 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAWSAT: Towards Both Robust and Accurate Code Models
Nov 22, 2022

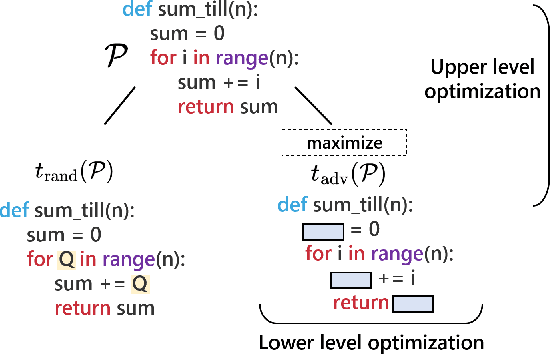

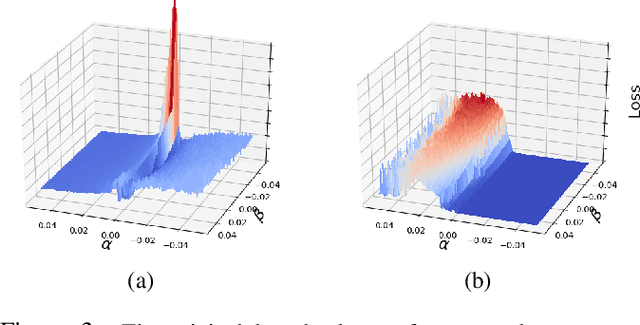
We integrate contrastive learning (CL) with adversarial learning to co-optimize the robustness and accuracy of code models. Different from existing works, we show that code obfuscation, a standard code transformation operation, provides novel means to generate complementary `views' of a code that enable us to achieve both robust and accurate code models. To the best of our knowledge, this is the first systematic study to explore and exploit the robustness and accuracy benefits of (multi-view) code obfuscations in code models. Specifically, we first adopt adversarial codes as robustness-promoting views in CL at the self-supervised pre-training phase. This yields improved robustness and transferability for downstream tasks. Next, at the supervised fine-tuning stage, we show that adversarial training with a proper temporally-staggered schedule of adversarial code generation can further improve robustness and accuracy of the pre-trained code model. Built on the above two modules, we develop CLAWSAT, a novel self-supervised learning (SSL) framework for code by integrating $\underline{\textrm{CL}}$ with $\underline{\textrm{a}}$dversarial vie$\underline{\textrm{w}}$s (CLAW) with $\underline{\textrm{s}}$taggered $\underline{\textrm{a}}$dversarial $\underline{\textrm{t}}$raining (SAT). On evaluating three downstream tasks across Python and Java, we show that CLAWSAT consistently yields the best robustness and accuracy ($\textit{e.g.}$ 11$\%$ in robustness and 6$\%$ in accuracy on the code summarization task in Python). We additionally demonstrate the effectiveness of adversarial learning in CLAW by analyzing the characteristics of the loss landscape and interpretability of the pre-trained models.
ObSynth: An Interactive Synthesis System for Generating Object Models from Natural Language Specifications
Oct 20, 2022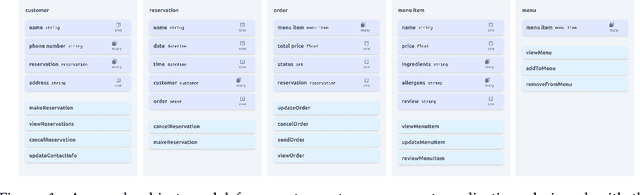

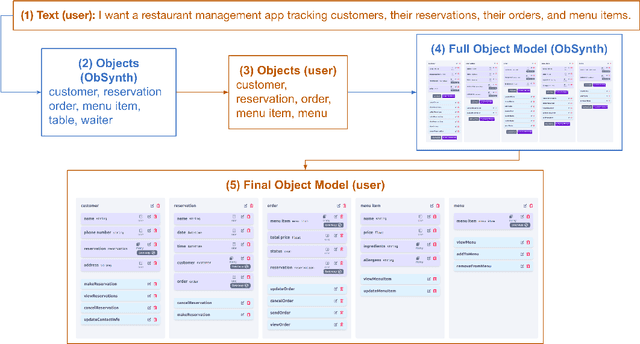

We introduce ObSynth, an interactive system leveraging the domain knowledge embedded in large language models (LLMs) to help users design object models from high level natural language prompts. This is an example of specification reification, the process of taking a high-level, potentially vague specification and reifying it into a more concrete form. We evaluate ObSynth via a user study, leading to three key findings: first, object models designed using ObSynth are more detailed, showing that it often synthesizes fields users might have otherwise omitted. Second, a majority of objects, methods, and fields generated by ObSynth are kept by the user in the final object model, highlighting the quality of generated components. Third, ObSynth altered the workflow of participants: they focus on checking that synthesized components were correct rather than generating them from scratch, though ObSynth did not reduce the time participants took to generate object models.
Generating Adversarial Computer Programs using Optimized Obfuscations
Mar 18, 2021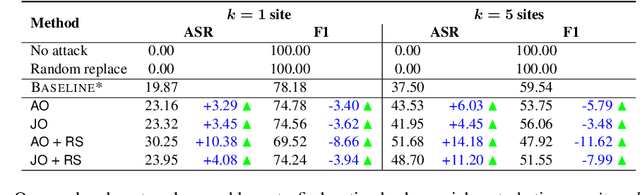

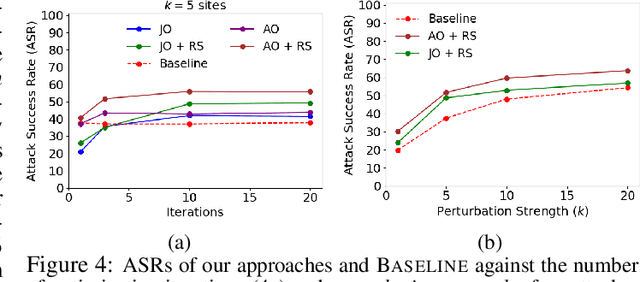
Machine learning (ML) models that learn and predict properties of computer programs are increasingly being adopted and deployed. These models have demonstrated success in applications such as auto-completing code, summarizing large programs, and detecting bugs and malware in programs. In this work, we investigate principled ways to adversarially perturb a computer program to fool such learned models, and thus determine their adversarial robustness. We use program obfuscations, which have conventionally been used to avoid attempts at reverse engineering programs, as adversarial perturbations. These perturbations modify programs in ways that do not alter their functionality but can be crafted to deceive an ML model when making a decision. We provide a general formulation for an adversarial program that allows applying multiple obfuscation transformations to a program in any language. We develop first-order optimization algorithms to efficiently determine two key aspects -- which parts of the program to transform, and what transformations to use. We show that it is important to optimize both these aspects to generate the best adversarially perturbed program. Due to the discrete nature of this problem, we also propose using randomized smoothing to improve the attack loss landscape to ease optimization. We evaluate our work on Python and Java programs on the problem of program summarization. We show that our best attack proposal achieves a $52\%$ improvement over a state-of-the-art attack generation approach for programs trained on a seq2seq model. We further show that our formulation is better at training models that are robust to adversarial attacks.