Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaffe con Troll: Shallow Ideas to Speed Up Deep Learning
Paper and Code
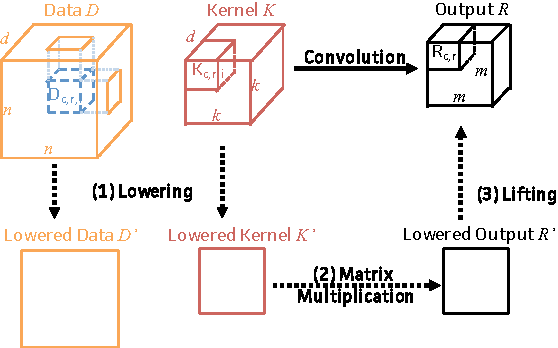
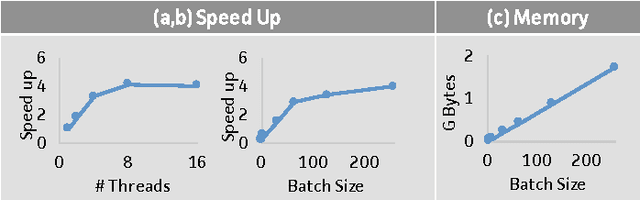
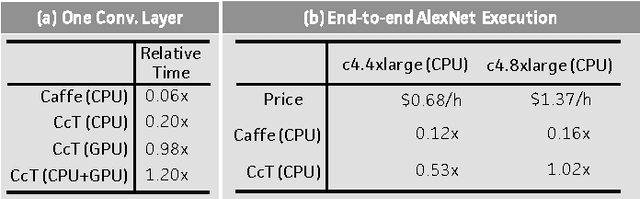
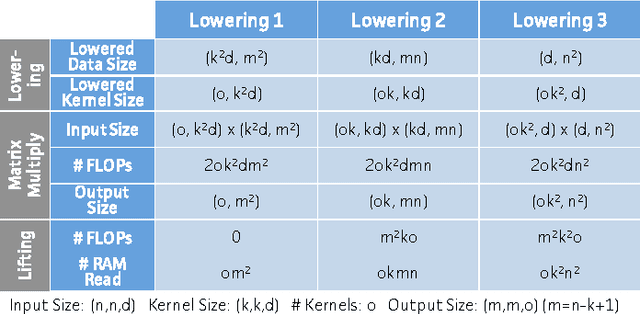
We present Caffe con Troll (CcT), a fully compatible end-to-end version of the popular framework Caffe with rebuilt internals. We built CcT to examine the performance characteristics of training and deploying general-purpose convolutional neural networks across different hardware architectures. We find that, by employing standard batching optimizations for CPU training, we achieve a 4.5x throughput improvement over Caffe on popular networks like CaffeNet. Moreover, with these improvements, the end-to-end training time for CNNs is directly proportional to the FLOPS delivered by the CPU, which enables us to efficiently train hybrid CPU-GPU systems for CNNs.
View paper on