 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Guarantees of Stochastic Recursive Gradient in Non-Convex Finite Sum Problems
Jan 29, 2024This paper develops a new dimension-free Azuma-Hoeffding type bound on summation norm of a martingale difference sequence with random individual bounds. With this novel result, we provide high-probability bounds for the gradient norm estimator in the proposed algorithm Prob-SARAH, which is a modified version of the StochAstic Recursive grAdient algoritHm (SARAH), a state-of-art variance reduced algorithm that achieves optimal computational complexity in expectation for the finite sum problem. The in-probability complexity by Prob-SARAH matches the best in-expectation result up to logarithmic factors. Empirical experiments demonstrate the superior probabilistic performance of Prob-SARAH on real datasets compared to other popular algorithms.
Online Bootstrap Inference with Nonconvex Stochastic Gradient Descent Estimator
Jun 03, 2023In this paper, we investigate the theoretical properties of stochastic gradient descent (SGD) for statistical inference in the context of nonconvex optimization problems, which have been relatively unexplored compared to convex settings. Our study is the first to establish provable inferential procedures using the SGD estimator for general nonconvex objective functions, which may contain multiple local minima. We propose two novel online inferential procedures that combine SGD and the multiplier bootstrap technique. The first procedure employs a consistent covariance matrix estimator, and we establish its error convergence rate. The second procedure approximates the limit distribution using bootstrap SGD estimators, yielding asymptotically valid bootstrap confidence intervals. We validate the effectiveness of both approaches through numerical experiments. Furthermore, our analysis yields an intermediate result: the in-expectation error convergence rate for the original SGD estimator in nonconvex settings, which is comparable to existing results for convex problems. We believe this novel finding holds independent interest and enriches the literature on optimization and statistical inference.
Fast parameter estimation of Generalized Extreme Value distribution using Neural Networks
May 07, 2023The heavy-tailed behavior of the generalized extreme-value distribution makes it a popular choice for modeling extreme events such as floods, droughts, heatwaves, wildfires, etc. However, estimating the distribution's parameters using conventional maximum likelihood methods can be computationally intensive, even for moderate-sized datasets. To overcome this limitation, we propose a computationally efficient, likelihood-free estimation method utilizing a neural network. Through an extensive simulation study, we demonstrate that the proposed neural network-based method provides Generalized Extreme Value (GEV) distribution parameter estimates with comparable accuracy to the conventional maximum likelihood method but with a significant computational speedup. To account for estimation uncertainty, we utilize parametric bootstrapping, which is inherent in the trained network. Finally, we apply this method to 1000-year annual maximum temperature data from the Community Climate System Model version 3 (CCSM3) across North America for three atmospheric concentrations: 289 ppm $\mathrm{CO}_2$ (pre-industrial), 700 ppm $\mathrm{CO}_2$ (future conditions), and 1400 ppm $\mathrm{CO}_2$, and compare the results with those obtained using the maximum likelihood approach.
* 19 pages, 6 figures
Fitting Sparse Markov Models to Categorical Time Series Using Regularization
Feb 11, 2022



The major problem of fitting a higher order Markov model is the exponentially growing number of parameters. The most popular approach is to use a Variable Length Markov Chain (VLMC), which determines relevant contexts (recent pasts) of variable orders and form a context tree. A more general approach is called Sparse Markov Model (SMM), where all possible histories of order $m$ form a partition so that the transition probability vectors are identical for the histories belonging to a particular group. We develop an elegant method of fitting SMM using convex clustering, which involves regularization. The regularization parameter is selected using BIC criterion. Theoretical results demonstrate the model selection consistency of our method for large sample size. Extensive simulation studies under different set-up have been presented to measure the performance of our method. We apply this method to classify genome sequences, obtained from individuals affected by different viruses.
A Bootstrap-based Inference Framework for Testing Similarity of Paired Networks
Nov 25, 2019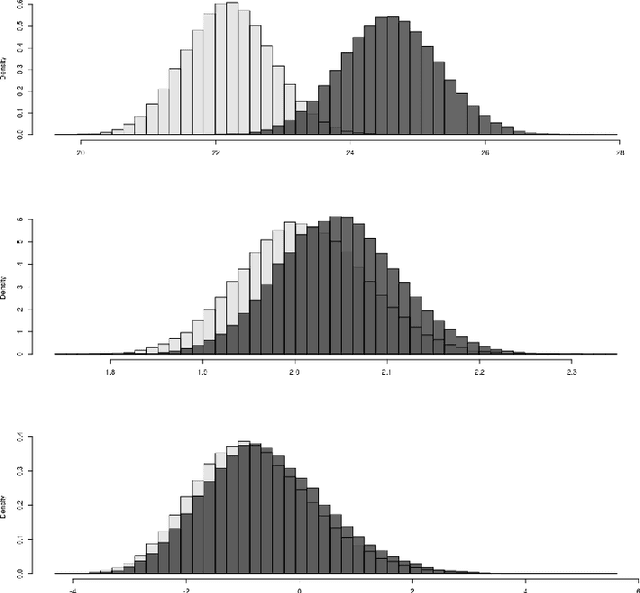
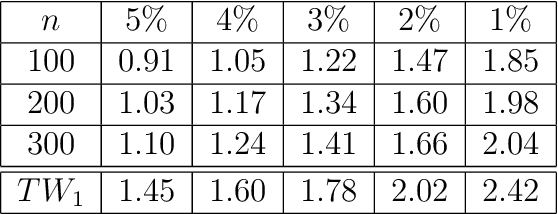
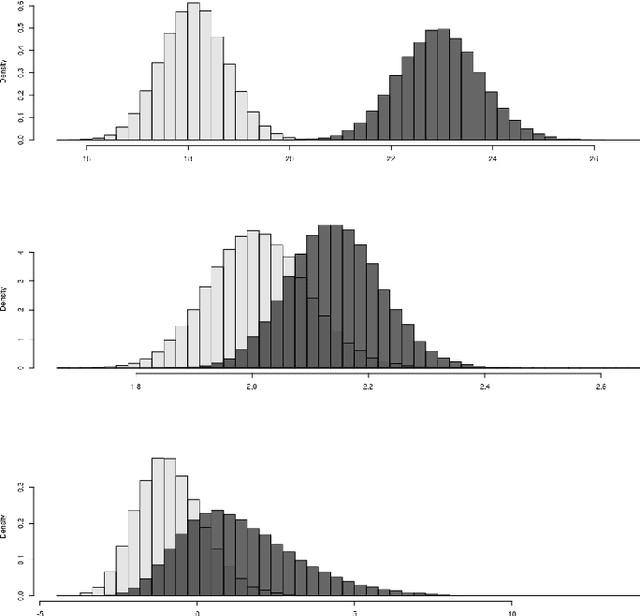
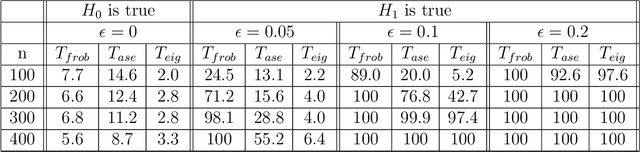
We live in an interconnected world where network valued data arises in many domains, and, fittingly, statistical network analysis has emerged as an active area in the literature. However, the topic of inference in networks has received relatively less attention. In this work, we consider the paired network inference problem where one is given two networks on the same set of nodes, and the goal is to test whether the given networks are stochastically similar in terms of some notion of similarity. We develop a general inferential framework based on parametric bootstrap to address this problem. Under this setting, we address two specific and important problems: the equality problem, i.e., whether the two networks are generated from the same random graph model, and the scaling problem, i.e., whether the underlying probability matrices of the two random graph models are scaled versions of each other.