 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Chaotic Dynamics through Second-Order Geometric Supervision
Jun 01, 2026Learning chaotic dynamical systems from data requires more than short-term predictive accuracy: the learned model must preserve the attractor geometry and its invariant statistics. Trajectory (zero-order) and Jacobian (first-order) matching supervise the values and tangent structure of the vector field, but neither constrains how the field bends away from its tangent plane. A model can thus match values and tangents at the supervised states yet curve differently from the truth, remaining locally accurate while drifting toward spurious attractors and distorting long-time statistics. We show that enforcing second-order consistency mitigates these failures, but forming the full Hessian is prohibitive in high dimensions. We propose model-constrained randomized Jacobian matching, which compares the Jacobians of the true and learned vector fields at randomly perturbed inputs. A Taylor expansion shows that the expected randomized Jacobian loss decomposes into the nominal Jacobian mismatch plus a Hessian mismatch scaled by the noise variance, implicitly enforcing second-order consistency at $\mathcal{O}(d^2)$ cost without forming the $\mathcal{O}(d^3)$ Hessian tensor. Using only Jacobian evaluations, the method scales to high dimensions where explicit Hessian matching does not. Numerical experiments confirm that second-order methods are robust. For Lorenz~63, first-order methods produce catastrophic Lyapunov-exponent outliers under minimal temporal supervision, which second-order methods eliminate while recovering the correct attractor. For coupled Lorenz~96, an out-of-distribution forcing sweep separates the methods: all agree up to $F=16$, but beyond $F=18$ only second-order methods preserve the invariant measure and Lyapunov spectrum. On both systems, randomized Jacobian matching performs comparably to explicit Hessian matching at much lower cost.
Generalization Limits of In-Context Operator Networks for Higher-Order Partial Differential Equations
Mar 23, 2026We investigate the generalization capabilities of In-Context Operator Networks (ICONs), a new class of operator networks that build on the principles of in-context learning, for higher-order partial differential equations. We extend previous work by expanding the type and scope of differential equations handled by the foundation model. We demonstrate that while processing complex inputs requires some new computational methods, the underlying machine learning techniques are largely consistent with simpler cases. Our implementation shows that although point-wise accuracy degrades for higher-order problems like the heat equation, the model retains qualitative accuracy in capturing solution dynamics and overall behavior. This demonstrates the model's ability to extrapolate fundamental solution characteristics to problems outside its training regime.
The AI Research Assistant: Promise, Peril, and a Proof of Concept
Feb 26, 2026Can artificial intelligence truly contribute to creative mathematical research, or does it merely automate routine calculations while introducing risks of error? We provide empirical evidence through a detailed case study: the discovery of novel error representations and bounds for Hermite quadrature rules via systematic human-AI collaboration. Working with multiple AI assistants, we extended results beyond what manual work achieved, formulating and proving several theorems with AI assistance. The collaboration revealed both remarkable capabilities and critical limitations. AI excelled at algebraic manipulation, systematic proof exploration, literature synthesis, and LaTeX preparation. However, every step required rigorous human verification, mathematical intuition for problem formulation, and strategic direction. We document the complete research workflow with unusual transparency, revealing patterns in successful human-AI mathematical collaboration and identifying failure modes researchers must anticipate. Our experience suggests that, when used with appropriate skepticism and verification protocols, AI tools can meaningfully accelerate mathematical discovery while demanding careful human oversight and deep domain expertise.
Variance-Reduced Diffusion Sampling via Conditional Score Expectation Identity
Jan 04, 2026We introduce and prove a \textbf{Conditional Score Expectation (CSE)} identity: an exact relation for the marginal score of affine diffusion processes that links scores across time via a conditional expectation under the forward dynamics. Motivated by this identity, we propose a CSE-based statistical estimator for the score using a Self-Normalized Importance Sampling (SNIS) procedure with prior samples and forward noise. We analyze its relationship to the standard Tweedie estimator, proving anti-correlation for Gaussian targets and establishing the same behavior for general targets in the small time-step regime. Exploiting this structure, we derive a variance-minimizing blended score estimator given by a state--time dependent convex combination of the CSE and Tweedie estimators. Numerical experiments show that this optimal-blending estimator reduces variance and improves sample quality for a fixed computational budget compared to either baseline. We further extend the framework to Bayesian inverse problems via likelihood-informed SNIS weights, and demonstrate improved reconstruction quality and sample diversity on high-dimensional image reconstruction tasks and PDE-governed inverse problems.
Topological derivative approach for deep neural network architecture adaptation
Feb 08, 2025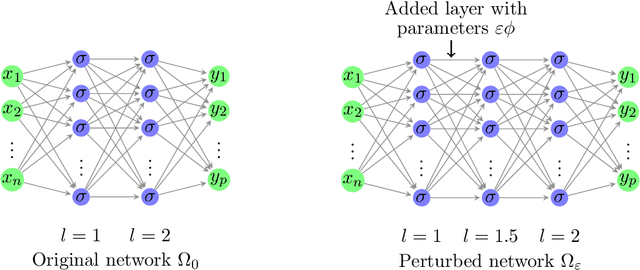

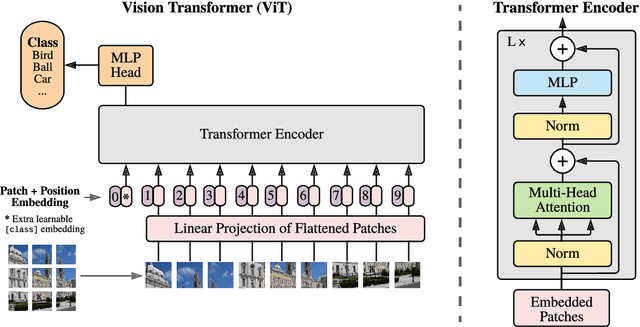
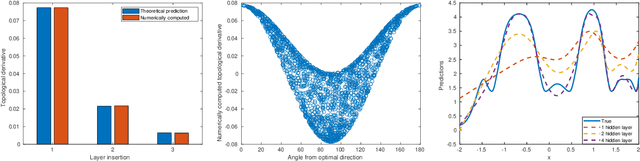
This work presents a novel algorithm for progressively adapting neural network architecture along the depth. In particular, we attempt to address the following questions in a mathematically principled way: i) Where to add a new capacity (layer) during the training process? ii) How to initialize the new capacity? At the heart of our approach are two key ingredients: i) the introduction of a ``shape functional" to be minimized, which depends on neural network topology, and ii) the introduction of a topological derivative of the shape functional with respect to the neural network topology. Using an optimal control viewpoint, we show that the network topological derivative exists under certain conditions, and its closed-form expression is derived. In particular, we explore, for the first time, the connection between the topological derivative from a topology optimization framework with the Hamiltonian from optimal control theory. Further, we show that the optimality condition for the shape functional leads to an eigenvalue problem for deep neural architecture adaptation. Our approach thus determines the most sensitive location along the depth where a new layer needs to be inserted during the training phase and the associated parametric initialization for the newly added layer. We also demonstrate that our layer insertion strategy can be derived from an optimal transport viewpoint as a solution to maximizing a topological derivative in $p$-Wasserstein space, where $p>= 1$. Numerical investigations with fully connected network, convolutional neural network, and vision transformer on various regression and classification problems demonstrate that our proposed approach can outperform an ad-hoc baseline network and other architecture adaptation strategies. Further, we also demonstrate other applications of topological derivative in fields such as transfer learning.
A Constant Velocity Latent Dynamics Approach for Accelerating Simulation of Stiff Nonlinear Systems
Jan 14, 2025



Solving stiff ordinary differential equations (StODEs) requires sophisticated numerical solvers, which are often computationally expensive. In particular, StODE's often cannot be solved with traditional explicit time integration schemes and one must resort to costly implicit methods to compute solutions. On the other hand, state-of-the-art machine learning (ML) based methods such as Neural ODE (NODE) poorly handle the timescale separation of various elements of the solutions to StODEs and require expensive implicit solvers for integration at inference time. In this work, we embark on a different path which involves learning a latent dynamics for StODEs, in which one completely avoids numerical integration. To that end, we consider a constant velocity latent dynamical system whose solution is a sequence of straight lines. Given the initial condition and parameters of the ODE, the encoder networks learn the slope (i.e the constant velocity) and the initial condition for the latent dynamics. In other words, the solution of the original dynamics is encoded into a sequence of straight lines which can be decoded back to retrieve the actual solution as and when required. Another key idea in our approach is a nonlinear transformation of time, which allows for the "stretching/squeezing" of time in the latent space, thereby allowing for varying levels of attention to different temporal regions in the solution. Additionally, we provide a simple universal-approximation-type proof showing that our approach can approximate the solution of stiff nonlinear system on a compact set to any degree of accuracy, {\epsilon}. We show that the dimension of the latent dynamical system in our approach is independent of {\epsilon}. Numerical investigation on prototype StODEs suggest that our method outperforms state-of-the art machine learning approaches for handling StODEs.
TAE: A Model-Constrained Tikhonov Autoencoder Approach for Forward and Inverse Problems
Dec 09, 2024



Efficient real-time solvers for forward and inverse problems are essential in engineering and science applications. Machine learning surrogate models have emerged as promising alternatives to traditional methods, offering substantially reduced computational time. Nevertheless, these models typically demand extensive training datasets to achieve robust generalization across diverse scenarios. While physics-based approaches can partially mitigate this data dependency and ensure physics-interpretable solutions, addressing scarce data regimes remains a challenge. Both purely data-driven and physics-based machine learning approaches demonstrate severe overfitting issues when trained with insufficient data. We propose a novel Tikhonov autoencoder model-constrained framework, called TAE, capable of learning both forward and inverse surrogate models using a single arbitrary observation sample. We develop comprehensive theoretical foundations including forward and inverse inference error bounds for the proposed approach for linear cases. For comparative analysis, we derive equivalent formulations for pure data-driven and model-constrained approach counterparts. At the heart of our approach is a data randomization strategy, which functions as a generative mechanism for exploring the training data space, enabling effective training of both forward and inverse surrogate models from a single observation, while regularizing the learning process. We validate our approach through extensive numerical experiments on two challenging inverse problems: 2D heat conductivity inversion and initial condition reconstruction for time-dependent 2D Navier-Stokes equations. Results demonstrate that TAE achieves accuracy comparable to traditional Tikhonov solvers and numerical forward solvers for both inverse and forward problems, respectively, while delivering orders of magnitude computational speedups.
A model-constrained Discontinuous Galerkin Network (DGNet) for Compressible Euler Equations with Out-of-Distribution Generalization
Sep 27, 2024



Real-time accurate solutions of large-scale complex dynamical systems are critically needed for control, optimization, uncertainty quantification, and decision-making in practical engineering and science applications, particularly in digital twin contexts. In this work, we develop a model-constrained discontinuous Galerkin Network (DGNet) approach, an extension to our previous work [Model-constrained Tagent Slope Learning Approach for Dynamical Systems], for compressible Euler equations with out-of-distribution generalization. The core of DGNet is the synergy of several key strategies: (i) leveraging time integration schemes to capture temporal correlation and taking advantage of neural network speed for computation time reduction; (ii) employing a model-constrained approach to ensure the learned tangent slope satisfies governing equations; (iii) utilizing a GNN-inspired architecture where edges represent Riemann solver surrogate models and nodes represent volume integration correction surrogate models, enabling capturing discontinuity capacity, aliasing error reduction, and mesh discretization generalizability; (iv) implementing the input normalization technique that allows surrogate models to generalize across different initial conditions, boundary conditions, and solution orders; and (v) incorporating a data randomization technique that not only implicitly promotes agreement between surrogate models and true numerical models up to second-order derivatives, ensuring long-term stability and prediction capacity, but also serves as a data generation engine during training, leading to enhanced generalization on unseen data. To validate the effectiveness, stability, and generalizability of our novel DGNet approach, we present comprehensive numerical results for 1D and 2D compressible Euler equation problems.
An autoencoder compression approach for accelerating large-scale inverse problems
Apr 10, 2023PDE-constrained inverse problems are some of the most challenging and computationally demanding problems in computational science today. Fine meshes that are required to accurately compute the PDE solution introduce an enormous number of parameters and require large scale computing resources such as more processors and more memory to solve such systems in a reasonable time. For inverse problems constrained by time dependent PDEs, the adjoint method that is often employed to efficiently compute gradients and higher order derivatives requires solving a time-reversed, so-called adjoint PDE that depends on the forward PDE solution at each timestep. This necessitates the storage of a high dimensional forward solution vector at every timestep. Such a procedure quickly exhausts the available memory resources. Several approaches that trade additional computation for reduced memory footprint have been proposed to mitigate the memory bottleneck, including checkpointing and compression strategies. In this work, we propose a close-to-ideal scalable compression approach using autoencoders to eliminate the need for checkpointing and substantial memory storage, thereby reducing both the time-to-solution and memory requirements. We compare our approach with checkpointing and an off-the-shelf compression approach on an earth-scale ill-posed seismic inverse problem. The results verify the expected close-to-ideal speedup for both the gradient and Hessian-vector product using the proposed autoencoder compression approach. To highlight the usefulness of the proposed approach, we combine the autoencoder compression with the data-informed active subspace (DIAS) prior to show how the DIAS method can be affordably extended to large scale problems without the need of checkpointing and large memory.
Layerwise Sparsifying Training and Sequential Learning Strategy for Neural Architecture Adaptation
Nov 13, 2022This work presents a two-stage framework for progressively developing neural architectures to adapt/ generalize well on a given training data set. In the first stage, a manifold-regularized layerwise sparsifying training approach is adopted where a new layer is added each time and trained independently by freezing parameters in the previous layers. In order to constrain the functions that should be learned by each layer, we employ a sparsity regularization term, manifold regularization term and a physics-informed term. We derive the necessary conditions for trainability of a newly added layer and analyze the role of manifold regularization. In the second stage of the Algorithm, a sequential learning process is adopted where a sequence of small networks is employed to extract information from the residual produced in stage I and thereby making robust and more accurate predictions. Numerical investigations with fully connected network on prototype regression problem, and classification problem demonstrate that the proposed approach can outperform adhoc baseline networks. Further, application to physics-informed neural network problems suggests that the method could be employed for creating interpretable hidden layers in a deep network while outperforming equivalent baseline networks.