 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological derivative approach for deep neural network architecture adaptation
Feb 08, 2025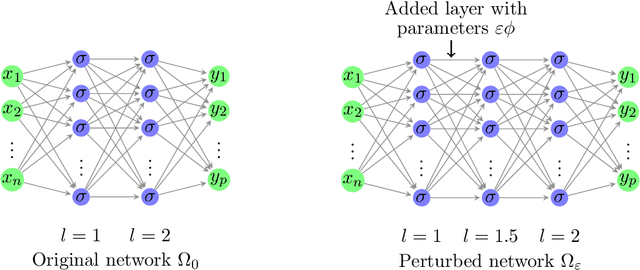

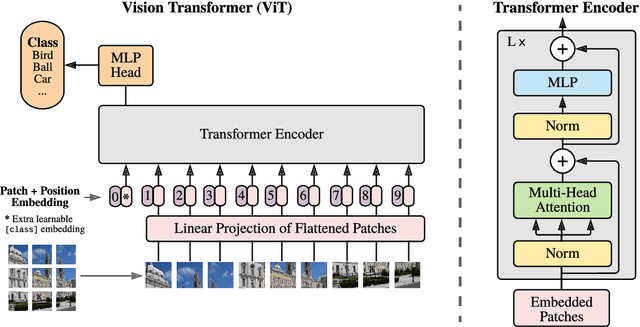
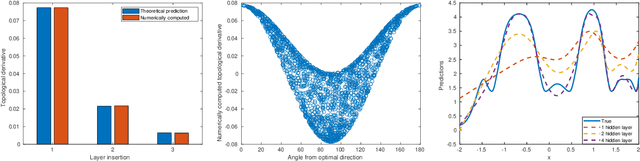
This work presents a novel algorithm for progressively adapting neural network architecture along the depth. In particular, we attempt to address the following questions in a mathematically principled way: i) Where to add a new capacity (layer) during the training process? ii) How to initialize the new capacity? At the heart of our approach are two key ingredients: i) the introduction of a ``shape functional" to be minimized, which depends on neural network topology, and ii) the introduction of a topological derivative of the shape functional with respect to the neural network topology. Using an optimal control viewpoint, we show that the network topological derivative exists under certain conditions, and its closed-form expression is derived. In particular, we explore, for the first time, the connection between the topological derivative from a topology optimization framework with the Hamiltonian from optimal control theory. Further, we show that the optimality condition for the shape functional leads to an eigenvalue problem for deep neural architecture adaptation. Our approach thus determines the most sensitive location along the depth where a new layer needs to be inserted during the training phase and the associated parametric initialization for the newly added layer. We also demonstrate that our layer insertion strategy can be derived from an optimal transport viewpoint as a solution to maximizing a topological derivative in $p$-Wasserstein space, where $p>= 1$. Numerical investigations with fully connected network, convolutional neural network, and vision transformer on various regression and classification problems demonstrate that our proposed approach can outperform an ad-hoc baseline network and other architecture adaptation strategies. Further, we also demonstrate other applications of topological derivative in fields such as transfer learning.
Layerwise Sparsifying Training and Sequential Learning Strategy for Neural Architecture Adaptation
Nov 13, 2022This work presents a two-stage framework for progressively developing neural architectures to adapt/ generalize well on a given training data set. In the first stage, a manifold-regularized layerwise sparsifying training approach is adopted where a new layer is added each time and trained independently by freezing parameters in the previous layers. In order to constrain the functions that should be learned by each layer, we employ a sparsity regularization term, manifold regularization term and a physics-informed term. We derive the necessary conditions for trainability of a newly added layer and analyze the role of manifold regularization. In the second stage of the Algorithm, a sequential learning process is adopted where a sequence of small networks is employed to extract information from the residual produced in stage I and thereby making robust and more accurate predictions. Numerical investigations with fully connected network on prototype regression problem, and classification problem demonstrate that the proposed approach can outperform adhoc baseline networks. Further, application to physics-informed neural network problems suggests that the method could be employed for creating interpretable hidden layers in a deep network while outperforming equivalent baseline networks.