 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Antibody Humanness Prediction using Patent Data
Jan 31, 2024



We investigate the potential of patent data for improving the antibody humanness prediction using a multi-stage, multi-loss training process. Humanness serves as a proxy for the immunogenic response to antibody therapeutics, one of the major causes of attrition in drug discovery and a challenging obstacle for their use in clinical settings. We pose the initial learning stage as a weakly-supervised contrastive-learning problem, where each antibody sequence is associated with possibly multiple identifiers of function and the objective is to learn an encoder that groups them according to their patented properties. We then freeze a part of the contrastive encoder and continue training it on the patent data using the cross-entropy loss to predict the humanness score of a given antibody sequence. We illustrate the utility of the patent data and our approach by performing inference on three different immunogenicity datasets, unseen during training. Our empirical results demonstrate that the learned model consistently outperforms the alternative baselines and establishes new state-of-the-art on five out of six inference tasks, irrespective of the used metric.
NESS: Learning Node Embeddings from Static SubGraphs
Mar 15, 2023We present a framework for learning Node Embeddings from Static Subgraphs (NESS) using a graph autoencoder (GAE) in a transductive setting. Moreover, we propose a novel approach for contrastive learning in the same setting. We demonstrate that using static subgraphs during training with a GAE improves node representation for link prediction tasks compared to current autoencoding methods using the entire graph or stochastic subgraphs. NESS consists of two steps: 1) Partitioning the training graph into subgraphs using random edge split (RES) during data pre-processing, and 2) Aggregating the node representations learned from each subgraph to obtain a joint representation of the graph at test time. Our experiments show that NESS improves the performance of a wide range of graph encoders and achieves state-of-the-art (SOTA) results for link prediction on multiple benchmark datasets.
Parameter Averaging for Robust Explainability
Aug 05, 2022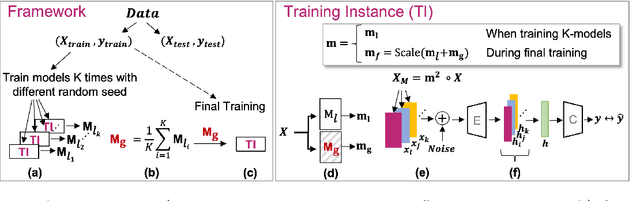
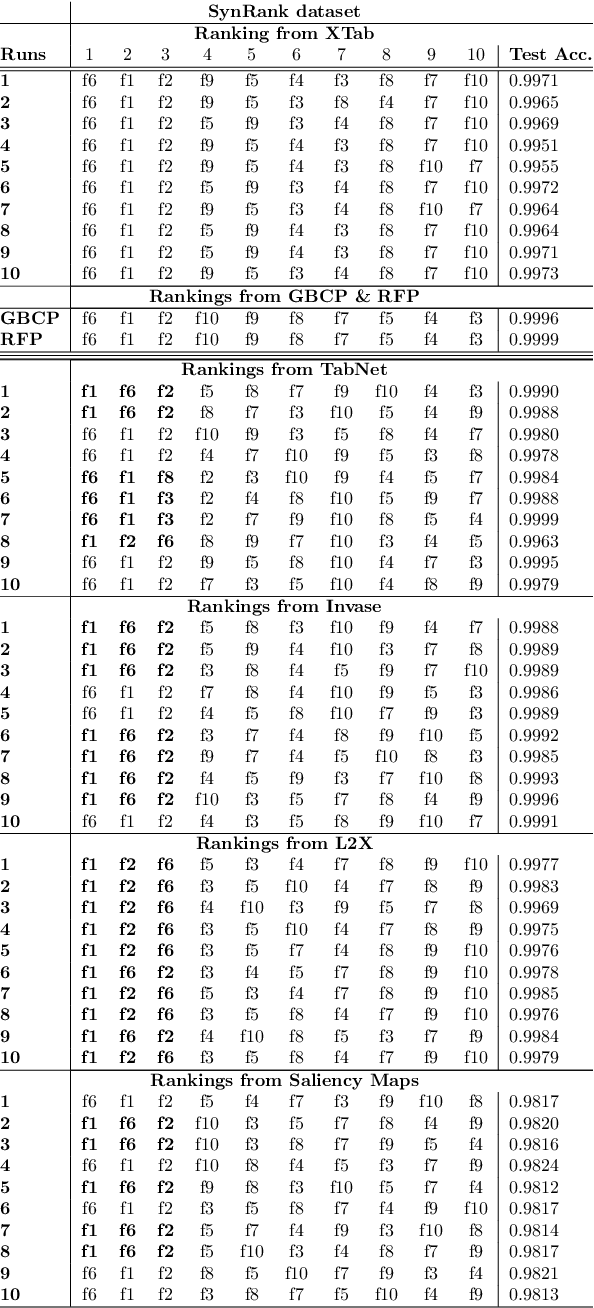
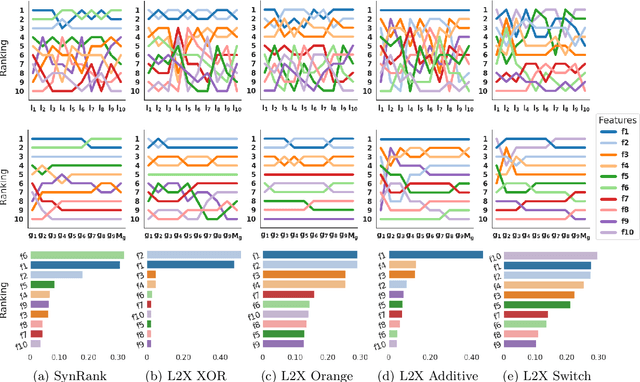
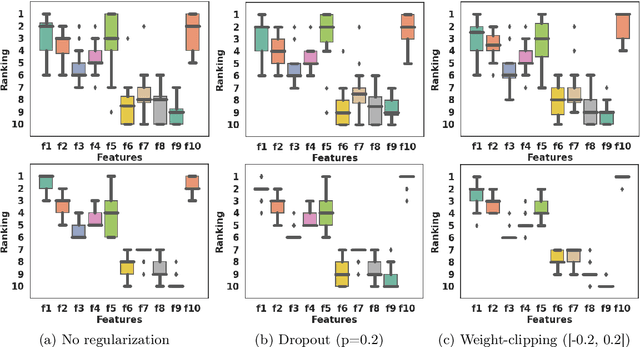
Neural Networks are known to be sensitive to initialisation. The explanation methods that rely on neural networks are not robust since they can have variations in their explanations when the model is initialized and trained with different random seeds. The sensitivity to model initialisation is not desirable in many safety critical applications such as disease diagnosis in healthcare, in which the explainability might have a significant impact in helping decision making. In this work, we introduce a novel method based on parameter averaging for robust explainability in tabular data setting, referred as XTab. We first initialize and train multiple instances of a shallow network (referred as local masks) with different random seeds for a downstream task. We then obtain a global mask model by "averaging the parameters" of local masks and show that the global model uses the majority rule to rank features based on their relative importance across all local models. We conduct extensive experiments on a variety of real and synthetic datasets, demonstrating that the proposed method can be used for feature selection as well as to obtain the global feature importance that are not sensitive to sub-optimal model initialisation.
SubTab: Subsetting Features of Tabular Data for Self-Supervised Representation Learning
Oct 27, 2021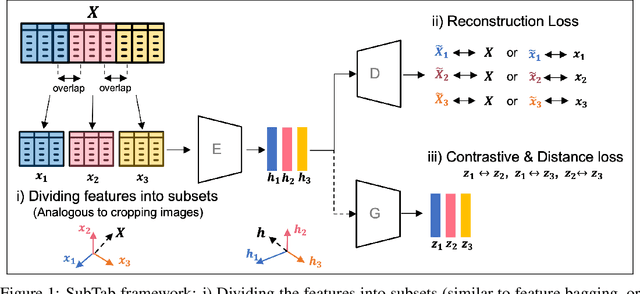
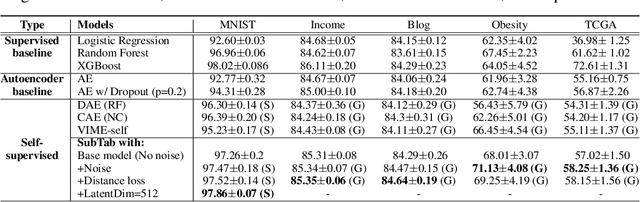
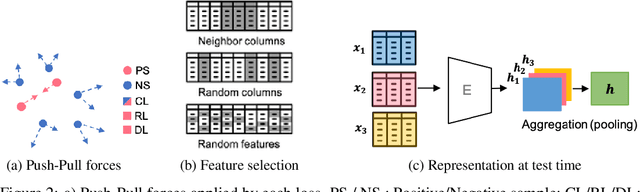
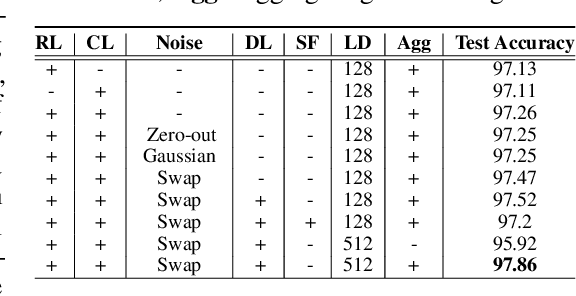
Self-supervised learning has been shown to be very effective in learning useful representations, and yet much of the success is achieved in data types such as images, audio, and text. The success is mainly enabled by taking advantage of spatial, temporal, or semantic structure in the data through augmentation. However, such structure may not exist in tabular datasets commonly used in fields such as healthcare, making it difficult to design an effective augmentation method, and hindering a similar progress in tabular data setting. In this paper, we introduce a new framework, Subsetting features of Tabular data (SubTab), that turns the task of learning from tabular data into a multi-view representation learning problem by dividing the input features to multiple subsets. We argue that reconstructing the data from the subset of its features rather than its corrupted version in an autoencoder setting can better capture its underlying latent representation. In this framework, the joint representation can be expressed as the aggregate of latent variables of the subsets at test time, which we refer to as collaborative inference. Our experiments show that the SubTab achieves the state of the art (SOTA) performance of 98.31% on MNIST in tabular setting, on par with CNN-based SOTA models, and surpasses existing baselines on three other real-world datasets by a significant margin.
One-Shot Learning for Language Modelling
Jul 19, 2020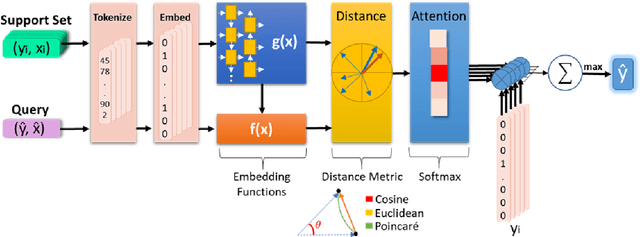

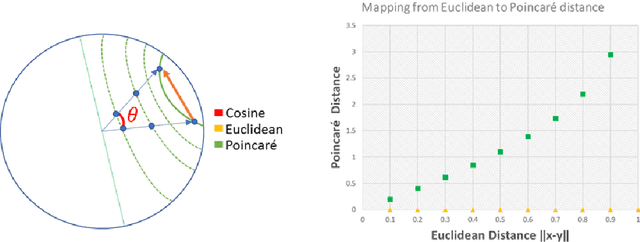
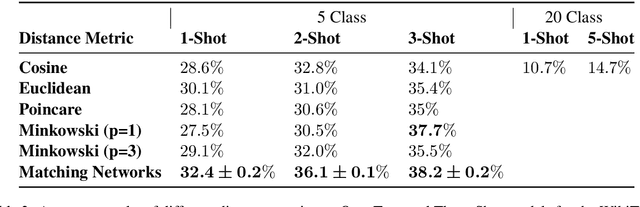
Humans can infer a great deal about the meaning of a word, using the syntax and semantics of surrounding words even if it is their first time reading or hearing it. We can also generalise the learned concept of the word to new tasks. Despite great progress in achieving human-level performance in certain tasks (Silver et al., 2016), learning from one or few examples remains a key challenge in machine learning, and has not thoroughly been explored in Natural Language Processing (NLP). In this work we tackle the problem of oneshot learning for an NLP task by employing ideas from recent developments in machine learning: embeddings, attention mechanisms (softmax) and similarity measures (cosine, Euclidean, Poincare, and Minkowski). We adapt the framework suggested in matching networks (Vinyals et al., 2016), and explore the effectiveness of the aforementioned methods in one, two and three-shot learning problems on the task of predicting missing word explored in (Vinyals et al., 2016) by using the WikiText-2 dataset. Our work contributes in two ways: Our first contribution is that we explore the effectiveness of different distance metrics on k-shot learning, and show that there is no single best distance metric for k-shot learning, which challenges common belief. We found that the performance of a distance metric depends on the number of shots used during training. The second contribution of our work is that we establish a benchmark for one, two, and three-shot learning on a language task with a publicly available dataset that can be used to benchmark against in future research.
Inverse Graphics: Unsupervised Learning of 3D Shapes from Single Images
Dec 02, 2019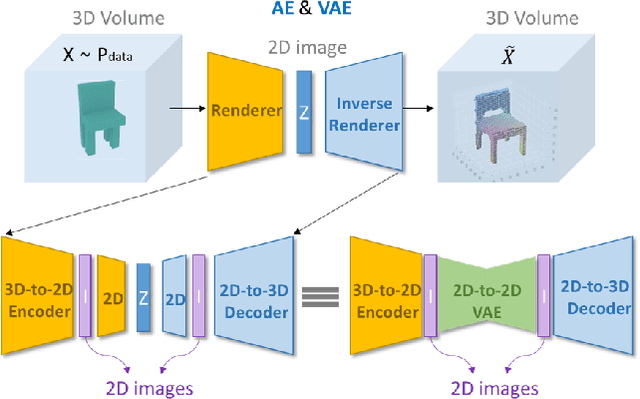

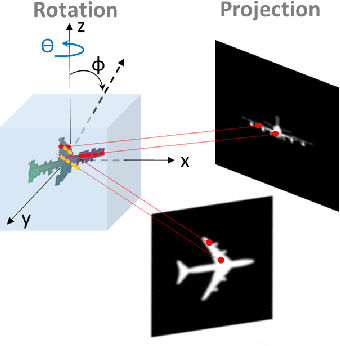
Using generative models for Inverse Graphics is an active area of research. However, most works focus on developing models for supervised and semi-supervised methods. In this paper, we study the problem of unsupervised learning of 3D geometry from single images. Our approach is to use a generative model that produces 2-D images as projections of a latent 3D voxel grid, which we train either as a variational auto-encoder or using adversarial methods. Our contributions are as follows: First, we show how to recover 3D shape and pose from general datasets such as MNIST, and MNIST Fashion in good quality. Second, we compare the shapes learned using adversarial and variational methods. Adversarial approach gives denser 3D shapes. Third, we explore the idea of modelling the pose of an object as uniform distribution to recover 3D shape from a single image. Our experiment with the CelebA dataset \cite{liu2015faceattributes} proves that we can recover complete 3D shape from a single image when the object is symmetric along one, or more axis whilst results obtained using ModelNet40 \cite{wu20153d} show the potential side-effects, in which the model learns 3D shapes such that it can render the same image from any viewpoint. Forth, we present a general end-to-end approach to learning 3D shapes from single images in a completely unsupervised fashion by modelling the factors of variation such as azimuth as independent latent variables. Our method makes no assumptions about the dataset, and can work with synthetic as well as real images (i.e. unsupervised in true sense). We present our results, by training the model using the $\mu$-VAE objective \cite{ucar2019bridging} and a dataset combining all images from MNIST, MNIST Fashion, CelebA and six categories of ModelNet40. The model is able to learn 3D shapes and the pose in qood quality and leverages information learned across all datasets.
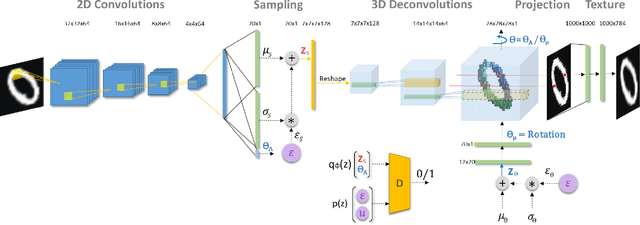
Bridging the ELBO and MMD
Oct 29, 2019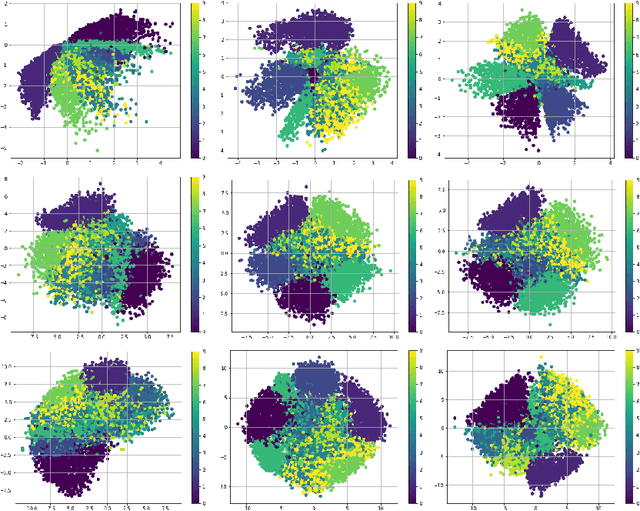
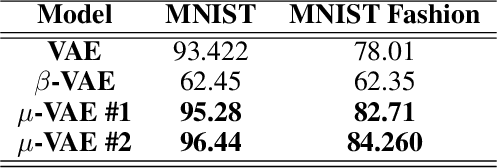
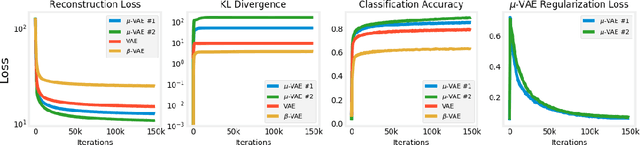

One of the challenges in training generative models such as the variational auto encoder (VAE) is avoiding posterior collapse. When the generator has too much capacity, it is prone to ignoring latent code. This problem is exacerbated when the dataset is small, and the latent dimension is high. The root of the problem is the ELBO objective, specifically the Kullback-Leibler (KL) divergence term in objective function \citep{zhao2019infovae}. This paper proposes a new objective function to replace the KL term with one that emulates the maximum mean discrepancy (MMD) objective. It also introduces a new technique, named latent clipping, that is used to control distance between samples in latent space. A probabilistic autoencoder model, named $\mu$-VAE, is designed and trained on MNIST and MNIST Fashion datasets, using the new objective function and is shown to outperform models trained with ELBO and $\beta$-VAE objective. The $\mu$-VAE is less prone to posterior collapse, and can generate reconstructions and new samples in good quality. Latent representations learned by $\mu$-VAE are shown to be good and can be used for downstream tasks such as classification.