 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchrony begets Momentum, with an Application to Deep Learning
Nov 25, 2016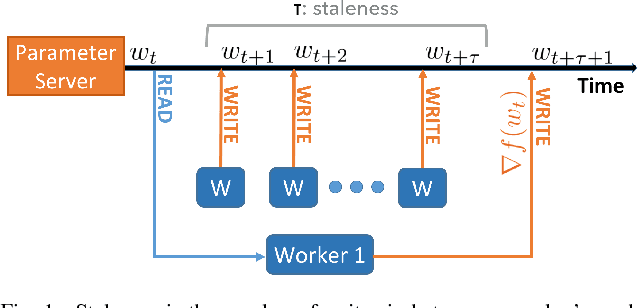

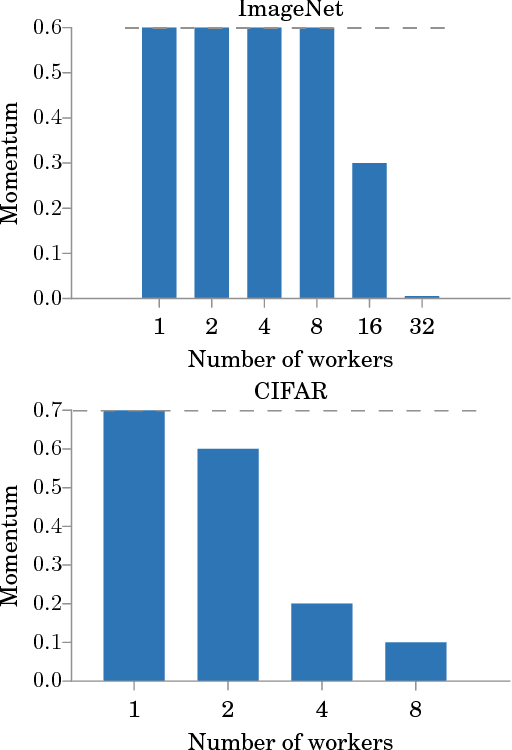
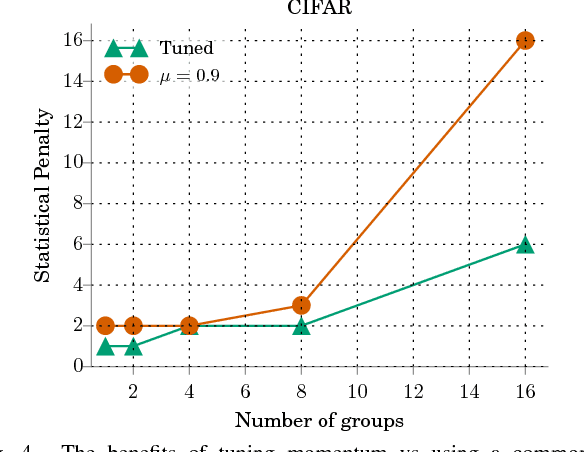
Asynchronous methods are widely used in deep learning, but have limited theoretical justification when applied to non-convex problems. We show that running stochastic gradient descent (SGD) in an asynchronous manner can be viewed as adding a momentum-like term to the SGD iteration. Our result does not assume convexity of the objective function, so it is applicable to deep learning systems. We observe that a standard queuing model of asynchrony results in a form of momentum that is commonly used by deep learning practitioners. This forges a link between queuing theory and asynchrony in deep learning systems, which could be useful for systems builders. For convolutional neural networks, we experimentally validate that the degree of asynchrony directly correlates with the momentum, confirming our main result. An important implication is that tuning the momentum parameter is important when considering different levels of asynchrony. We assert that properly tuned momentum reduces the number of steps required for convergence. Finally, our theory suggests new ways of counteracting the adverse effects of asynchrony: a simple mechanism like using negative algorithmic momentum can improve performance under high asynchrony. Since asynchronous methods have better hardware efficiency, this result may shed light on when asynchronous execution is more efficient for deep learning systems.
Omnivore: An Optimizer for Multi-device Deep Learning on CPUs and GPUs
Oct 19, 2016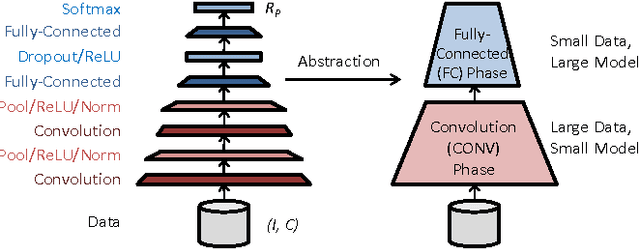
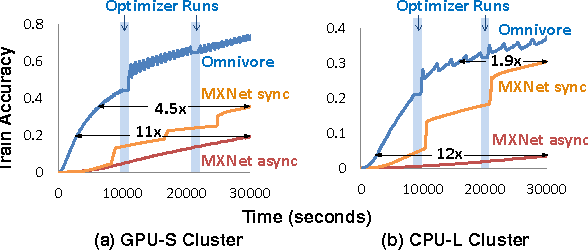

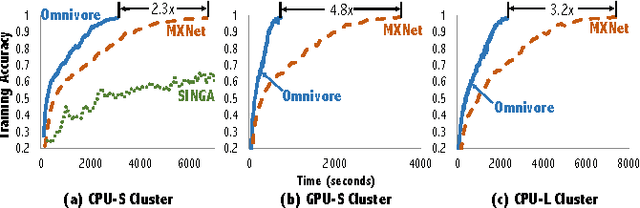
We study the factors affecting training time in multi-device deep learning systems. Given a specification of a convolutional neural network, our goal is to minimize the time to train this model on a cluster of commodity CPUs and GPUs. We first focus on the single-node setting and show that by using standard batching and data-parallel techniques, throughput can be improved by at least 5.5x over state-of-the-art systems on CPUs. This ensures an end-to-end training speed directly proportional to the throughput of a device regardless of its underlying hardware, allowing each node in the cluster to be treated as a black box. Our second contribution is a theoretical and empirical study of the tradeoffs affecting end-to-end training time in a multiple-device setting. We identify the degree of asynchronous parallelization as a key factor affecting both hardware and statistical efficiency. We see that asynchrony can be viewed as introducing a momentum term. Our results imply that tuning momentum is critical in asynchronous parallel configurations, and suggest that published results that have not been fully tuned might report suboptimal performance for some configurations. For our third contribution, we use our novel understanding of the interaction between system and optimization dynamics to provide an efficient hyperparameter optimizer. Our optimizer involves a predictive model for the total time to convergence and selects an allocation of resources to minimize that time. We demonstrate that the most popular distributed deep learning systems fall within our tradeoff space, but do not optimize within the space. By doing this optimization, our prototype runs 1.9x to 12x faster than the fastest state-of-the-art systems.
Caffe con Troll: Shallow Ideas to Speed Up Deep Learning
May 26, 2015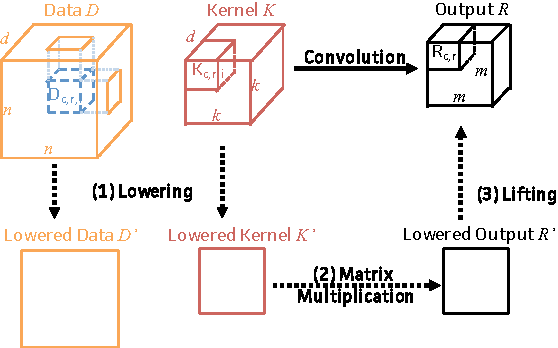
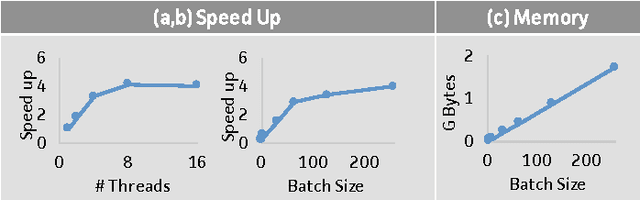
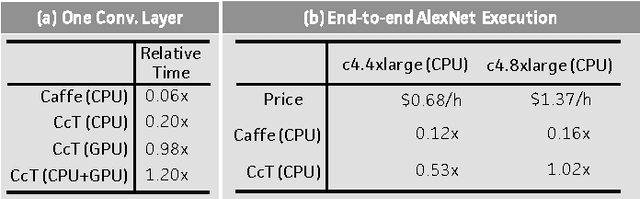
We present Caffe con Troll (CcT), a fully compatible end-to-end version of the popular framework Caffe with rebuilt internals. We built CcT to examine the performance characteristics of training and deploying general-purpose convolutional neural networks across different hardware architectures. We find that, by employing standard batching optimizations for CPU training, we achieve a 4.5x throughput improvement over Caffe on popular networks like CaffeNet. Moreover, with these improvements, the end-to-end training time for CNNs is directly proportional to the FLOPS delivered by the CPU, which enables us to efficiently train hybrid CPU-GPU systems for CNNs.