 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecDVGAN: One Flexible Model for Multi-class Gravitational Wave Signal and Glitch Generation
Feb 07, 2024Simulating realistic time-domain observations of gravitational waves (GWs) and GW detector glitches can help in advancing GW data analysis. Simulated data can be used in downstream tasks by augmenting datasets for signal searches, balancing data sets for machine learning, and validating detection schemes. In this work, we present Conditional Derivative GAN (cDVGAN), a novel conditional model in the Generative Adversarial Network framework for simulating multiple classes of time-domain observations that represent gravitational waves (GWs) and detector glitches. cDVGAN can also generate generalized hybrid samples that span the variation between classes through interpolation in the conditioned class vector. cDVGAN introduces an additional player into the typical 2-player adversarial game of GANs, where an auxiliary discriminator analyzes the first-order derivative time-series. Our results show that this provides synthetic data that better captures the features of the original data. cDVGAN conditions on three classes, two denoised from LIGO blip and tomte glitch events from its 3rd observing run (O3), and the third representing binary black hole (BBH) mergers. Our proposed cDVGAN outperforms 4 different baseline GAN models in replicating the features of the three classes. Specifically, our experiments show that training convolutional neural networks (CNNs) with our cDVGAN-generated data improves the detection of samples embedded in detector noise beyond the synthetic data from other state-of-the-art GAN models. Our best synthetic dataset yields as much as a 4.2% increase in area-under-the-curve (AUC) performance compared to synthetic datasets from baseline GANs. Moreover, training the CNN with hybrid samples from our cDVGAN outperforms CNNs trained only on the standard classes, when identifying real samples embedded in LIGO detector background (4% AUC improvement for cDVGAN).
Understanding Iterative Revision from Human-Written Text
Mar 16, 2022


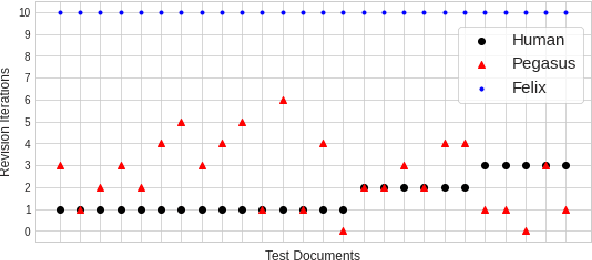
Writing is, by nature, a strategic, adaptive, and more importantly, an iterative process. A crucial part of writing is editing and revising the text. Previous works on text revision have focused on defining edit intention taxonomies within a single domain or developing computational models with a single level of edit granularity, such as sentence-level edits, which differ from human's revision cycles. This work describes IteraTeR: the first large-scale, multi-domain, edit-intention annotated corpus of iteratively revised text. In particular, IteraTeR is collected based on a new framework to comprehensively model the iterative text revisions that generalize to various domains of formal writing, edit intentions, revision depths, and granularities. When we incorporate our annotated edit intentions, both generative and edit-based text revision models significantly improve automatic evaluations. Through our work, we better understand the text revision process, making vital connections between edit intentions and writing quality, enabling the creation of diverse corpora to support computational modeling of iterative text revisions.