 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Graphics: Unsupervised Learning of 3D Shapes from Single Images
Paper and Code
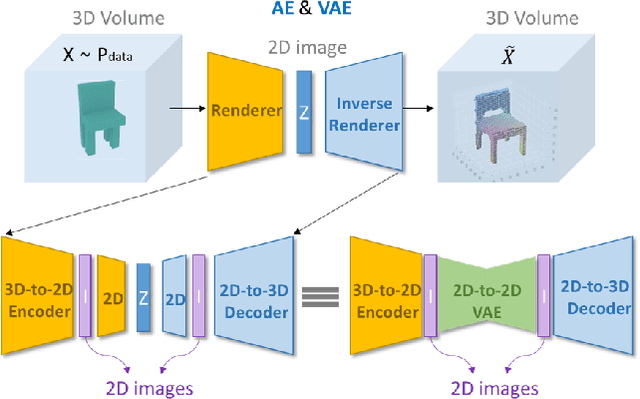

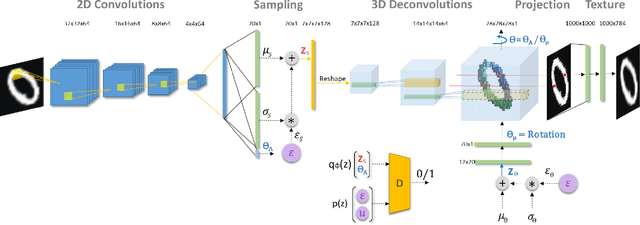
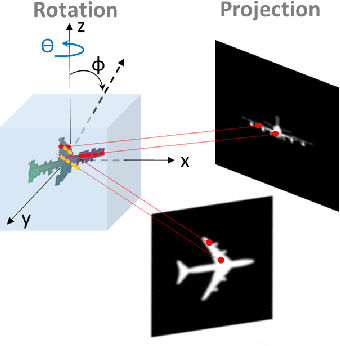
Using generative models for Inverse Graphics is an active area of research. However, most works focus on developing models for supervised and semi-supervised methods. In this paper, we study the problem of unsupervised learning of 3D geometry from single images. Our approach is to use a generative model that produces 2-D images as projections of a latent 3D voxel grid, which we train either as a variational auto-encoder or using adversarial methods. Our contributions are as follows: First, we show how to recover 3D shape and pose from general datasets such as MNIST, and MNIST Fashion in good quality. Second, we compare the shapes learned using adversarial and variational methods. Adversarial approach gives denser 3D shapes. Third, we explore the idea of modelling the pose of an object as uniform distribution to recover 3D shape from a single image. Our experiment with the CelebA dataset \cite{liu2015faceattributes} proves that we can recover complete 3D shape from a single image when the object is symmetric along one, or more axis whilst results obtained using ModelNet40 \cite{wu20153d} show the potential side-effects, in which the model learns 3D shapes such that it can render the same image from any viewpoint. Forth, we present a general end-to-end approach to learning 3D shapes from single images in a completely unsupervised fashion by modelling the factors of variation such as azimuth as independent latent variables. Our method makes no assumptions about the dataset, and can work with synthetic as well as real images (i.e. unsupervised in true sense). We present our results, by training the model using the $\mu$-VAE objective \cite{ucar2019bridging} and a dataset combining all images from MNIST, MNIST Fashion, CelebA and six categories of ModelNet40. The model is able to learn 3D shapes and the pose in qood quality and leverages information learned across all datasets.