 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepExtractor: Time-domain reconstruction of signals and glitches in gravitational wave data with deep learning
Jan 30, 2025



Gravitational wave (GW) interferometers, detect faint signals from distant astrophysical events, such as binary black hole mergers. However, their high sensitivity also makes them susceptible to background noise, which can obscure these signals. This noise often includes transient artifacts called "glitches" that can mimic astrophysical signals or mask their characteristics. Fast and accurate reconstruction of both signals and glitches is crucial for reliable scientific inference. In this study, we present DeepExtractor, a deep learning framework designed to reconstruct signals and glitches with power exceeding interferometer noise, regardless of their source. We design DeepExtractor to model the inherent noise distribution of GW interferometers, following conventional assumptions that the noise is Gaussian and stationary over short time scales. It operates by predicting and subtracting the noise component of the data, retaining only the clean reconstruction. Our approach achieves superior generalization capabilities for arbitrary signals and glitches compared to methods that directly map inputs to the clean training waveforms. We validate DeepExtractor's effectiveness through three experiments: (1) reconstructing simulated glitches injected into simulated detector noise, (2) comparing performance with the state-of-the-art BayesWave algorithm, and (3) analyzing real data from the Gravity Spy dataset to demonstrate effective glitch subtraction from LIGO strain data. DeepExtractor achieves a median mismatch of only 0.9% for simulated glitches, outperforming several deep learning baselines. Additionally, DeepExtractor surpasses BayesWave in glitch recovery, offering a dramatic computational speedup by reconstructing one glitch sample in approx. 0.1 seconds on a CPU, compared to BayesWave's processing time of approx. one hour per glitch.
cDVGAN: One Flexible Model for Multi-class Gravitational Wave Signal and Glitch Generation
Feb 07, 2024Simulating realistic time-domain observations of gravitational waves (GWs) and GW detector glitches can help in advancing GW data analysis. Simulated data can be used in downstream tasks by augmenting datasets for signal searches, balancing data sets for machine learning, and validating detection schemes. In this work, we present Conditional Derivative GAN (cDVGAN), a novel conditional model in the Generative Adversarial Network framework for simulating multiple classes of time-domain observations that represent gravitational waves (GWs) and detector glitches. cDVGAN can also generate generalized hybrid samples that span the variation between classes through interpolation in the conditioned class vector. cDVGAN introduces an additional player into the typical 2-player adversarial game of GANs, where an auxiliary discriminator analyzes the first-order derivative time-series. Our results show that this provides synthetic data that better captures the features of the original data. cDVGAN conditions on three classes, two denoised from LIGO blip and tomte glitch events from its 3rd observing run (O3), and the third representing binary black hole (BBH) mergers. Our proposed cDVGAN outperforms 4 different baseline GAN models in replicating the features of the three classes. Specifically, our experiments show that training convolutional neural networks (CNNs) with our cDVGAN-generated data improves the detection of samples embedded in detector noise beyond the synthetic data from other state-of-the-art GAN models. Our best synthetic dataset yields as much as a 4.2% increase in area-under-the-curve (AUC) performance compared to synthetic datasets from baseline GANs. Moreover, training the CNN with hybrid samples from our cDVGAN outperforms CNNs trained only on the standard classes, when identifying real samples embedded in LIGO detector background (4% AUC improvement for cDVGAN).
DVGAN: Stabilize Wasserstein GAN training for time-domain Gravitational Wave physics
Sep 29, 2022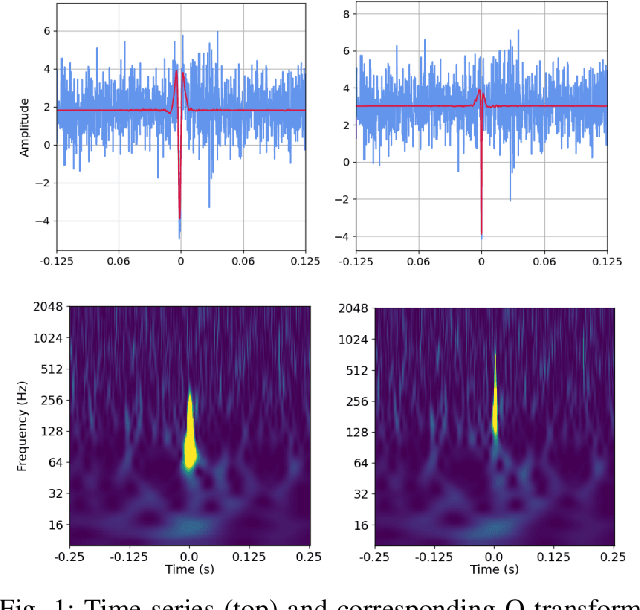
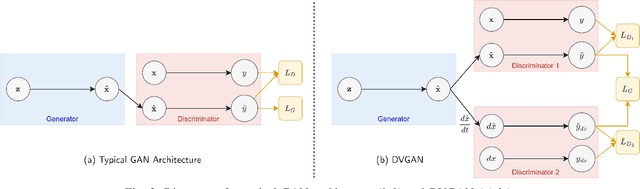
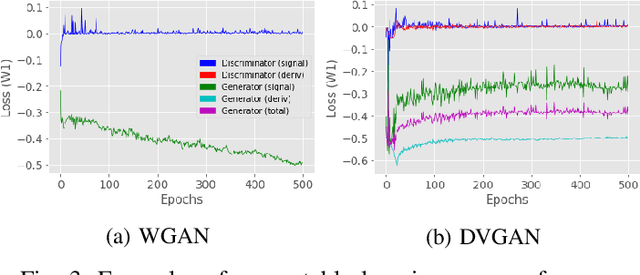
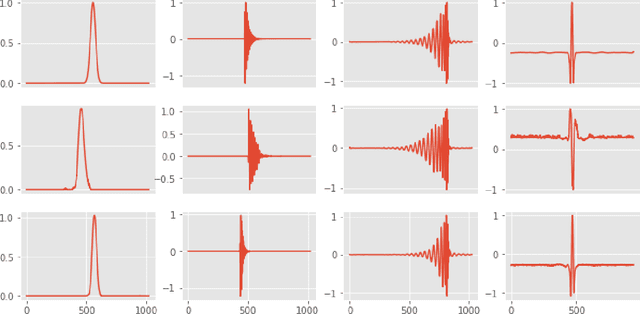
Simulating time-domain observations of gravitational wave (GW) detector environments will allow for a better understanding of GW sources, augment datasets for GW signal detection and help in characterizing the noise of the detectors, leading to better physics. This paper presents a novel approach to simulating fixed-length time-domain signals using a three-player Wasserstein Generative Adversarial Network (WGAN), called DVGAN, that includes an auxiliary discriminator that discriminates on the derivatives of input signals. An ablation study is used to compare the effects of including adversarial feedback from an auxiliary derivative discriminator with a vanilla two-player WGAN. We show that discriminating on derivatives can stabilize the learning of GAN components on 1D continuous signals during their training phase. This results in smoother generated signals that are less distinguishable from real samples and better capture the distributions of the training data. DVGAN is also used to simulate real transient noise events captured in the advanced LIGO GW detector.
Sim-Env: Decoupling OpenAI Gym Environments from Simulation Models
Feb 22, 2021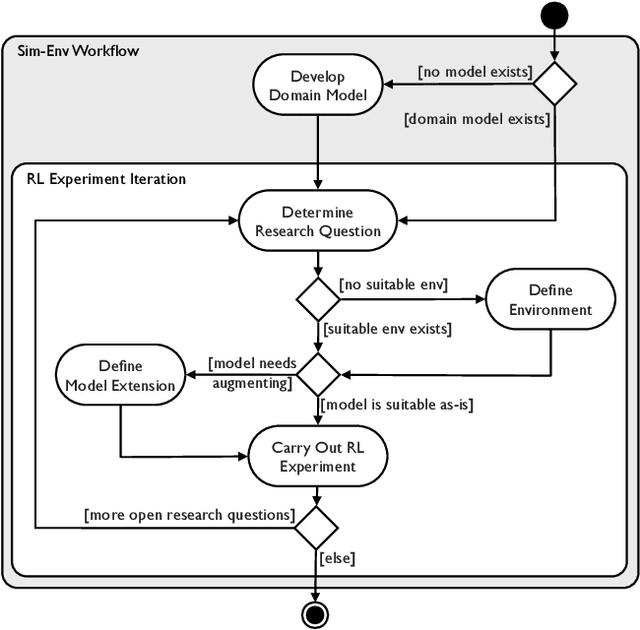
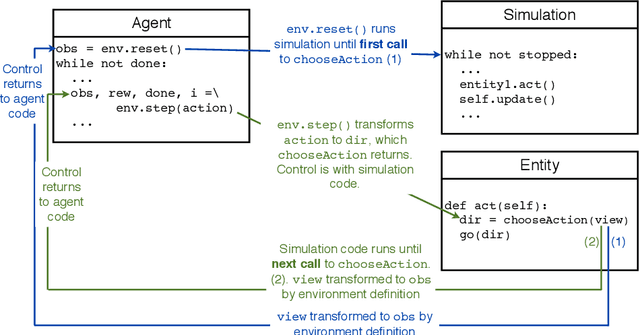

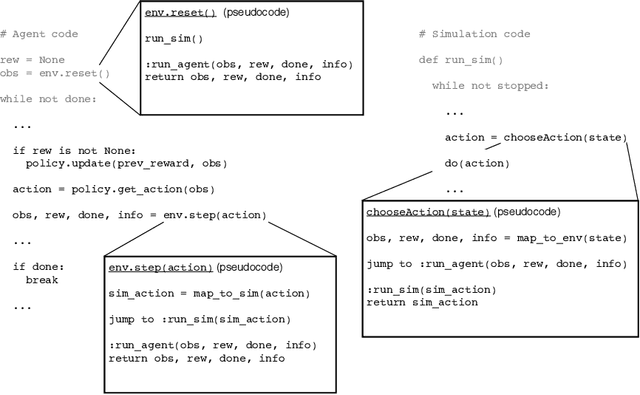
Reinforcement learning (RL) is one of the most active fields of AI research. Despite the interest demonstrated by the research community in reinforcement learning, the development methodology still lags behind, with a severe lack of standard APIs to foster the development of RL applications. OpenAI Gym is probably the most used environment to develop RL applications and simulations, but most of the abstractions proposed in such a framework are still assuming a semi-structured methodology. This is particularly relevant for agent-based models whose purpose is to analyse adaptive behaviour displayed by self-learning agents in the simulation. In order to bridge this gap, we present a workflow and tools for the decoupled development and maintenance of multi-purpose agent-based models and derived single-purpose reinforcement learning environments, enabling the researcher to swap out environments with ones representing different perspectives or different reward models, all while keeping the underlying domain model intact and separate. The Sim-Env Python library generates OpenAI-Gym-compatible reinforcement learning environments that use existing or purposely created domain models as their simulation back-ends. Its design emphasizes ease-of-use, modularity and code separation.
That looks interesting! Personalizing Communication and Segmentation with Random Forest Node Embeddings
Sep 13, 2020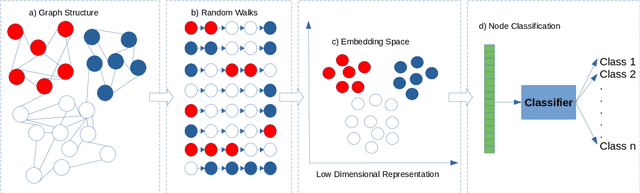

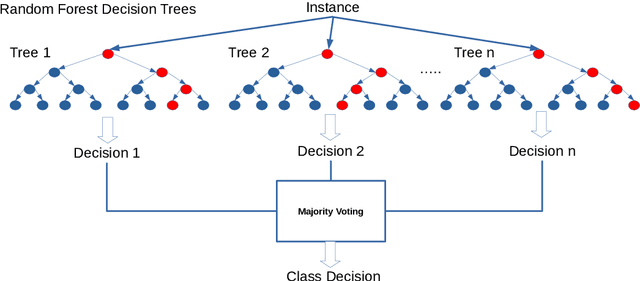

Communicating effectively with customers is a challenge for many marketers, but especially in a context that is both pivotal to individual long-term financial well-being and difficult to understand: pensions. Around the world, participants are reluctant to consider their pension in advance, it leads to a lack of preparation of their pension retirement [1], [2]. In order to engage participants to obtain information on their expected pension benefits, personalizing the pension providers' email communication is a first and crucial step. We describe a machine learning approach to model email newsletters to fit participants' interests. The data for the modeling and analysis is collected from newsletters sent by a large Dutch pension provider of the Netherlands and is divided into two parts. The first part comprises 2,228,000 customers whereas the second part comprises the data of a pilot study, which took place in July 2018 with 465,711 participants. In both cases, our algorithm extracts features from continuous and categorical data using random forests, and then calculates node embeddings of the decision boundaries of the random forest. We illustrate the algorithm's effectiveness for the classification task, and how it can be used to perform data mining tasks. In order to confirm that the result is valid for more than one data set, we also illustrate the properties of our algorithm in benchmark data sets concerning churning. In the data sets considered, the proposed modeling demonstrates competitive performance with respect to other state of the art approaches based on random forests, achieving the best Area Under the Curve (AUC) in the pension data set (0.948). For the descriptive part, the algorithm can identify customer segmentations that can be used by marketing departments to better target their communication towards their customers.
Monitoring Spatial Sustainable Development: semi-automated analysis of Satellite and Aerial Images for Energy Transition and Sustainability Indicators
Sep 12, 2020



This report presents the results of the DeepSolaris project that was carried out under the ESS action 'Merging Geostatistics and Geospatial Information in Member States'. During the project several deep learning algorithms were evaluated to detect solar panels in remote sensing data. The aim of the project was to evaluate whether deep learning models could be developed, that worked across different member states in the European Union. Two remote sensing data sources were considered: aerial images on the one hand, and satellite images on the other. Two flavours of deep learning models were evaluated: classification models and object detection models. For the evaluation of the deep learning models we used a cross-site evaluation approach: the deep learning models where trained in one geographical area and then evaluated on a different geographical area, previously unseen by the algorithm. The cross-site evaluation was furthermore carried out twice: deep learning models trained on he Netherlands were evaluated on Germany and vice versa. While the deep learning models were able to detect solar panels successfully, false detection remained a problem. Moreover, model performance decreased dramatically when evaluated in a cross-border fashion. Hence, training a model that performs reliably across different countries in the European Union is a challenging task. That being said, the models detected quite a share of solar panels not present in current solar panel registers and therefore can already be used as-is to help reduced manual labor in checking these registers.
Monitoring spatial sustainable development: Semi-automated analysis of satellite and aerial images for energy transition and sustainability indicators
Oct 11, 2018Solar panels are installed by a large and growing number of households due to the convenience of having cheap and renewable energy to power house appliances. In contrast to other energy sources solar installations are distributed very decentralized and spread over hundred-thousands of locations. On a global level more than 25% of solar photovoltaic (PV) installations were decentralized. The effect of the quick energy transition from a carbon based economy to a green economy is though still very difficult to quantify. As a matter of fact the quick adoption of solar panels by households is difficult to track, with local registries that miss a large number of the newly built solar panels. This makes the task of assessing the impact of renewable energies an impossible task. Although models of the output of a region exist, they are often black box estimations. This project's aim is twofold: First automate the process to extract the location of solar panels from aerial or satellite images and second, produce a map of solar panels along with statistics on the number of solar panels. Further, this project takes place in a wider framework which investigates how official statistics can benefit from new digital data sources. At project completion, a method for detecting solar panels from aerial images via machine learning will be developed and the methodology initially developed for BE, DE and NL will be standardized for application to other EU countries. In practice, machine learning techniques are used to identify solar panels in satellite and aerial images for the province of Limburg (NL), Flanders (BE) and North Rhine-Westphalia (DE).
Indexing the Event Calculus with Kd-trees to Monitor Diabetes
Oct 03, 2017

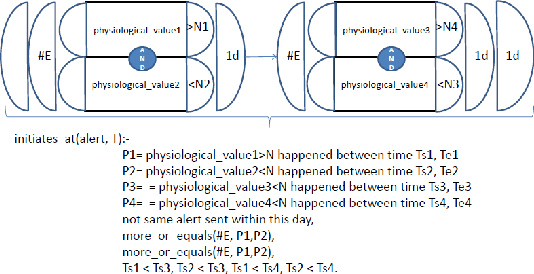

Personal Health Systems (PHS) are mobile solutions tailored to monitoring patients affected by chronic non communicable diseases. A patient affected by a chronic disease can generate large amounts of events. Type 1 Diabetic patients generate several glucose events per day, ranging from at least 6 events per day (under normal monitoring) to 288 per day when wearing a continuous glucose monitor (CGM) that samples the blood every 5 minutes for several days. This is a large number of events to monitor for medical doctors, in particular when considering that they may have to take decisions concerning adjusting the treatment, which may impact the life of the patients for a long time. Given the need to analyse such a large stream of data, doctors need a simple approach towards physiological time series that allows them to promptly transfer their knowledge into queries to identify interesting patterns in the data. Achieving this with current technology is not an easy task, as on one hand it cannot be expected that medical doctors have the technical knowledge to query databases and on the other hand these time series include thousands of events, which requires to re-think the way data is indexed. In order to tackle the knowledge representation and efficiency problem, this contribution presents the kd-tree cached event calculus (\ceckd) an event calculus extension for knowledge engineering of temporal rules capable to handle many thousands events produced by a diabetic patient. \ceckd\ is built as a support to a graphical interface to represent monitoring rules for diabetes type 1. In addition, the paper evaluates the \ceckd\ with respect to the cached event calculus (CEC) to show how indexing events using kd-trees improves scalability with respect to the current state of the art.