 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Synthetic Augmentation further improves Corruption Robustness
Dec 19, 2025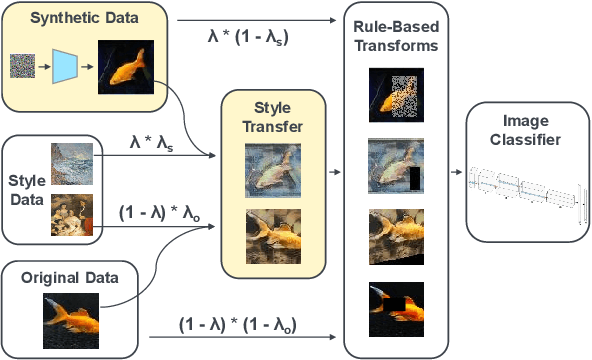

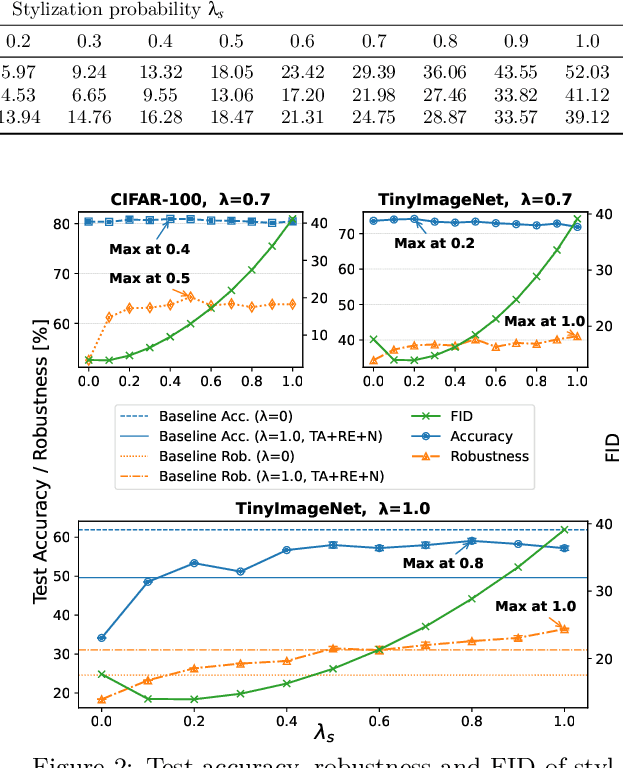
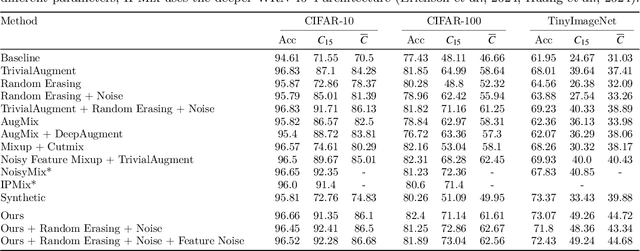
This paper proposes a training data augmentation pipeline that combines synthetic image data with neural style transfer in order to address the vulnerability of deep vision models to common corruptions. We show that although applying style transfer on synthetic images degrades their quality with respect to the common Frechet Inception Distance (FID) metric, these images are surprisingly beneficial for model training. We conduct a systematic empirical analysis of the effects of both augmentations and their key hyperparameters on the performance of image classifiers. Our results demonstrate that stylization and synthetic data complement each other well and can be combined with popular rule-based data augmentation techniques such as TrivialAugment, while not working with others. Our method achieves state-of-the-art corruption robustness on several small-scale image classification benchmarks, reaching 93.54%, 74.9% and 50.86% robust accuracy on CIFAR-10-C, CIFAR-100-C and TinyImageNet-C, respectively
Combined Image Data Augmentations diminish the benefits of Adaptive Label Smoothing
Jul 22, 2025Soft augmentation regularizes the supervised learning process of image classifiers by reducing label confidence of a training sample based on the magnitude of random-crop augmentation applied to it. This paper extends this adaptive label smoothing framework to other types of aggressive augmentations beyond random-crop. Specifically, we demonstrate the effectiveness of the method for random erasing and noise injection data augmentation. Adaptive label smoothing permits stronger regularization via higher-intensity Random Erasing. However, its benefits vanish when applied with a diverse range of image transformations as in the state-of-the-art TrivialAugment method, and excessive label smoothing harms robustness to common corruptions. Our findings suggest that adaptive label smoothing should only be applied when the training data distribution is dominated by a limited, homogeneous set of image transformation types.
Dynamic Risk Assessment for Human-Robot Collaboration Using a Heuristics-based Approach
Mar 11, 2025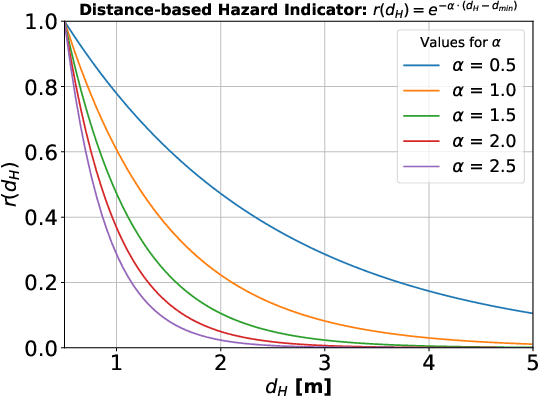



Human-robot collaboration (HRC) introduces significant safety challenges, particularly in protecting human operators working alongside collaborative robots (cobots). While current ISO standards emphasize risk assessment and hazard identification, these procedures are often insufficient for addressing the complexity of HRC environments, which involve numerous design factors and dynamic interactions. This publication presents a method for objective hazard analysis to support Dynamic Risk Assessment, extending beyond reliance on expert knowledge. The approach monitors scene parameters, such as the distance between human body parts and the cobot, as well as the cobot`s Cartesian velocity. Additionally, an anthropocentric parameter focusing on the orientation of the human head within the collaborative workspace is introduced. These parameters are transformed into hazard indicators using non-linear heuristic functions. The hazard indicators are then aggregated to estimate the total hazard level of a given scenario. The proposed method is evaluated using an industrial dataset that depicts various interactions between a human operator and a cobot.
Investigating the Corruption Robustness of Image Classifiers with Random Lp-norm Corruptions
May 09, 2023Robustness is a fundamental property of machine learning classifiers to achieve safety and reliability. In the fields of adversarial robustness and formal robustness verification of image classification models, robustness is commonly defined as the stability to all input variations within an Lp-norm distance. However, robustness to random corruptions is usually improved and evaluated using variations observed in the real-world, while mathematically defined Lp-norm corruptions are rarely considered. This study investigates the use of random Lp-norm corruptions to augment the training and test data of image classifiers. We adapt an approach from the field of adversarial robustness to assess the model robustness to imperceptible random corruptions. We empirically and theoretically investigate whether robustness is transferable across different Lp-norms and derive conclusions on which Lp-norm corruptions a model should be trained and evaluated on. We find that training data augmentation with L0-norm corruptions improves corruption robustness while maintaining accuracy compared to standard training and when applied on top of selected state-of-the-art data augmentation techniques.
Utilizing Class Separation Distance for the Evaluation of Corruption Robustness of Machine Learning Classifiers
Jun 27, 2022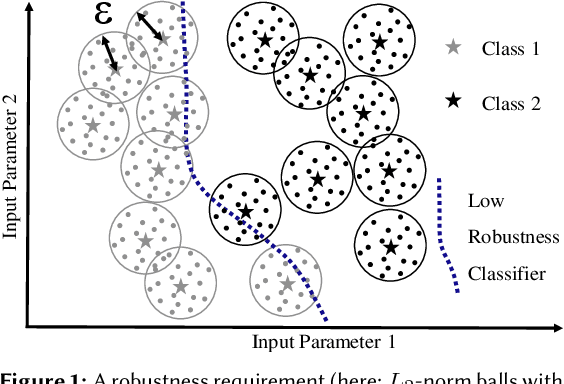

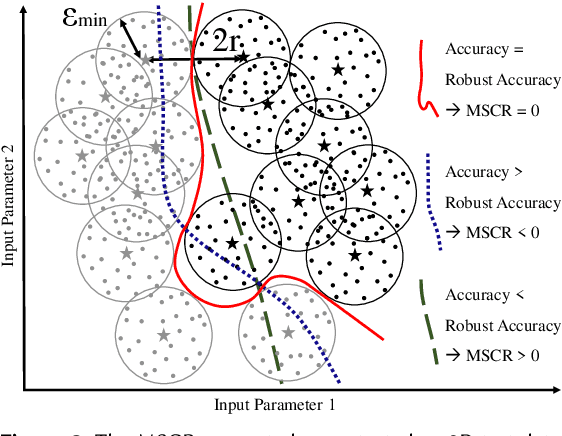
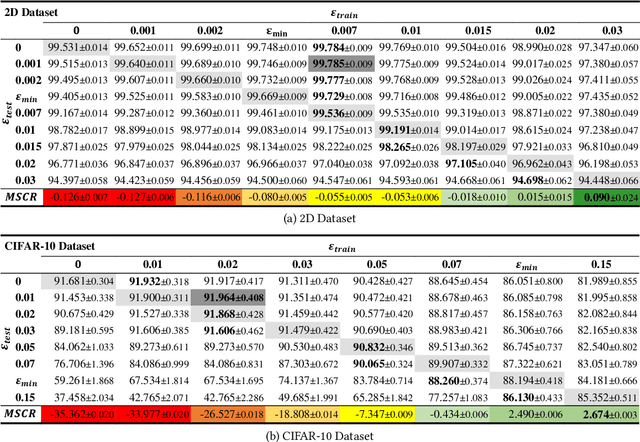
Robustness is a fundamental pillar of Machine Learning (ML) classifiers, substantially determining their reliability. Methods for assessing classifier robustness are therefore essential. In this work, we address the challenge of evaluating corruption robustness in a way that allows comparability and interpretability on a given dataset. We propose a test data augmentation method that uses a robustness distance $\epsilon$ derived from the datasets minimal class separation distance. The resulting MSCR (mean statistical corruption robustness) metric allows a dataset-specific comparison of different classifiers with respect to their corruption robustness. The MSCR value is interpretable, as it represents the classifiers avoidable loss of accuracy due to statistical corruptions. On 2D and image data, we show that the metric reflects different levels of classifier robustness. Furthermore, we observe unexpected optima in classifiers robust accuracy through training and testing classifiers with different levels of noise. While researchers have frequently reported on a significant tradeoff on accuracy when training robust models, we strengthen the view that a tradeoff between accuracy and corruption robustness is not inherent. Our results indicate that robustness training through simple data augmentation can already slightly improve accuracy.