 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Optimization in Large Scale Federated Learning using Autoencoder Compressed Weight Updates
Paper and Code
Aug 12, 2021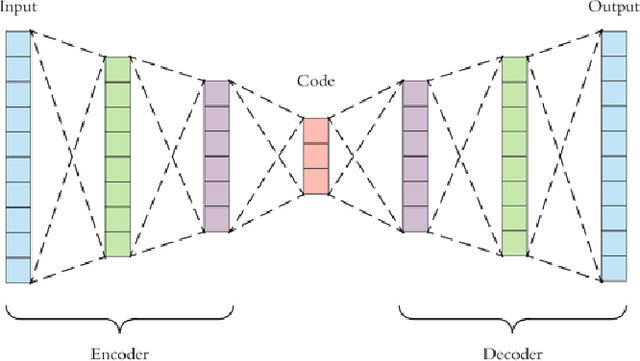
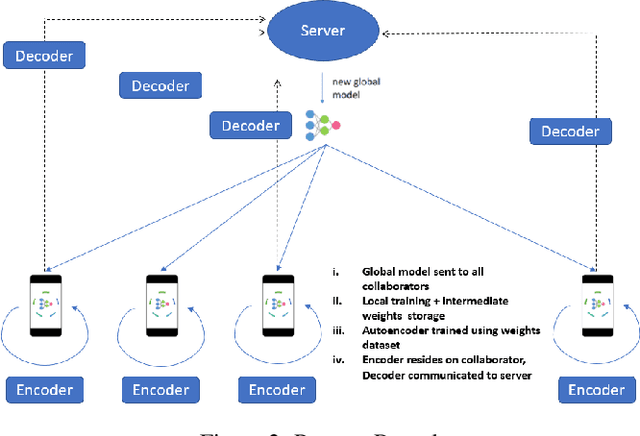
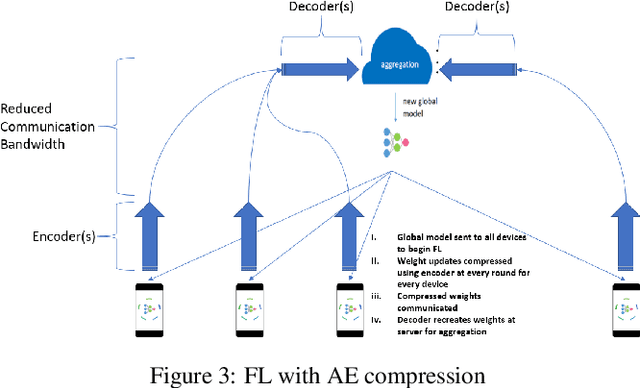

Federated Learning (FL) solves many of this decade's concerns regarding data privacy and computation challenges. FL ensures no data leaves its source as the model is trained at where the data resides. However, FL comes with its own set of challenges. The communication of model weight updates in this distributed environment comes with significant network bandwidth costs. In this context, we propose a mechanism of compressing the weight updates using Autoencoders (AE), which learn the data features of the weight updates and subsequently perform compression. The encoder is set up on each of the nodes where the training is performed while the decoder is set up on the node where the weights are aggregated. This setup achieves compression through the encoder and recreates the weights at the end of every communication round using the decoder. This paper shows that the dynamic and orthogonal AE based weight compression technique could serve as an advantageous alternative (or an add-on) in a large scale FL, as it not only achieves compression ratios ranging from 500x to 1720x and beyond, but can also be modified based on the accuracy requirements, computational capacity, and other requirements of the given FL setup.