 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the ELBO and MMD
Paper and Code
Oct 29, 2019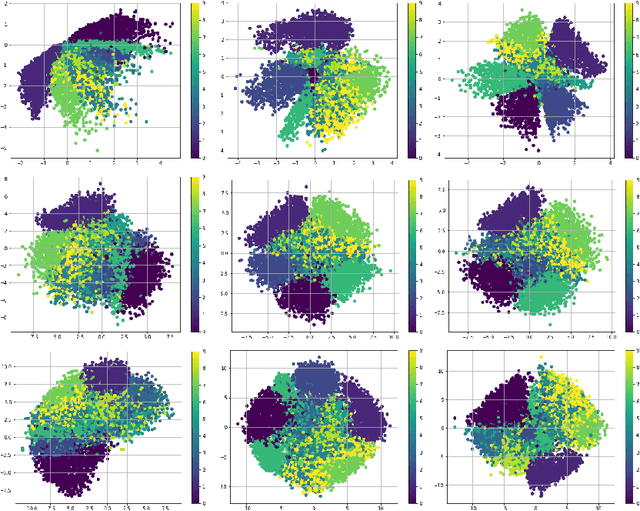
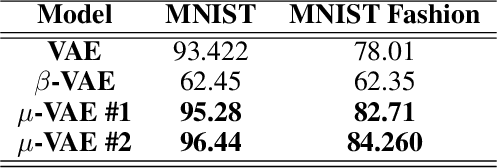
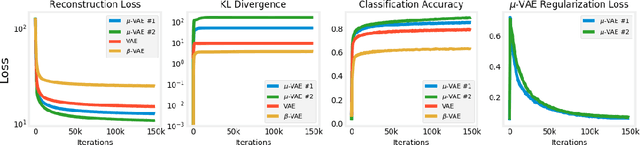

One of the challenges in training generative models such as the variational auto encoder (VAE) is avoiding posterior collapse. When the generator has too much capacity, it is prone to ignoring latent code. This problem is exacerbated when the dataset is small, and the latent dimension is high. The root of the problem is the ELBO objective, specifically the Kullback-Leibler (KL) divergence term in objective function \citep{zhao2019infovae}. This paper proposes a new objective function to replace the KL term with one that emulates the maximum mean discrepancy (MMD) objective. It also introduces a new technique, named latent clipping, that is used to control distance between samples in latent space. A probabilistic autoencoder model, named $\mu$-VAE, is designed and trained on MNIST and MNIST Fashion datasets, using the new objective function and is shown to outperform models trained with ELBO and $\beta$-VAE objective. The $\mu$-VAE is less prone to posterior collapse, and can generate reconstructions and new samples in good quality. Latent representations learned by $\mu$-VAE are shown to be good and can be used for downstream tasks such as classification.