 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAWSAT: Towards Both Robust and Accurate Code Models
Nov 22, 2022

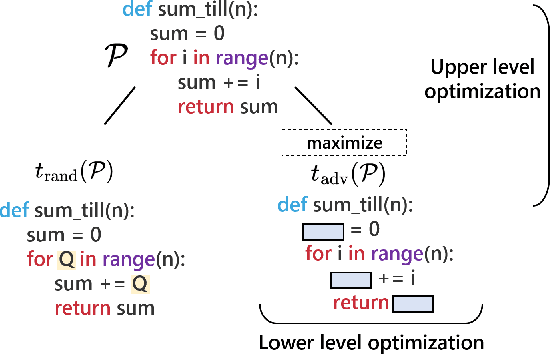

We integrate contrastive learning (CL) with adversarial learning to co-optimize the robustness and accuracy of code models. Different from existing works, we show that code obfuscation, a standard code transformation operation, provides novel means to generate complementary `views' of a code that enable us to achieve both robust and accurate code models. To the best of our knowledge, this is the first systematic study to explore and exploit the robustness and accuracy benefits of (multi-view) code obfuscations in code models. Specifically, we first adopt adversarial codes as robustness-promoting views in CL at the self-supervised pre-training phase. This yields improved robustness and transferability for downstream tasks. Next, at the supervised fine-tuning stage, we show that adversarial training with a proper temporally-staggered schedule of adversarial code generation can further improve robustness and accuracy of the pre-trained code model. Built on the above two modules, we develop CLAWSAT, a novel self-supervised learning (SSL) framework for code by integrating $\underline{\textrm{CL}}$ with $\underline{\textrm{a}}$dversarial vie$\underline{\textrm{w}}$s (CLAW) with $\underline{\textrm{s}}$taggered $\underline{\textrm{a}}$dversarial $\underline{\textrm{t}}$raining (SAT). On evaluating three downstream tasks across Python and Java, we show that CLAWSAT consistently yields the best robustness and accuracy ($\textit{e.g.}$ 11$\%$ in robustness and 6$\%$ in accuracy on the code summarization task in Python). We additionally demonstrate the effectiveness of adversarial learning in CLAW by analyzing the characteristics of the loss landscape and interpretability of the pre-trained models.
Generating Adversarial Computer Programs using Optimized Obfuscations
Mar 18, 2021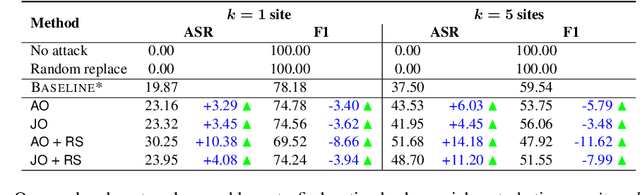

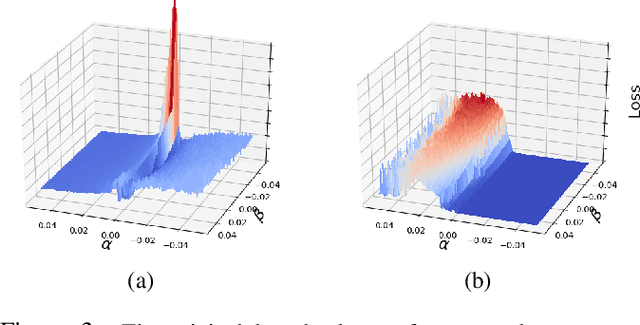
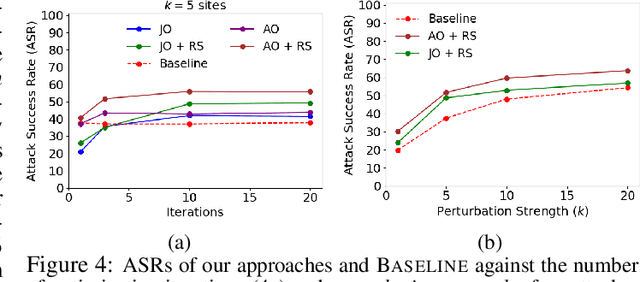
Machine learning (ML) models that learn and predict properties of computer programs are increasingly being adopted and deployed. These models have demonstrated success in applications such as auto-completing code, summarizing large programs, and detecting bugs and malware in programs. In this work, we investigate principled ways to adversarially perturb a computer program to fool such learned models, and thus determine their adversarial robustness. We use program obfuscations, which have conventionally been used to avoid attempts at reverse engineering programs, as adversarial perturbations. These perturbations modify programs in ways that do not alter their functionality but can be crafted to deceive an ML model when making a decision. We provide a general formulation for an adversarial program that allows applying multiple obfuscation transformations to a program in any language. We develop first-order optimization algorithms to efficiently determine two key aspects -- which parts of the program to transform, and what transformations to use. We show that it is important to optimize both these aspects to generate the best adversarially perturbed program. Due to the discrete nature of this problem, we also propose using randomized smoothing to improve the attack loss landscape to ease optimization. We evaluate our work on Python and Java programs on the problem of program summarization. We show that our best attack proposal achieves a $52\%$ improvement over a state-of-the-art attack generation approach for programs trained on a seq2seq model. We further show that our formulation is better at training models that are robust to adversarial attacks.
Dependency-Based Neural Representations for Classifying Lines of Programs
Apr 08, 2020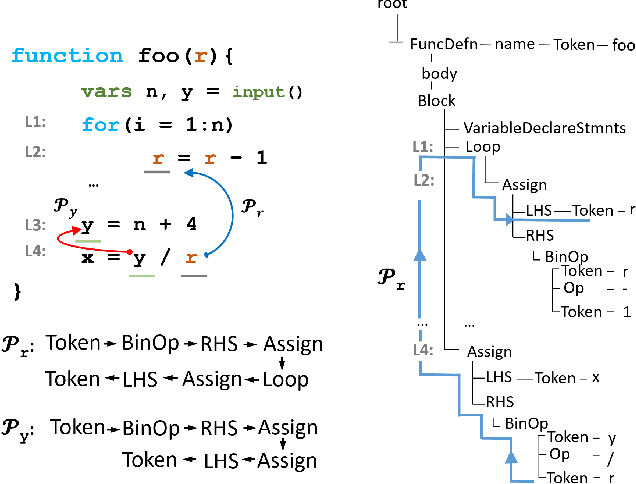
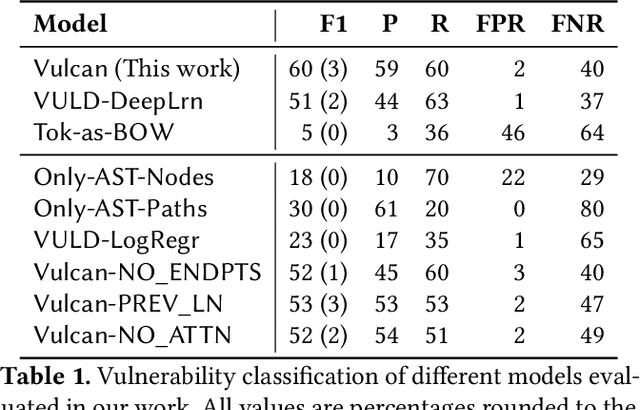
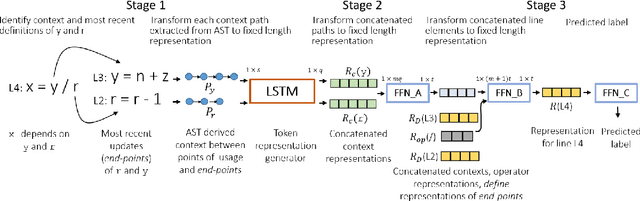

We investigate the problem of classifying a line of program as containing a vulnerability or not using machine learning. Such a line-level classification task calls for a program representation which goes beyond reasoning from the tokens present in the line. We seek a distributed representation in a latent feature space which can capture the control and data dependencies of tokens appearing on a line of program, while also ensuring lines of similar meaning have similar features. We present a neural architecture, Vulcan, that successfully demonstrates both these requirements. It extracts contextual information about tokens in a line and inputs them as Abstract Syntax Tree (AST) paths to a bi-directional LSTM with an attention mechanism. It concurrently represents the meanings of tokens in a line by recursively embedding the lines where they are most recently defined. In our experiments, Vulcan compares favorably with a state-of-the-art classifier, which requires significant preprocessing of programs, suggesting the utility of using deep learning to model program dependence information.