 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnivore: An Optimizer for Multi-device Deep Learning on CPUs and GPUs
Paper and Code
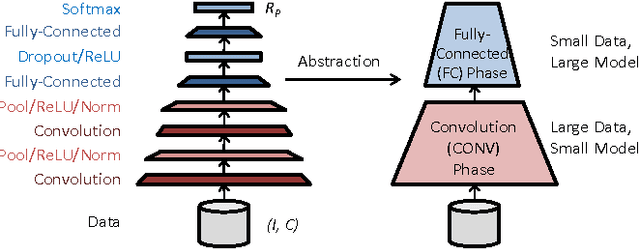
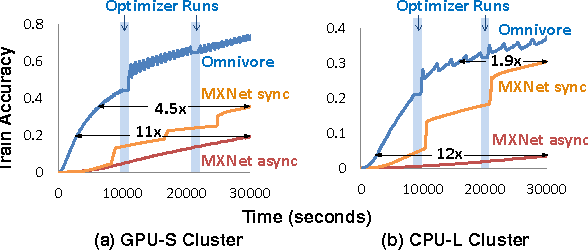

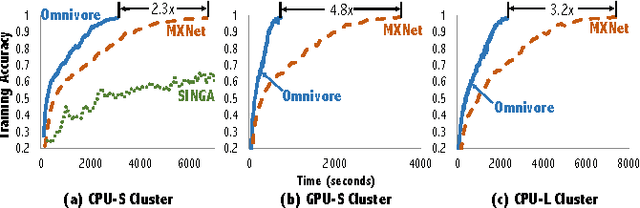
We study the factors affecting training time in multi-device deep learning systems. Given a specification of a convolutional neural network, our goal is to minimize the time to train this model on a cluster of commodity CPUs and GPUs. We first focus on the single-node setting and show that by using standard batching and data-parallel techniques, throughput can be improved by at least 5.5x over state-of-the-art systems on CPUs. This ensures an end-to-end training speed directly proportional to the throughput of a device regardless of its underlying hardware, allowing each node in the cluster to be treated as a black box. Our second contribution is a theoretical and empirical study of the tradeoffs affecting end-to-end training time in a multiple-device setting. We identify the degree of asynchronous parallelization as a key factor affecting both hardware and statistical efficiency. We see that asynchrony can be viewed as introducing a momentum term. Our results imply that tuning momentum is critical in asynchronous parallel configurations, and suggest that published results that have not been fully tuned might report suboptimal performance for some configurations. For our third contribution, we use our novel understanding of the interaction between system and optimization dynamics to provide an efficient hyperparameter optimizer. Our optimizer involves a predictive model for the total time to convergence and selects an allocation of resources to minimize that time. We demonstrate that the most popular distributed deep learning systems fall within our tradeoff space, but do not optimize within the space. By doing this optimization, our prototype runs 1.9x to 12x faster than the fastest state-of-the-art systems.