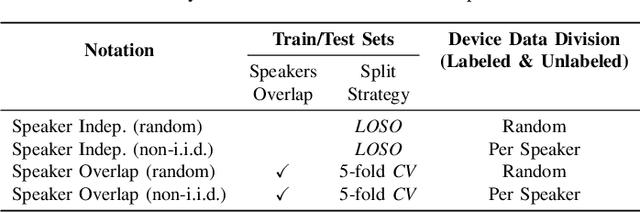
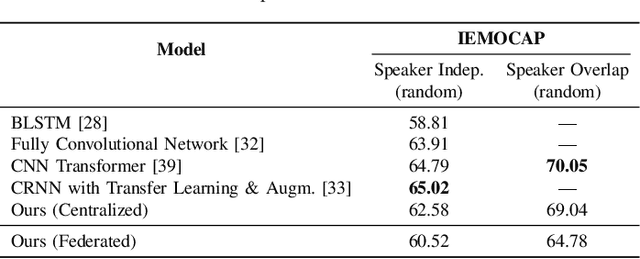
Speech Emotion Recognition (SER) refers to the recognition of human emotions from natural speech. If done accurately, it can offer a number of benefits in building human-centered context-aware intelligent systems. Existing SER approaches are largely centralized, without considering users' privacy. Federated Learning (FL) is a distributed machine learning paradigm dealing with decentralization of privacy-sensitive personal data. In this paper, we present a privacy-preserving and data-efficient SER approach by utilizing the concept of FL. To the best of our knowledge, this is the first federated SER approach, which utilizes self-training learning in conjunction with federated learning to exploit both labeled and unlabeled on-device data. Our experimental evaluations on the IEMOCAP dataset shows that our federated approach can learn generalizable SER models even under low availability of data labels and highly non-i.i.d. distributions. We show that our approach with as few as 10% labeled data, on average, can improve the recognition rate by 8.67% compared to the fully-supervised federated counterparts.