 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Class Separation Distance for the Evaluation of Corruption Robustness of Machine Learning Classifiers
Jun 27, 2022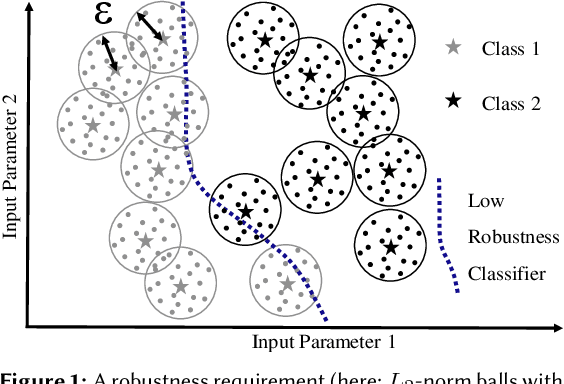

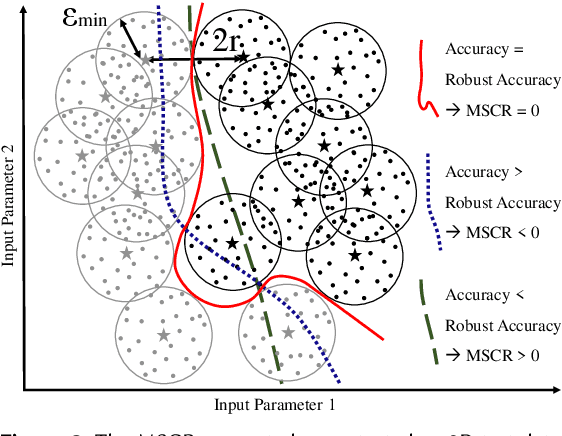
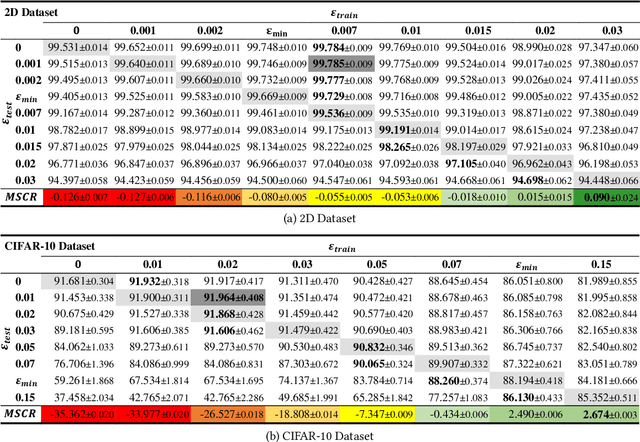
Robustness is a fundamental pillar of Machine Learning (ML) classifiers, substantially determining their reliability. Methods for assessing classifier robustness are therefore essential. In this work, we address the challenge of evaluating corruption robustness in a way that allows comparability and interpretability on a given dataset. We propose a test data augmentation method that uses a robustness distance $\epsilon$ derived from the datasets minimal class separation distance. The resulting MSCR (mean statistical corruption robustness) metric allows a dataset-specific comparison of different classifiers with respect to their corruption robustness. The MSCR value is interpretable, as it represents the classifiers avoidable loss of accuracy due to statistical corruptions. On 2D and image data, we show that the metric reflects different levels of classifier robustness. Furthermore, we observe unexpected optima in classifiers robust accuracy through training and testing classifiers with different levels of noise. While researchers have frequently reported on a significant tradeoff on accuracy when training robust models, we strengthen the view that a tradeoff between accuracy and corruption robustness is not inherent. Our results indicate that robustness training through simple data augmentation can already slightly improve accuracy.
Metaheuristics "In the Large"
Dec 18, 2020Following decades of sustained improvement, metaheuristics are one of the great success stories of optimization research. However, in order for research in metaheuristics to avoid fragmentation and a lack of reproducibility, there is a pressing need for stronger scientific and computational infrastructure to support the development, analysis and comparison of new approaches. We argue that, via principled choice of infrastructure support, the field can pursue a higher level of scientific enquiry. We describe our vision and report on progress, showing how the adoption of common protocols for all metaheuristics can help liberate the potential of the field, easing the exploration of the design space of metaheuristics.
From Digitalization to Data-Driven Decision Making in Container Terminals
Apr 29, 2019



With the new opportunities emerging from the current wave of digitalization, terminal planning and management need to be revisited by taking a data-driven perspective. Business analytics, as a practice of extracting insights from operational data, assists in reducing uncertainties using predictions and helps to identify and understand causes of inefficiencies, disruptions, and anomalies in intra- and inter-organizational terminal operations. Despite the growing complexity of data within and around container terminals, a lack of data-driven approaches in the context of container terminals can be identified. In this chapter, the concept of business analytics for supporting terminal planning and management is introduced. The chapter specifically focuses on data mining approaches and provides a comprehensive overview on applications in container terminals and related research. As such, we aim to establish a data-driven perspective on terminal planning and management, complementing the traditional optimization perspective.