 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI based Presentation Creator With Customized Audio Content Delivery
Paper and Code
Jun 27, 2021
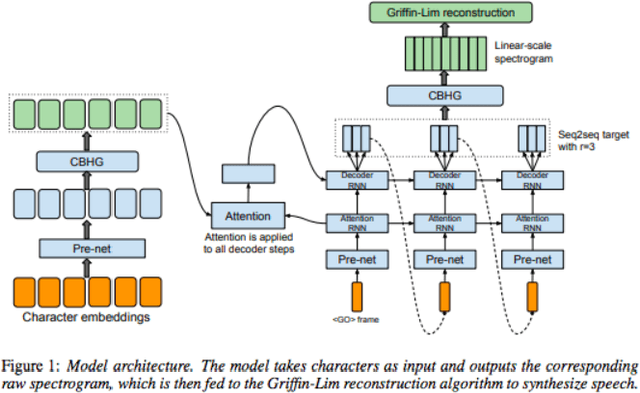
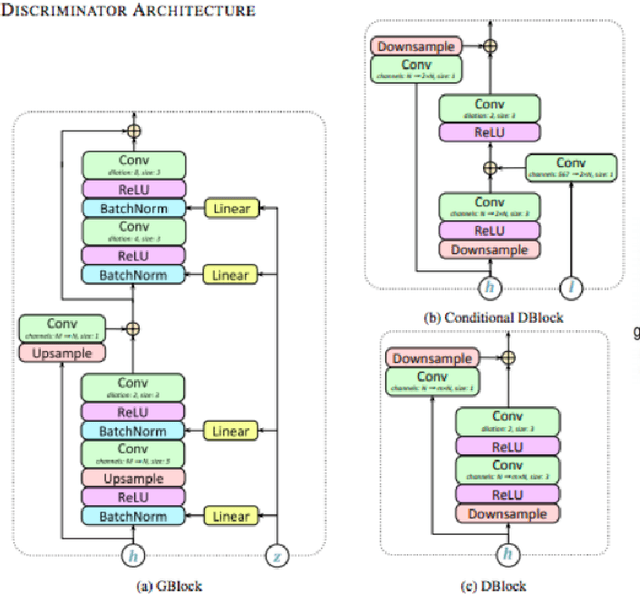
In this paper, we propose an architecture to solve a novel problem statement that has stemmed more so in recent times with an increase in demand for virtual content delivery due to the COVID-19 pandemic. All educational institutions, workplaces, research centers, etc. are trying to bridge the gap of communication during these socially distanced times with the use of online content delivery. The trend now is to create presentations, and then subsequently deliver the same using various virtual meeting platforms. The time being spent in such creation of presentations and delivering is what we try to reduce and eliminate through this paper which aims to use Machine Learning (ML) algorithms and Natural Language Processing (NLP) modules to automate the process of creating a slides-based presentation from a document, and then use state-of-the-art voice cloning models to deliver the content in the desired author's voice. We consider a structured document such as a research paper to be the content that has to be presented. The research paper is first summarized using BERT summarization techniques and condensed into bullet points that go into the slides. Tacotron inspired architecture with Encoder, Synthesizer, and a Generative Adversarial Network (GAN) based vocoder, is used to convey the contents of the slides in the author's voice (or any customized voice). Almost all learning has now been shifted to online mode, and professionals are now working from the comfort of their homes. Due to the current situation, teachers and professionals have shifted to presentations to help them in imparting information. In this paper, we aim to reduce the considerable amount of time that is taken in creating a presentation by automating this process and subsequently delivering this presentation in a customized voice, using a content delivery mechanism that can clone any voice using a short audio clip.