 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI based Presentation Creator With Customized Audio Content Delivery
Jun 27, 2021
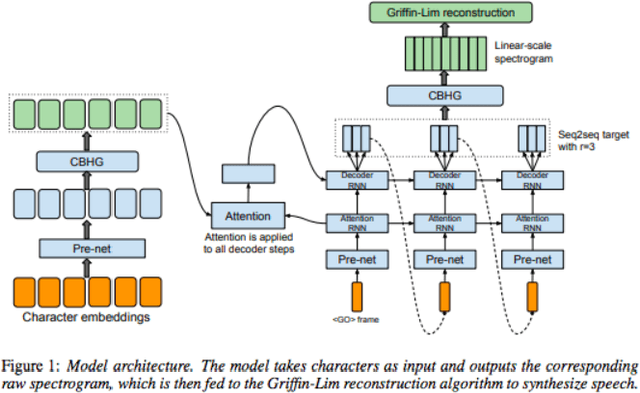
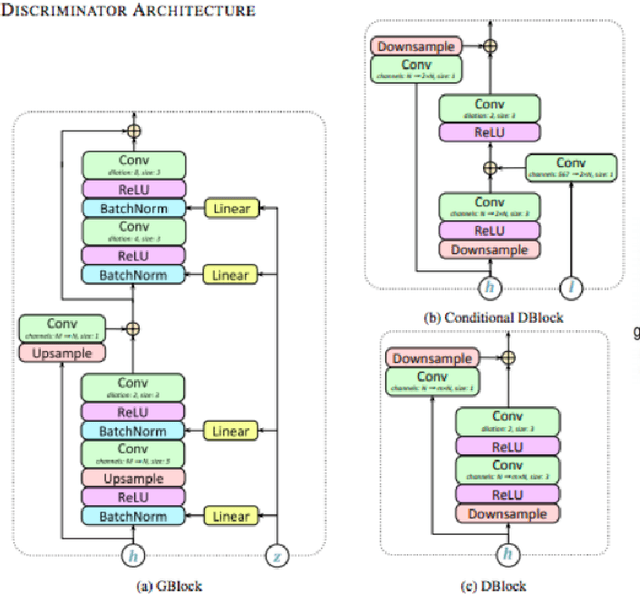
In this paper, we propose an architecture to solve a novel problem statement that has stemmed more so in recent times with an increase in demand for virtual content delivery due to the COVID-19 pandemic. All educational institutions, workplaces, research centers, etc. are trying to bridge the gap of communication during these socially distanced times with the use of online content delivery. The trend now is to create presentations, and then subsequently deliver the same using various virtual meeting platforms. The time being spent in such creation of presentations and delivering is what we try to reduce and eliminate through this paper which aims to use Machine Learning (ML) algorithms and Natural Language Processing (NLP) modules to automate the process of creating a slides-based presentation from a document, and then use state-of-the-art voice cloning models to deliver the content in the desired author's voice. We consider a structured document such as a research paper to be the content that has to be presented. The research paper is first summarized using BERT summarization techniques and condensed into bullet points that go into the slides. Tacotron inspired architecture with Encoder, Synthesizer, and a Generative Adversarial Network (GAN) based vocoder, is used to convey the contents of the slides in the author's voice (or any customized voice). Almost all learning has now been shifted to online mode, and professionals are now working from the comfort of their homes. Due to the current situation, teachers and professionals have shifted to presentations to help them in imparting information. In this paper, we aim to reduce the considerable amount of time that is taken in creating a presentation by automating this process and subsequently delivering this presentation in a customized voice, using a content delivery mechanism that can clone any voice using a short audio clip.
Global Sentiment Analysis Of COVID-19 Tweets Over Time
Nov 10, 2020



The Coronavirus pandemic has affected the normal course of life. People around the world have taken to social media to express their opinions and general emotions regarding this phenomenon that has taken over the world by storm. The social networking site, Twitter showed an unprecedented increase in tweets related to the novel Coronavirus in a very short span of time. This paper presents the global sentiment analysis of tweets related to Coronavirus and how the sentiment of people in different countries has changed over time. Furthermore, to determine the impact of Coronavirus on daily aspects of life, tweets related to Work From Home (WFH) and Online Learning were scraped and the change in sentiment over time was observed. In addition, various Machine Learning models such as Long Short Term Memory (LSTM) and Artificial Neural Networks (ANN) were implemented for sentiment classification and their accuracies were determined. Exploratory data analysis was also performed for a dataset providing information about the number of confirmed cases on a per-day basis in a few of the worst-hit countries to provide a comparison between the change in sentiment with the change in cases since the start of this pandemic till June 2020.
Machine Learning Based Network Coverage Guidance System
Oct 25, 2020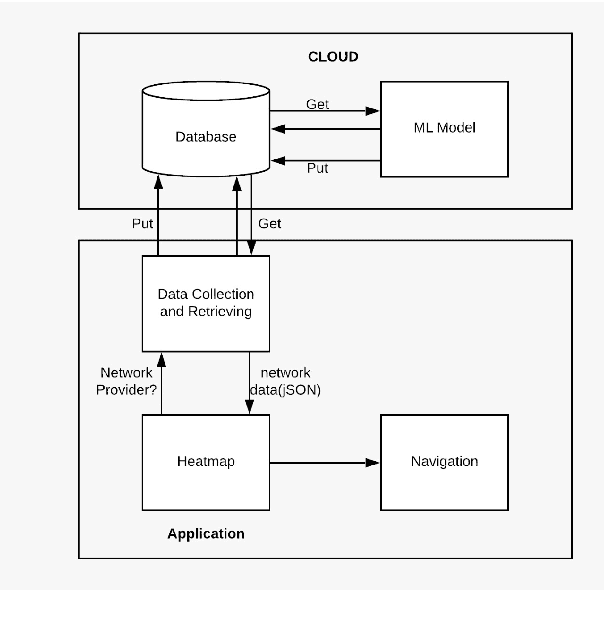
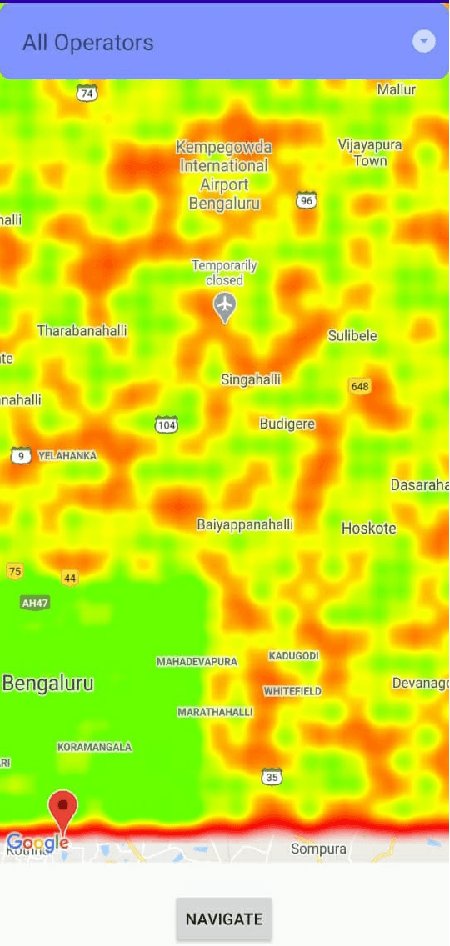
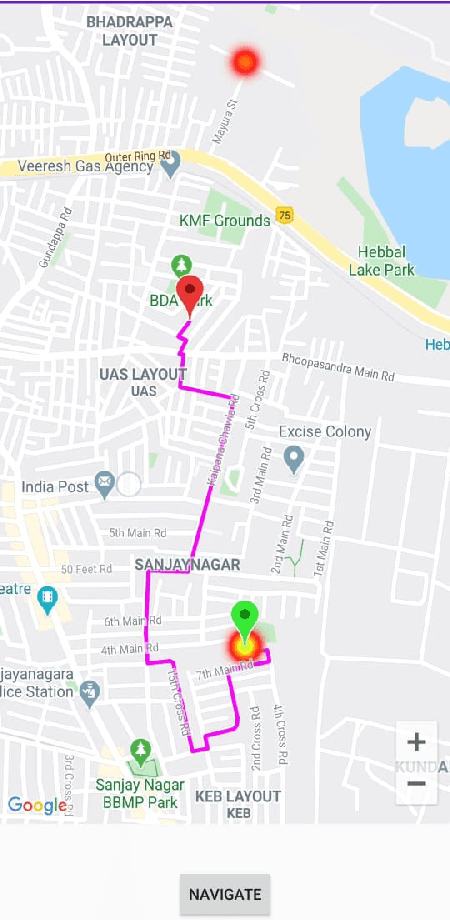
With the advent of 4G, there has been a huge consumption of data and the availability of mobile networks has become paramount. Also, with the burst of network traffic based on user consumption, data availability and network anomalies have increased substantially. In this paper, we introduce a novel approach, to identify the regions that have poor network connectivity thereby providing feedback to both the service providers to improve the coverage as well as to the customers to choose the network judiciously. In addition to this, the solution enables customers to navigate to a better mobile network coverage area with stronger signal strength location using Machine Learning Clustering Algorithms, whilst deploying it as a Mobile Application. It also provides a dynamic visual representation of varying network strength and range across nearby geographical areas.
Road Accident Proneness Indicator Based On Time, Weather And Location Specificity Using Graph Neural Networks
Oct 24, 2020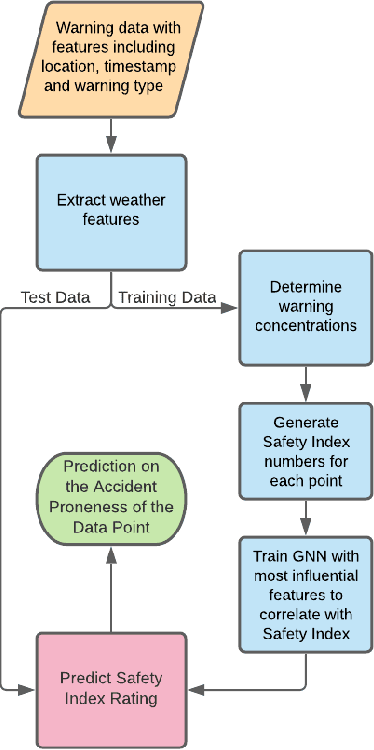
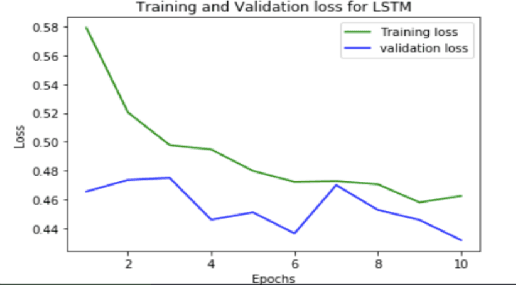
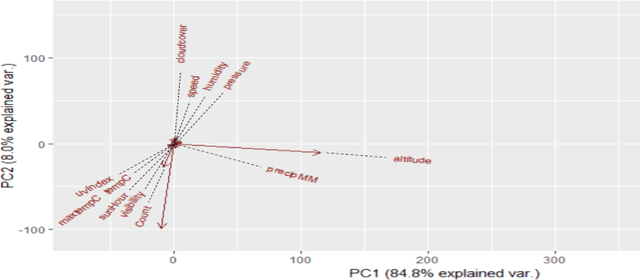
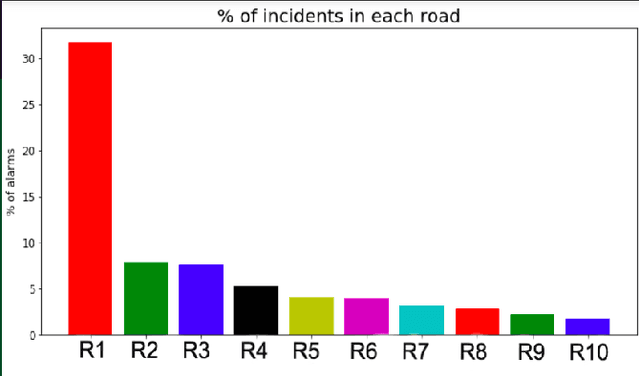
In this paper, we present a novel approach to identify the Spatio-temporal and environmental features that influence the safety of a road and predict its accident proneness based on these features. A total of 14 features were compiled based on Time, Weather, and Location (TWL) specificity along a road. To determine the influence each of the 14 features carries, a sensitivity study was performed using Principal Component Analysis. Using the locations of accident warnings, a Safety Index was developed to quantify how accident-prone a particular road is. We implement a novel approach to predict the Safety Index of a road-based on its TWL specificity by using a Graph Neural Network (GNN) architecture. The proposed architecture is uniquely suited for this application due to its ability to capture the complexities of the inherent nonlinear interlinking in a vast feature space. We employed a GNN to emulate the TWL feature vectors as individual nodes which were interlinked vis-\`a-vis edges of a graph. This model was verified to perform better than Logistic Regression, simple Feed-Forward Neural Networks, and even Long Short Term Memory (LSTM) Neural Networks. We validated our approach on a data set containing the alert locations along the routes of inter-state buses. The results achieved through this GNN architecture, using a TWL input feature space proved to be more feasible than the other predictive models, having reached a peak accuracy of 65%.