 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality of Benign Overfitting in Binary Linear Classification
Jan 17, 2025
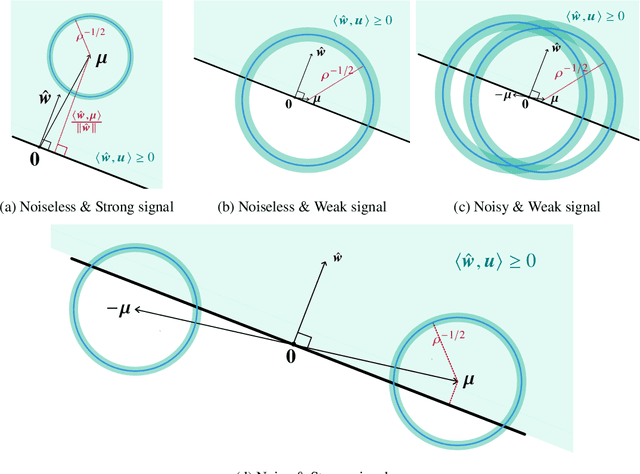
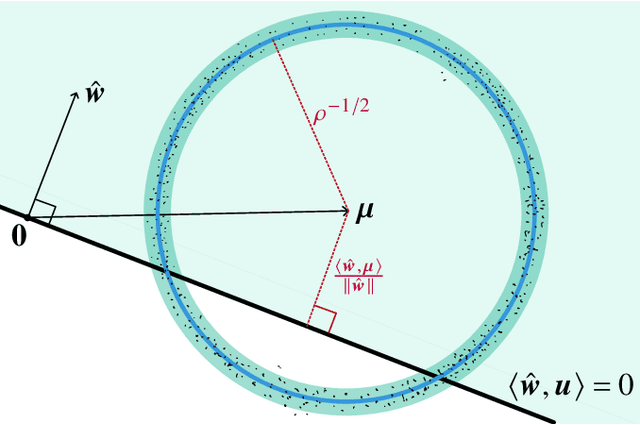
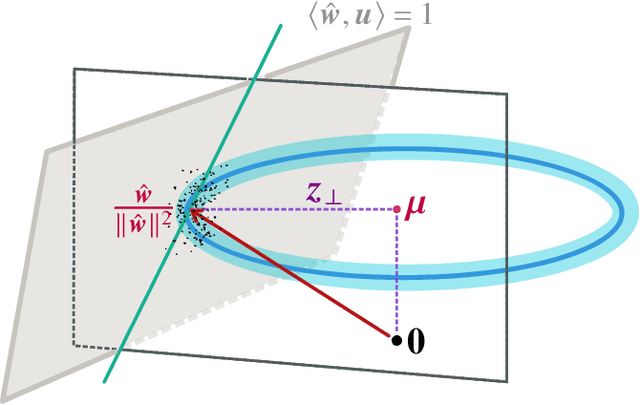
The practical success of deep learning has led to the discovery of several surprising phenomena. One of these phenomena, that has spurred intense theoretical research, is ``benign overfitting'': deep neural networks seem to generalize well in the over-parametrized regime even though the networks show a perfect fit to noisy training data. It is now known that benign overfitting also occurs in various classical statistical models. For linear maximum margin classifiers, benign overfitting has been established theoretically in a class of mixture models with very strong assumptions on the covariate distribution. However, even in this simple setting, many questions remain open. For instance, most of the existing literature focuses on the noiseless case where all true class labels are observed without errors, whereas the more interesting noisy case remains poorly understood. We provide a comprehensive study of benign overfitting for linear maximum margin classifiers. We discover a phase transition in test error bounds for the noisy model which was previously unknown and provide some geometric intuition behind it. We further considerably relax the required covariate assumptions in both, the noisy and noiseless case. Our results demonstrate that benign overfitting of maximum margin classifiers holds in a much wider range of scenarios than was previously known and provide new insights into the underlying mechanisms.
Mirror Descent Strikes Again: Optimal Stochastic Convex Optimization under Infinite Noise Variance
Feb 23, 2022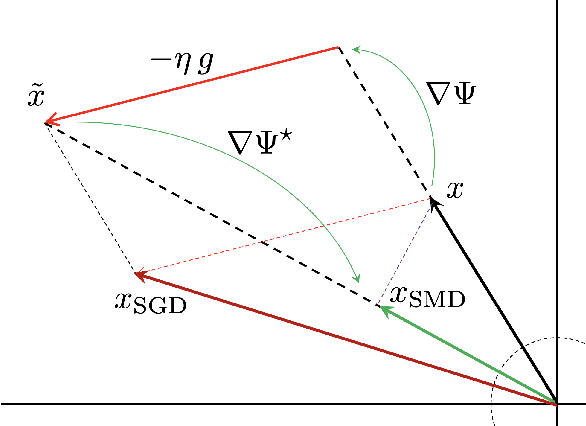
We study stochastic convex optimization under infinite noise variance. Specifically, when the stochastic gradient is unbiased and has uniformly bounded $(1+\kappa)$-th moment, for some $\kappa \in (0,1]$, we quantify the convergence rate of the Stochastic Mirror Descent algorithm with a particular class of uniformly convex mirror maps, in terms of the number of iterations, dimensionality and related geometric parameters of the optimization problem. Interestingly this algorithm does not require any explicit gradient clipping or normalization, which have been extensively used in several recent empirical and theoretical works. We complement our convergence results with information-theoretic lower bounds showing that no other algorithm using only stochastic first-order oracles can achieve improved rates. Our results have several interesting consequences for devising online/streaming stochastic approximation algorithms for problems arising in robust statistics and machine learning.
Group structure estimation for panel data -- a general approach
Jan 05, 2022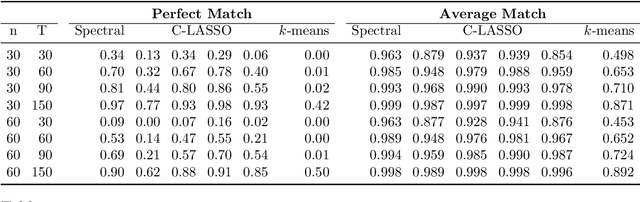
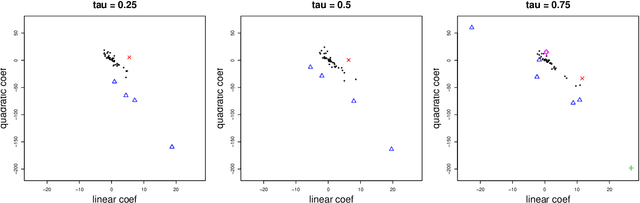
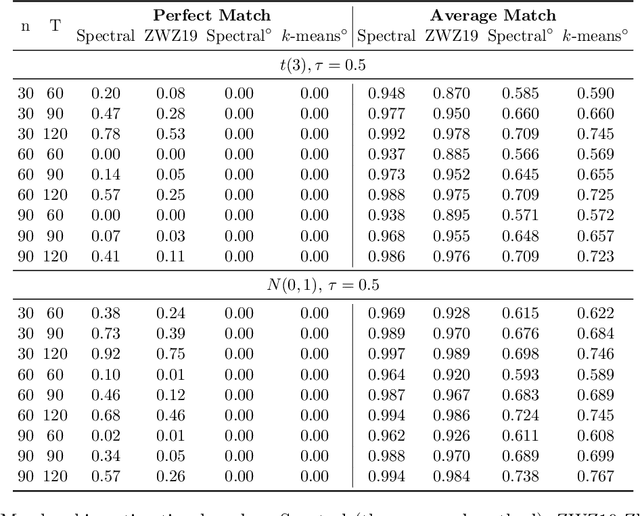
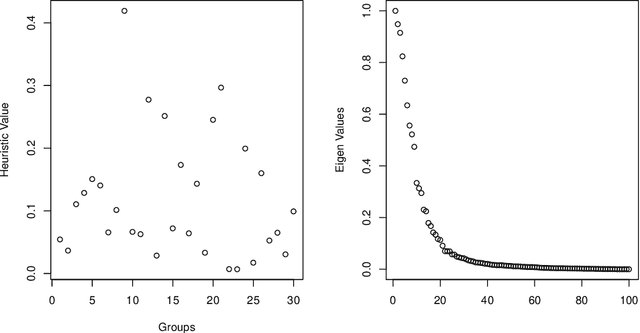
Consider a panel data setting where repeated observations on individuals are available. Often it is reasonable to assume that there exist groups of individuals that share similar effects of observed characteristics, but the grouping is typically unknown in advance. We propose a novel approach to estimate such unobserved groupings for general panel data models. Our method explicitly accounts for the uncertainty in individual parameter estimates and remains computationally feasible with a large number of individuals and/or repeated measurements on each individual. The developed ideas can be applied even when individual-level data are not available and only parameter estimates together with some quantification of uncertainty are given to the researcher.
An Analysis of Constant Step Size SGD in the Non-convex Regime: Asymptotic Normality and Bias
Jun 14, 2020
Structured non-convex learning problems, for which critical points have favorable statistical properties, arise frequently in statistical machine learning. Algorithmic convergence and statistical estimation rates are well-understood for such problems. However, quantifying the uncertainty associated with the underlying training algorithm is not well-studied in the non-convex setting. In order to address this shortcoming, in this work, we establish an asymptotic normality result for the constant step size stochastic gradient descent (SGD) algorithm--a widely used algorithm in practice. Specifically, based on the relationship between SGD and Markov Chains [DDB19], we show that the average of SGD iterates is asymptotically normally distributed around the expected value of their unique invariant distribution, as long as the non-convex and non-smooth objective function satisfies a dissipativity property. We also characterize the bias between this expected value and the critical points of the objective function under various local regularity conditions. Together, the above two results could be leveraged to construct confidence intervals for non-convex problems that are trained using the SGD algorithm.