 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Optimization in Large Scale Federated Learning using Autoencoder Compressed Weight Updates
Aug 12, 2021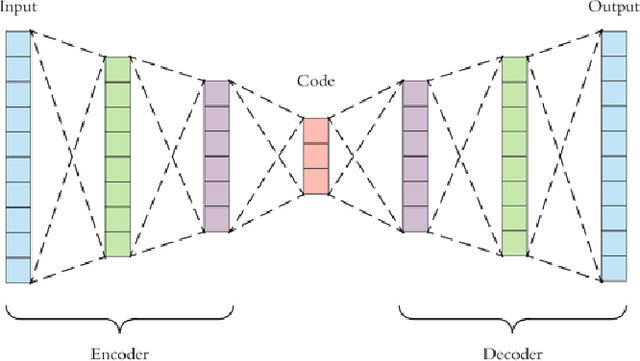
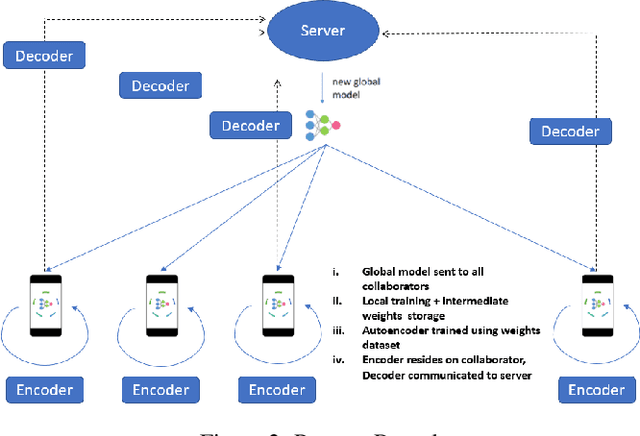
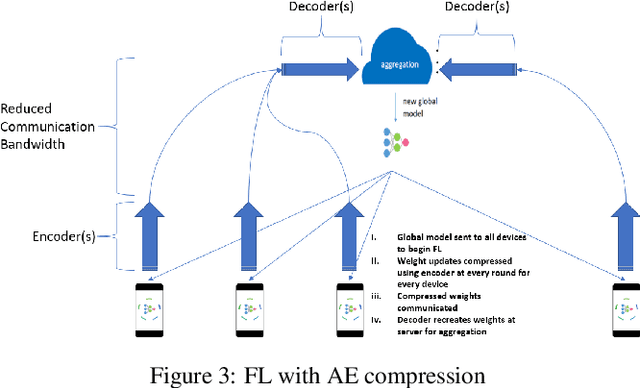

Federated Learning (FL) solves many of this decade's concerns regarding data privacy and computation challenges. FL ensures no data leaves its source as the model is trained at where the data resides. However, FL comes with its own set of challenges. The communication of model weight updates in this distributed environment comes with significant network bandwidth costs. In this context, we propose a mechanism of compressing the weight updates using Autoencoders (AE), which learn the data features of the weight updates and subsequently perform compression. The encoder is set up on each of the nodes where the training is performed while the decoder is set up on the node where the weights are aggregated. This setup achieves compression through the encoder and recreates the weights at the end of every communication round using the decoder. This paper shows that the dynamic and orthogonal AE based weight compression technique could serve as an advantageous alternative (or an add-on) in a large scale FL, as it not only achieves compression ratios ranging from 500x to 1720x and beyond, but can also be modified based on the accuracy requirements, computational capacity, and other requirements of the given FL setup.
Weight Divergence Driven Divide-and-Conquer Approach for Optimal Federated Learning from non-IID Data
Jun 30, 2021

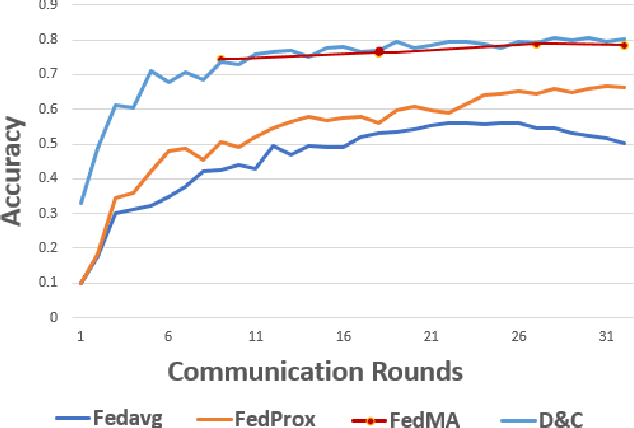
Federated Learning allows training of data stored in distributed devices without the need for centralizing training data, thereby maintaining data privacy. Addressing the ability to handle data heterogeneity (non-identical and independent distribution or non-IID) is a key enabler for the wider deployment of Federated Learning. In this paper, we propose a novel Divide-and-Conquer training methodology that enables the use of the popular FedAvg aggregation algorithm by overcoming the acknowledged FedAvg limitations in non-IID environments. We propose a novel use of Cosine-distance based Weight Divergence metric to determine the exact point where a Deep Learning network can be divided into class agnostic initial layers and class-specific deep layers for performing a Divide and Conquer training. We show that the methodology achieves trained model accuracy at par (and in certain cases exceeding) with numbers achieved by state-of-the-art Aggregation algorithms like FedProx, FedMA, etc. Also, we show that this methodology leads to compute and bandwidth optimizations under certain documented conditions.
AI based Presentation Creator With Customized Audio Content Delivery
Jun 27, 2021
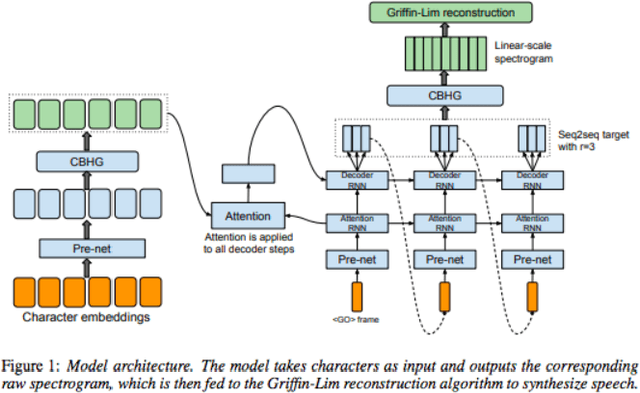
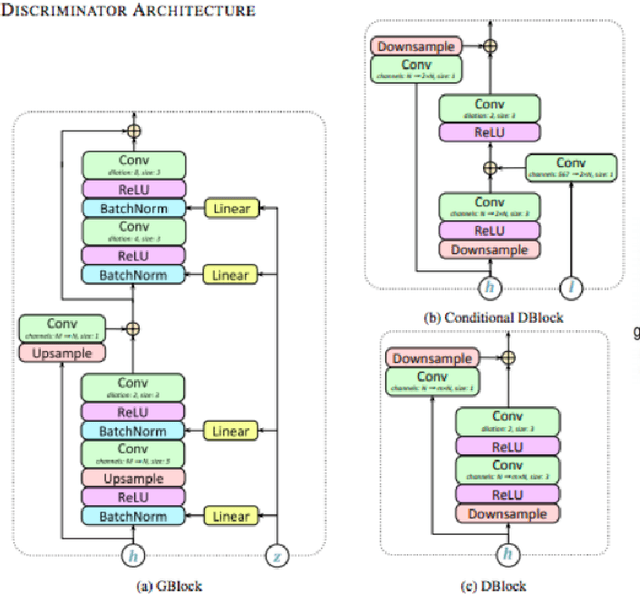
In this paper, we propose an architecture to solve a novel problem statement that has stemmed more so in recent times with an increase in demand for virtual content delivery due to the COVID-19 pandemic. All educational institutions, workplaces, research centers, etc. are trying to bridge the gap of communication during these socially distanced times with the use of online content delivery. The trend now is to create presentations, and then subsequently deliver the same using various virtual meeting platforms. The time being spent in such creation of presentations and delivering is what we try to reduce and eliminate through this paper which aims to use Machine Learning (ML) algorithms and Natural Language Processing (NLP) modules to automate the process of creating a slides-based presentation from a document, and then use state-of-the-art voice cloning models to deliver the content in the desired author's voice. We consider a structured document such as a research paper to be the content that has to be presented. The research paper is first summarized using BERT summarization techniques and condensed into bullet points that go into the slides. Tacotron inspired architecture with Encoder, Synthesizer, and a Generative Adversarial Network (GAN) based vocoder, is used to convey the contents of the slides in the author's voice (or any customized voice). Almost all learning has now been shifted to online mode, and professionals are now working from the comfort of their homes. Due to the current situation, teachers and professionals have shifted to presentations to help them in imparting information. In this paper, we aim to reduce the considerable amount of time that is taken in creating a presentation by automating this process and subsequently delivering this presentation in a customized voice, using a content delivery mechanism that can clone any voice using a short audio clip.
Machine Learning Based Network Coverage Guidance System
Oct 25, 2020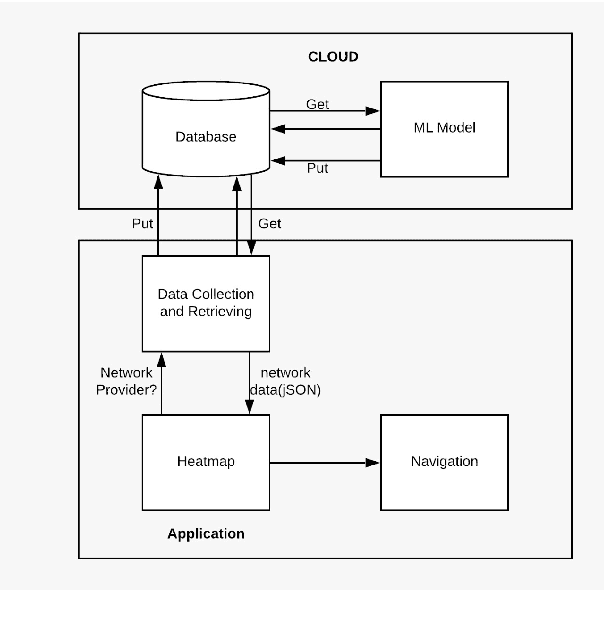
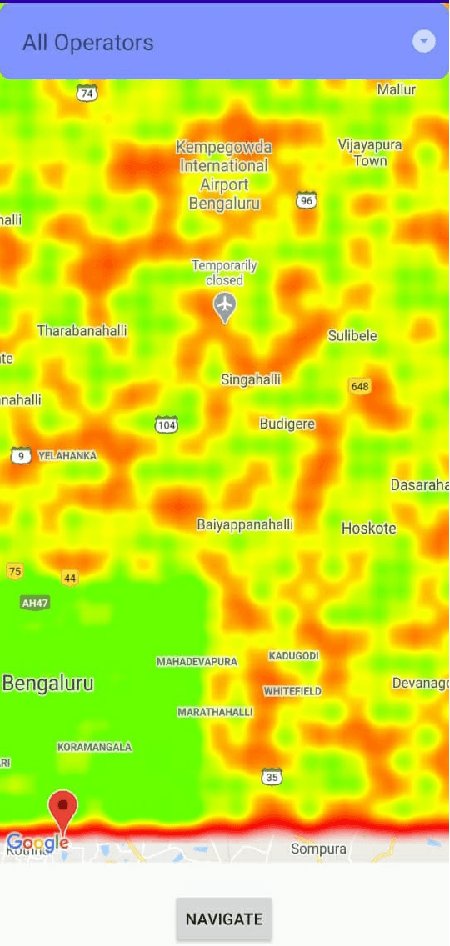
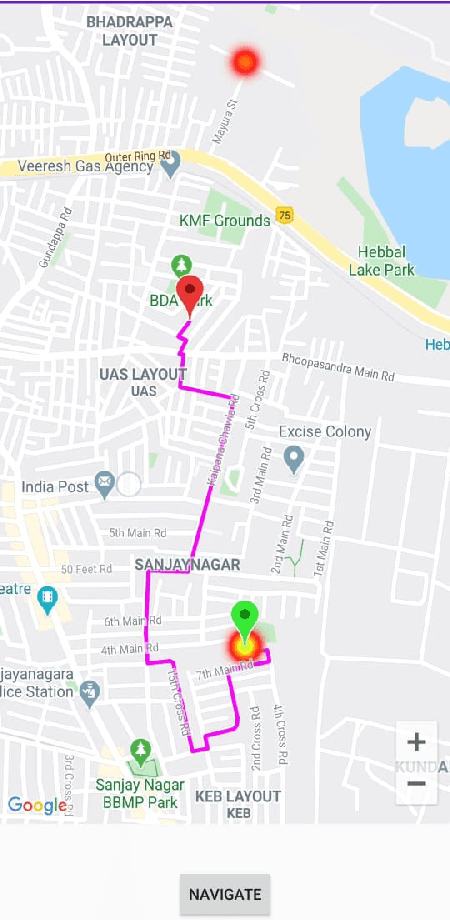
With the advent of 4G, there has been a huge consumption of data and the availability of mobile networks has become paramount. Also, with the burst of network traffic based on user consumption, data availability and network anomalies have increased substantially. In this paper, we introduce a novel approach, to identify the regions that have poor network connectivity thereby providing feedback to both the service providers to improve the coverage as well as to the customers to choose the network judiciously. In addition to this, the solution enables customers to navigate to a better mobile network coverage area with stronger signal strength location using Machine Learning Clustering Algorithms, whilst deploying it as a Mobile Application. It also provides a dynamic visual representation of varying network strength and range across nearby geographical areas.
Road Accident Proneness Indicator Based On Time, Weather And Location Specificity Using Graph Neural Networks
Oct 24, 2020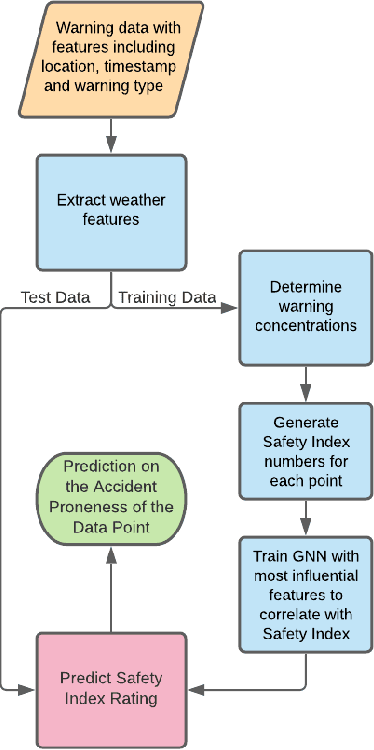
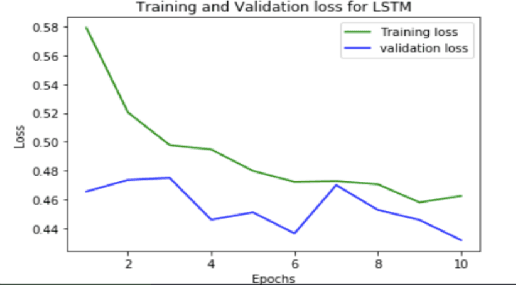
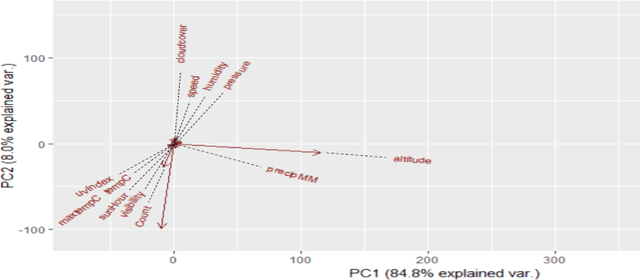
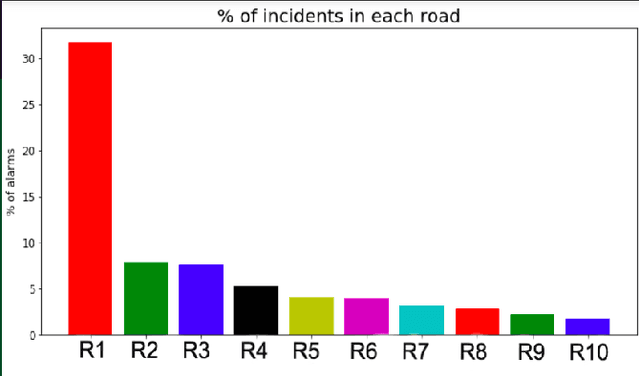
In this paper, we present a novel approach to identify the Spatio-temporal and environmental features that influence the safety of a road and predict its accident proneness based on these features. A total of 14 features were compiled based on Time, Weather, and Location (TWL) specificity along a road. To determine the influence each of the 14 features carries, a sensitivity study was performed using Principal Component Analysis. Using the locations of accident warnings, a Safety Index was developed to quantify how accident-prone a particular road is. We implement a novel approach to predict the Safety Index of a road-based on its TWL specificity by using a Graph Neural Network (GNN) architecture. The proposed architecture is uniquely suited for this application due to its ability to capture the complexities of the inherent nonlinear interlinking in a vast feature space. We employed a GNN to emulate the TWL feature vectors as individual nodes which were interlinked vis-\`a-vis edges of a graph. This model was verified to perform better than Logistic Regression, simple Feed-Forward Neural Networks, and even Long Short Term Memory (LSTM) Neural Networks. We validated our approach on a data set containing the alert locations along the routes of inter-state buses. The results achieved through this GNN architecture, using a TWL input feature space proved to be more feasible than the other predictive models, having reached a peak accuracy of 65%.
Dynamic Systems Simulation and Control Using Consecutive Recurrent Neural Networks
Feb 25, 2020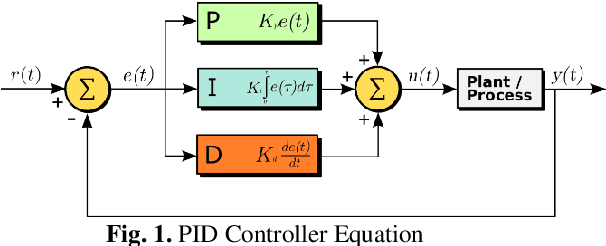

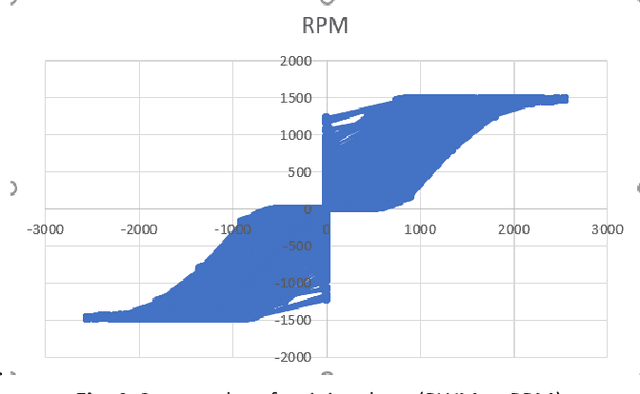
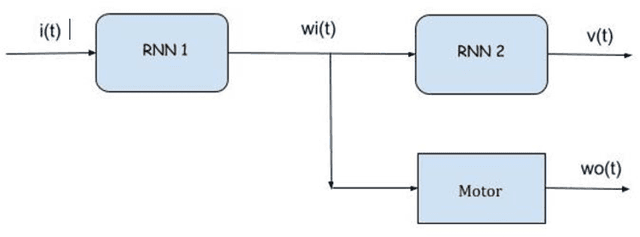
In this paper, we introduce a novel architecture to connecting adaptive learning and neural networks into an arbitrary machine's control system paradigm. Two consecutive Recurrent Neural Networks (RNNs) are used together to accurately model the dynamic characteristics of electromechanical systems that include controllers, actuators and motors. The age-old method of achieving control with the use of the- Proportional, Integral and Derivative constants is well understood as a simplified method that does not capture the complexities of the inherent nonlinearities of complex control systems. In the context of controlling and simulating electromechanical systems, we propose an alternative to PID controllers, employing a sequence of two Recurrent Neural Networks. The first RNN emulates the behavior of the controller, and the second the actuator/motor. The second RNN when used in isolation, potentially serves as an advantageous alternative to extant testing methods of electromechanical systems.