 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Spatial Extremes using Non-Gaussian Spatial Autoregressive Models via Convolutional Neural Networks
May 05, 2025Data derived from remote sensing or numerical simulations often have a regular gridded structure and are large in volume, making it challenging to find accurate spatial models that can fill in missing grid cells or simulate the process effectively, especially in the presence of spatial heterogeneity and heavy-tailed marginal distributions. To overcome this issue, we present a spatial autoregressive modeling framework, which maps observations at a location and its neighbors to independent random variables. This is a highly flexible modeling approach and well-suited for non-Gaussian fields, providing simpler interpretability. In particular, we consider the SAR model with Generalized Extreme Value distribution innovations to combine the observation at a central grid location with its neighbors, capturing extreme spatial behavior based on the heavy-tailed innovations. While these models are fast to simulate by exploiting the sparsity of the key matrices in the computations, the maximum likelihood estimation of the parameters is prohibitive due to the intractability of the likelihood, making optimization challenging. To overcome this, we train a convolutional neural network on a large training set that covers a useful parameter space, and then use the trained network for fast parameter estimation. Finally, we apply this model to analyze annual maximum precipitation data from ERA-Interim-driven Weather Research and Forecasting (WRF) simulations, allowing us to explore its spatial extreme behavior across North America.
Fast parameter estimation of Generalized Extreme Value distribution using Neural Networks
May 07, 2023The heavy-tailed behavior of the generalized extreme-value distribution makes it a popular choice for modeling extreme events such as floods, droughts, heatwaves, wildfires, etc. However, estimating the distribution's parameters using conventional maximum likelihood methods can be computationally intensive, even for moderate-sized datasets. To overcome this limitation, we propose a computationally efficient, likelihood-free estimation method utilizing a neural network. Through an extensive simulation study, we demonstrate that the proposed neural network-based method provides Generalized Extreme Value (GEV) distribution parameter estimates with comparable accuracy to the conventional maximum likelihood method but with a significant computational speedup. To account for estimation uncertainty, we utilize parametric bootstrapping, which is inherent in the trained network. Finally, we apply this method to 1000-year annual maximum temperature data from the Community Climate System Model version 3 (CCSM3) across North America for three atmospheric concentrations: 289 ppm $\mathrm{CO}_2$ (pre-industrial), 700 ppm $\mathrm{CO}_2$ (future conditions), and 1400 ppm $\mathrm{CO}_2$, and compare the results with those obtained using the maximum likelihood approach.
* 19 pages, 6 figures
Student Dropout Risk Assessment in Undergraduate Course at Residential University
May 15, 2014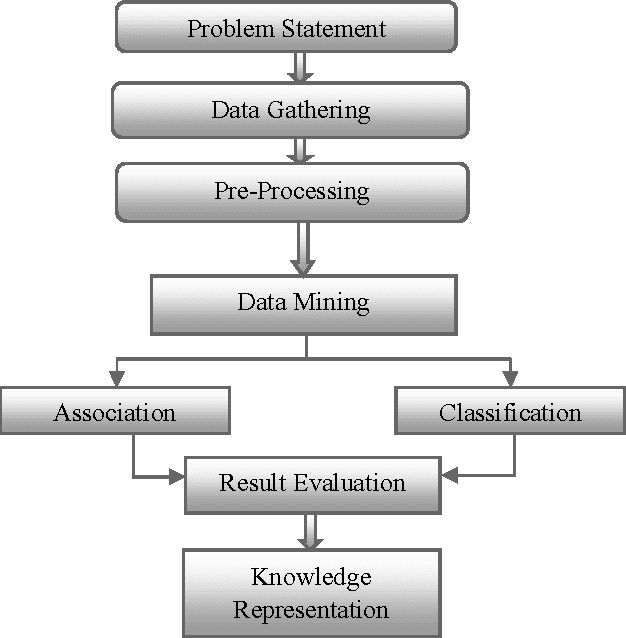
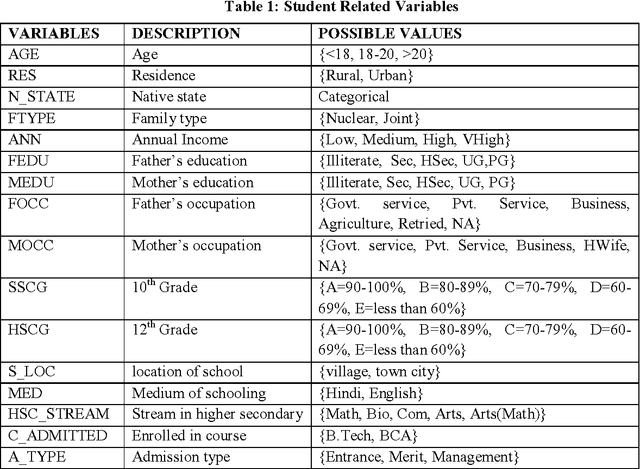
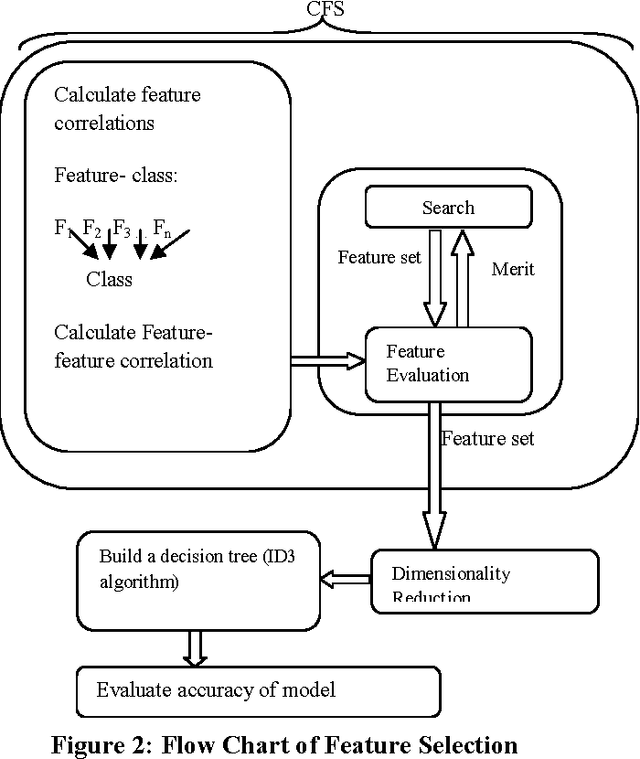
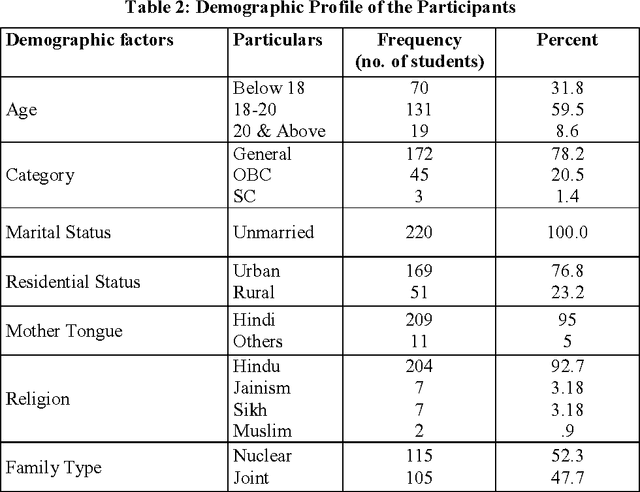
Student dropout prediction is an indispensable for numerous intelligent systems to measure the education system and success rate of any university as well as throughout the university in the world. Therefore, it becomes essential to develop efficient methods for prediction of the students at risk of dropping out, enabling the adoption of proactive process to minimize the situation. Thus, this research work propose a prototype machine learning tool which can automatically recognize whether the student will continue their study or drop their study using classification technique based on decision tree and extract hidden information from large data about what factors are responsible for dropout student. Further the contribution of factors responsible for dropout risk was studied using discriminant analysis and to extract interesting correlations, frequent patterns, associations or casual structures among significant datasets, Association rule mining was applied. In this study, the descriptive statistics analysis was carried out to measure the quality of data using SPSS 20.0 statistical software and application of decision tree and association rule were carried out by using WEKA data mining tool.