 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Downlink-Uplink Spectrum Sharing between Terrestrial and Non-Terrestrial Networks
Nov 11, 20256G networks are expected to integrate low Earth orbit satellites to ensure global connectivity by extending coverage to underserved and remote regions. However, the deployment of dense mega-constellations introduces severe interference among satellites operating over shared frequency bands. This is, in part, due to the limited flexibility of conventional frequency division duplex (FDD) systems, where fixed bands for downlink (DL) and uplink (UL) transmissions are employed. In this work, we propose dynamic re-assignment of FDD bands for improved interference management in dense deployments and evaluate the performance gain of this approach. To this end, we formulate a joint optimization problem that incorporates dynamic band assignment, user scheduling, and power allocation in both directions. This non-convex mixed integer problem is solved using a combination of equivalence transforms, alternating optimization, and state-of-the-art industrial-grade mixed integer solvers. Numerical results demonstrate that the proposed approach of dynamic FDD band assignment significantly enhances system performance over conventional FDD, achieving up to 94\% improvement in throughput in dense deployments.
Sparse Incremental Aggregation in Satellite Federated Learning
Jan 20, 2025


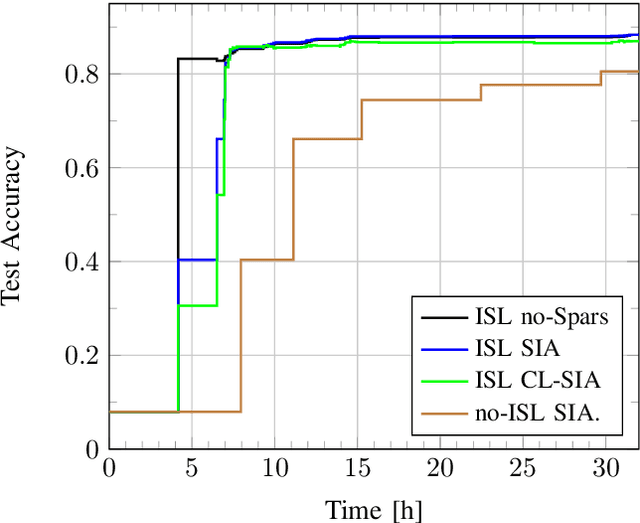
This paper studies Federated Learning (FL) in low Earth orbit (LEO) satellite constellations, where satellites are connected via intra-orbit inter-satellite links (ISLs) to their neighboring satellites. During the FL training process, satellites in each orbit forward gradients from nearby satellites, which are eventually transferred to the parameter server (PS). To enhance the efficiency of the FL training process, satellites apply in-network aggregation, referred to as incremental aggregation. In this work, the gradient sparsification methods from [1] are applied to satellite scenarios to improve bandwidth efficiency during incremental aggregation. The numerical results highlight an increase of over 4 x in bandwidth efficiency as the number of satellites in the orbital plane increases.
Sparse Incremental Aggregation in Multi-Hop Federated Learning
Jul 25, 2024This paper investigates federated learning (FL) in a multi-hop communication setup, such as in constellations with inter-satellite links. In this setup, part of the FL clients are responsible for forwarding other client's results to the parameter server. Instead of using conventional routing, the communication efficiency can be improved significantly by using in-network model aggregation at each intermediate hop, known as incremental aggregation (IA). Prior works [1] have indicated diminishing gains for IA under gradient sparsification. Here we study this issue and propose several novel correlated sparsification methods for IA. Numerical results show that, for some of these algorithms, the full potential of IA is still available under sparsification without impairing convergence. We demonstrate a 15x improvement in communication efficiency over conventional routing and a 11x improvement over state-of-the-art (SoA) sparse IA.
Determining Standard Occupational Classification Codes from Job Descriptions in Immigration Petitions
Sep 30, 2021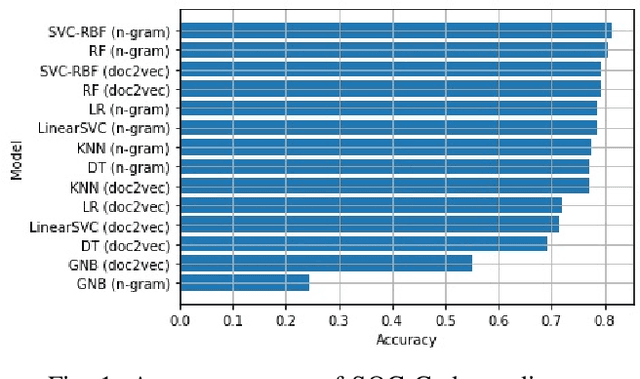
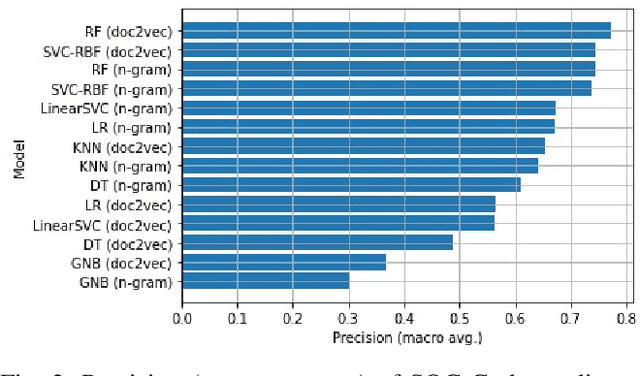
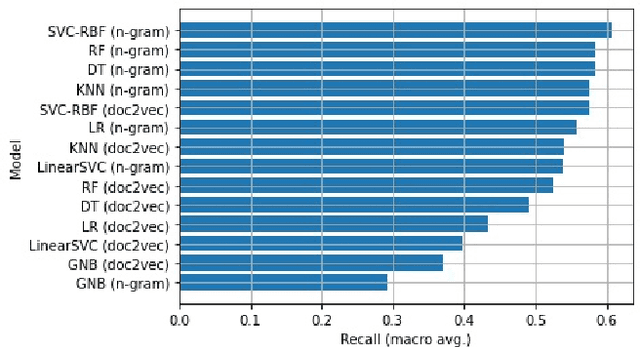
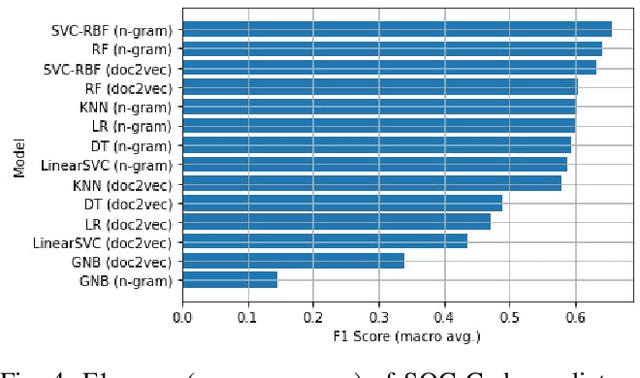
Accurate specification of standard occupational classification (SOC) code is critical to the success of many U.S. work visa applications. Determination of correct SOC code relies on careful study of job requirements and comparison to definitions given by the U.S. Bureau of Labor Statistics, which is often a tedious activity. In this paper, we apply methods from natural language processing (NLP) to computationally determine SOC code based on job description. We implement and empirically evaluate a broad variety of predictive models with respect to quality of prediction and training time, and identify models best suited for this task.
Immigration Document Classification and Automated Response Generation
Sep 29, 2020
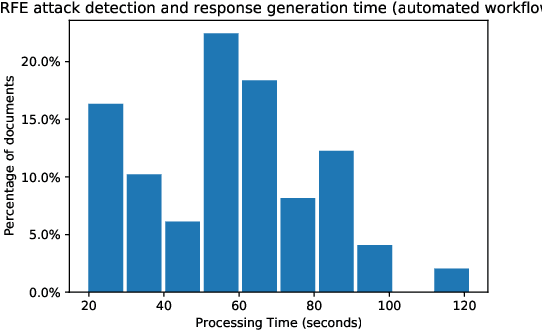
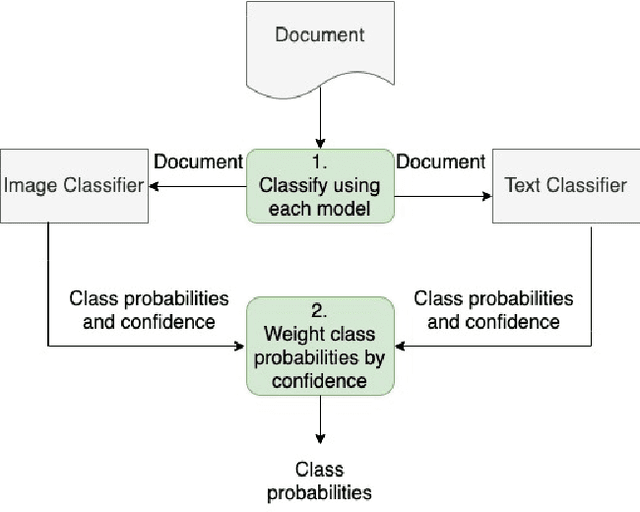
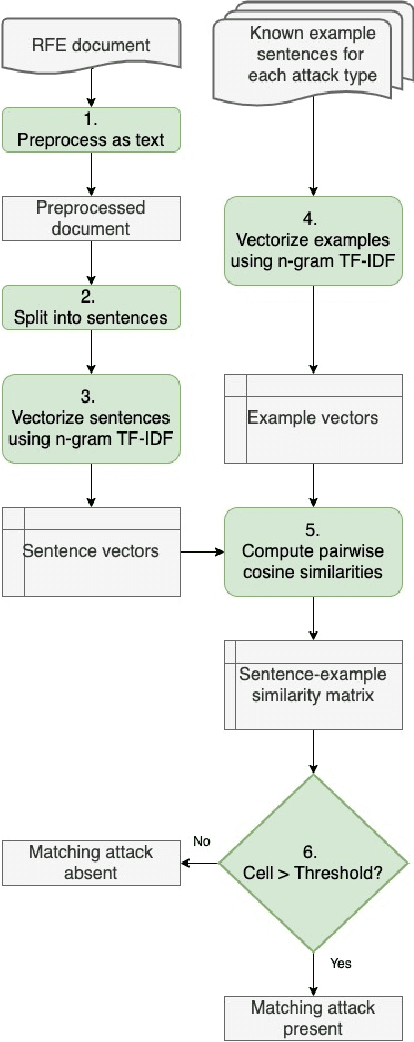
In this paper, we consider the problem of organizing supporting documents vital to U.S. work visa petitions, as well as responding to Requests For Evidence (RFE) issued by the U.S.~Citizenship and Immigration Services (USCIS). Typically, both processes require a significant amount of repetitive manual effort. To reduce the burden of mechanical work, we apply machine learning methods to automate these processes, with humans in the loop to review and edit output for submission. In particular, we use an ensemble of image and text classifiers to categorize supporting documents. We also use a text classifier to automatically identify the types of evidence being requested in an RFE, and used the identified types in conjunction with response templates and extracted fields to assemble draft responses. Empirical results suggest that our approach achieves considerable accuracy while significantly reducing processing time.
Graph Node Embeddings using Domain-Aware Biased Random Walks
Aug 08, 2019



The recent proliferation of publicly available graph-structured data has sparked an interest in machine learning algorithms for graph data. Since most traditional machine learning algorithms assume data to be tabular, embedding algorithms for mapping graph data to real-valued vector spaces has become an active area of research. Existing graph embedding approaches are based purely on structural information and ignore any semantic information from the underlying domain. In this paper, we demonstrate that semantic information can play a useful role in computing graph embeddings. Specifically, we present a framework for devising embedding strategies aware of domain-specific interpretations of graph nodes and edges, and use knowledge of downstream machine learning tasks to identify relevant graph substructures. Using two real-life domains, we show that our framework yields embeddings that are simple to implement and yet achieve equal or greater accuracy in machine learning tasks compared to domain independent approaches.