 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSIT-Free Multi-Group Multicast Transmission in Overloaded mmWave Systems
Nov 09, 2025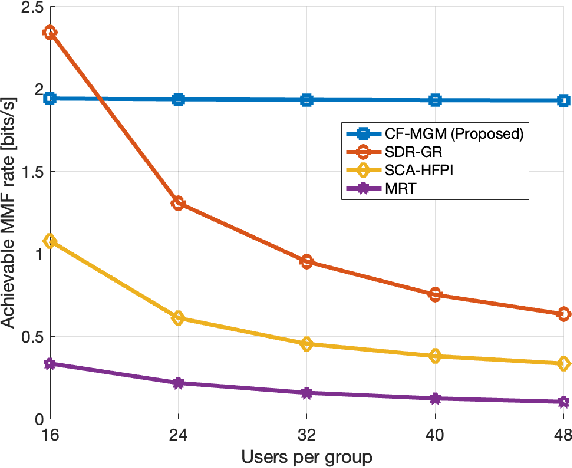
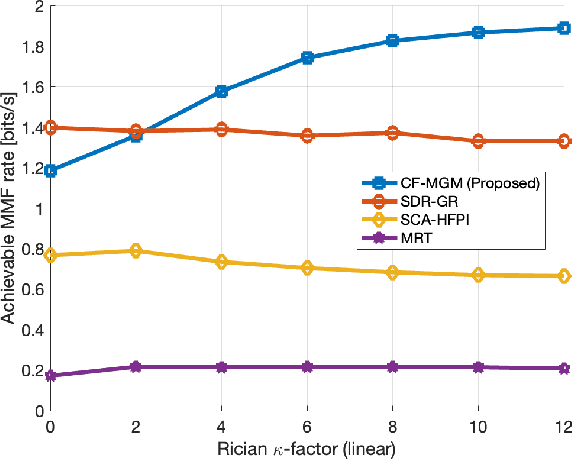
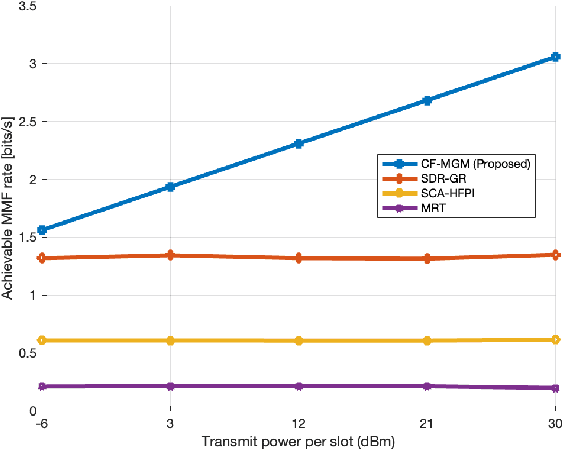
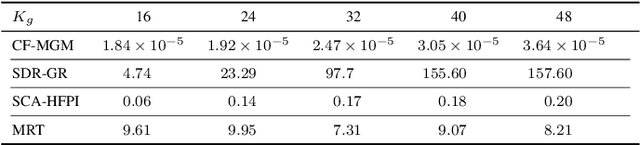
In this paper, we investigate the downlink multi-group multicast (MGM) transmission problem in overloaded mmWave systems. In particular, the conventional MGM beamforming requires substantial computational complexity and feedback (or pilot) overhead for acquisition of channel state information at the transmitter (CSIT), while simultaneous interference management and multicast beamforming optimization across multi-group inevitably incurs a significant rate loss. To address this, we propose a CSIT-free MGM (CF-MGM) transmission that eliminates the need for a complex CSIT acquisition. A deterministic CSIT-free precoding and proposed closed-form power allocation based on max-min fairness (MMF) allow each user to detect the common multicast stream completely canceling the inter-group interference with a significantly low complexity. Simulation results demonstrate the superiority and scalability of the proposed CF-MGM for the achievable rate and increase of users in a group outperforming the existing CSIT-based methods.
CSIT-Free Downlink Transmission for mmWave MU-MISO Systems in High-Mobility Scenario
Sep 19, 2025This paper investigates the downlink (DL) transmission in millimeter-wave (mmWave) multi-user multiple-input single-output (MU-MISO) systems especially focusing on a high speed mobile scenario. To complete the DL transmission within an extremely short channel coherence time, we propose a novel DL transmission framework that eliminates the need for channel state information at the transmitter (CSIT), of which acquisition process requires a substantial overhead, instead fully exploiting the given channel coherence time. Harnessing the characteristic of mmWave channel and uniquely designed CSIT-free unitary precoding, we propose a symbol detection method along with the simultaneous CSI at the receiver (CSIR) and Doppler shift estimation method to completely cancel the interferences while achieving a full combining gain. Via simulations, we demonstrate the effectiveness of the proposed method comparing with the existing baselines.
Moderate Actor-Critic Methods: Controlling Overestimation Bias via Expectile Loss
Apr 14, 2025Overestimation is a fundamental characteristic of model-free reinforcement learning (MF-RL), arising from the principles of temporal difference learning and the approximation of the Q-function. To address this challenge, we propose a novel moderate target in the Q-function update, formulated as a convex optimization of an overestimated Q-function and its lower bound. Our primary contribution lies in the efficient estimation of this lower bound through the lower expectile of the Q-value distribution conditioned on a state. Notably, our moderate target integrates seamlessly into state-of-the-art (SOTA) MF-RL algorithms, including Deep Deterministic Policy Gradient (DDPG) and Soft Actor Critic (SAC). Experimental results validate the effectiveness of our moderate target in mitigating overestimation bias in DDPG, SAC, and distributional RL algorithms.
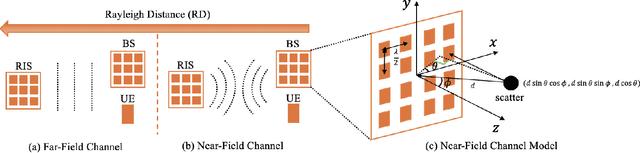
Two-Timescale Channel Estimation for RIS-Aided Near-Field Communications
Jan 06, 2025



In this paper, we investigate the channel estimation problem in reconfigurable intelligent surface (RIS)-aided near-field communication systems, where the extremely large number of RIS elements imposes considerable pilot overhead and computational complexity. To address this, we employ a two-timescale channel estimation strategy that exploits the asymmetric coherence times of the RIS-base station (BS) channel and the User-RIS channel. We derive a time-scaling property indicating that for any two effective channels within the longer coherence time, one effective channel can be represented as the product of a vector, referred to as the small-timescale effective channel, and the other effective channel. By utilizing the estimated effective channel along with processed observations from our piecewise beam training, we present an efficient method for estimating subsequent small-timescale effective channels. We theoretically establish the efficacy of the proposed RIS design and demonstrate, through simulations, the superiority of our channel estimation method in terms of pilot overhead and computational complexity compared to existing methods across various realistic channel models.
Near-Field LoS/NLoS Channel Estimation for RIS-Aided MU-MIMO Systems: Piece-Wise Low-Rank Approximation Approach
Oct 17, 2024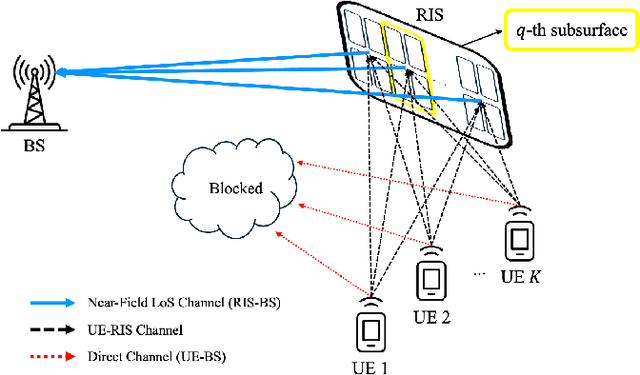
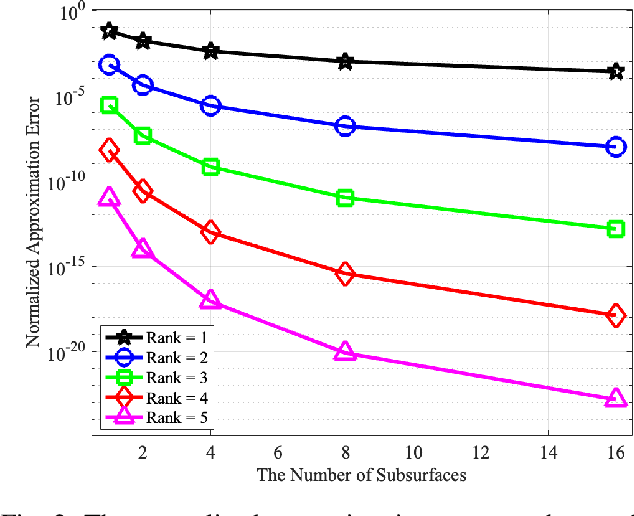
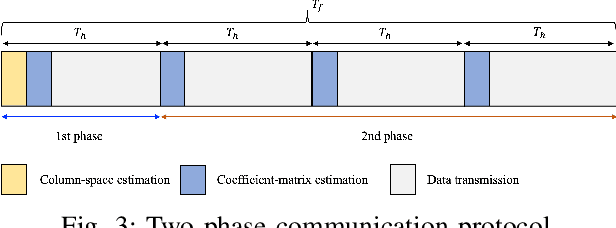
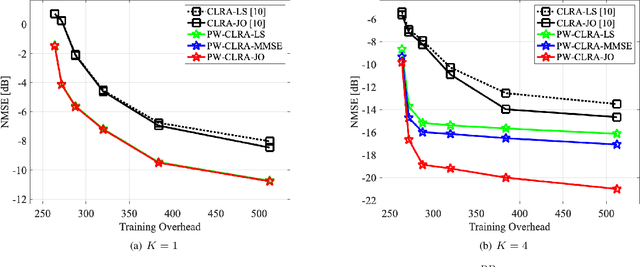
We study the channel estimation problem for a reconfigurable intelligent surface (RIS)-assisted millimeter-wave (mmWave) multi-user multiple-input multiple-output (MU-MIMO) system. In particular, it is assumed that the channel between a RIS and a base station (BS) exhibits a near-field line-of-sight (LoS) channel, which is a dominant signal path in mmWave communication systems. Due to the high-rankness and non-sparsity of the RIS-BS channel matrix in our system, the state-of-the-art (SOTA) methods, which are constructed based on far-field or near-field non-LoS (NLoS) channel, cannot provide attractive estimation performances. We for the first time propose an efficient near-field LoS/NLoS channel estimation method for RIS-assisted MU-MIMO systems by means of a piece-wise low-rank approximation. Specifically, an effective channel (to be estimated) is partitioned into piece-wise effective channels containing low-rank structures and then, they are estimated via collaborative low-rank approximation. The proposed method is named PW-CLRA. Via simulations, we verify the effectiveness of the proposed PW-CLRA.
Asymptotically Near-Optimal Hybrid Beamforming for mmWave IRS-Aided MIMO Systems
Mar 14, 2024Hybrid beamforming is an emerging technology for massive multiple-input multiple-output (MIMO) systems due to the advantages of lower complexity, cost, and power consumption. Recently, intelligent reflection surface (IRS) has been proposed as the cost-effective technique for robust millimeter-wave (mmWave) MIMO systems. Thus, it is required to jointly optimize a reflection vector and hybrid beamforming matrices for IRS-aided mmWave MIMO systems. Due to the lack of RF chain in the IRS, it is unavailable to acquire the TX-IRS and IRS-RX channels separately. Instead, there are efficient methods to estimate the so-called effective (or cascaded) channel in literature. We for the first time derive the near-optimal solution of the aforementioned joint optimization only using the effective channel. Based on our theoretical analysis, we develop the practical reflection vector and hybrid beamforming matrices by projecting the asymptotic solution into the modulus constraint. Via simulations, it is demonstrated that the proposed construction can outperform the state-of-the-art (SOTA) method, where the latter even requires the knowledge of the TX-IRS ad IRS-RX channels separately. Furthermore, our construction can provide the robustness for channel estimation errors, which is inevitable for practical massive MIMO systems.
Channel Estimation for Reconfigurable Intelligent Surface Aided mmWave MU-MIMO Systems : Hybrid Receiver Architectures
Jan 13, 2024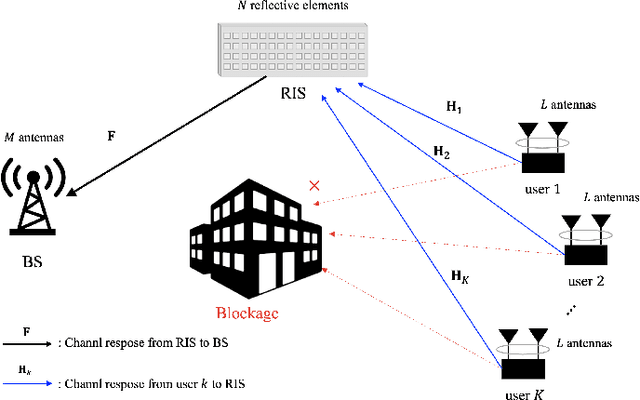

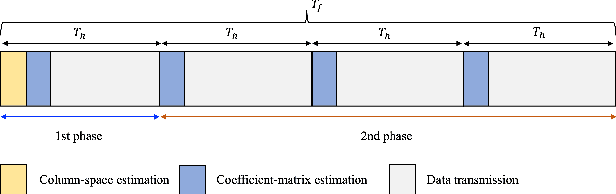
Channel estimation is one of the key challenges for the deployment of reconfigurable intelligence surface (RIS)-aided communication systems. In this paper, we study the channel estimation problem of RIS-aided mmWave multi-user multiple-input multiple-output (MU-MIMO) systems especially when a hybrid receiver architecture is adopted. For this system, we propose a simple yet efficient channel estimation method using the fact that cascaded channels (to be estimated) have low-dimensional common column space. In the proposed method, the reflection vectors at the RIS and the RF combining matrices at the BS are designed such that the training observations are suitable for estimating the common column space and the user-specific coefficient matrices via a collaborative low-rank approximation. Via simulations, we demonstrate the effectiveness of the proposed channel estimation method compared with the state-of-the-art ones.
On Practical Robust Reinforcement Learning: Practical Uncertainty Set and Double-Agent Algorithm
May 14, 2023



We study a robust reinforcement learning (RL) with model uncertainty. Given nominal Markov decision process (N-MDP) that generate samples for training, an uncertainty set is defined, which contains some perturbed MDPs from N-MDP for the purpose of reflecting potential mismatched between training (i.e., N-MDP) and testing environments. The objective of robust RL is to learn a robust policy that optimizes the worst-case performance over an uncertainty set. In this paper, we propose a new uncertainty set containing more realistic MDPs than the existing ones. For this uncertainty set, we present a robust RL algorithm (named ARQ-Learning) for tabular case and characterize its finite-time error bound. Also, it is proved that ARQ-Learning converges as fast as Q-Learning and the state-of-the-art robust Q-Learning while ensuring better robustness to real-world applications. Next, we propose {\em pessimistic} agent that efficiently tackles the key bottleneck for the extension of ARQ-Learning into the case with larger or continuous state spaces. Incorporating the idea of pessimistic agents into the famous RL algorithms such as Q-Learning, deep-Q network (DQN), and deep deterministic policy gradient (DDPG), we present PRQ-Learning, PR-DQN, and PR-DDPG, respectively. Noticeably, the proposed idea can be immediately applied to other model-free RL algorithms (e.g., soft actor critic). Via experiments, we demonstrate the superiority of our algorithms on various RL applications with model uncertainty.
Low-Complexity Symbol-Level Precoding for MU-MISO Downlink Systems with QAM Signals
Jun 01, 2021

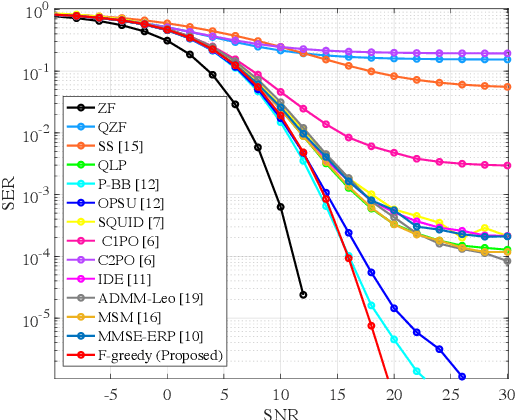
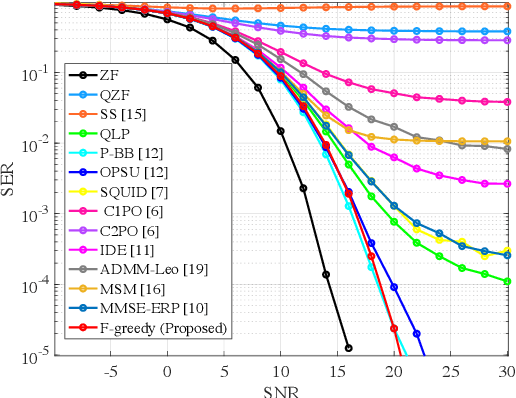
This study proposes the construction of a transmit signal for large-scale antenna systems with cost-effective 1-bit digital-to-analog converters in the downlink. Under quadrature-amplitude-modulation constellations, it is still an open problem to overcome a severe error floor problem caused by its nature property. To this end, we first present a feasibility condition which guarantees that each user's noiseless signal is placed in the desired decision region. For robustness to additive noise, we formulate an optimization problem, we then transform the feasibility conditions to cascaded matrix form. We propose a low-complexity algorithm to generate a 1-bit transmit signal based on the proposed optimization problem formulated as a well-defined mixed-integer-linear-programming. Numerical results validate the superiority of the proposed method in terms of detection performance and computational complexity.
Distributed Online Learning with Multiple Kernels
Feb 26, 2021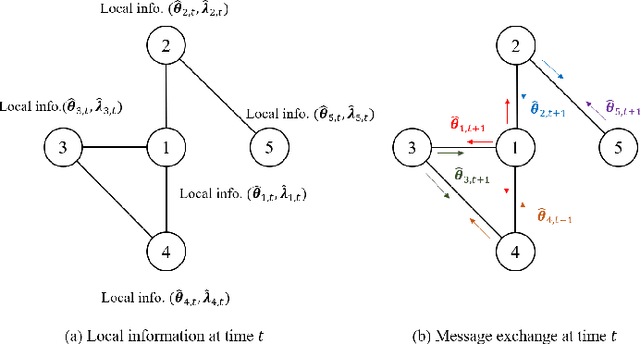
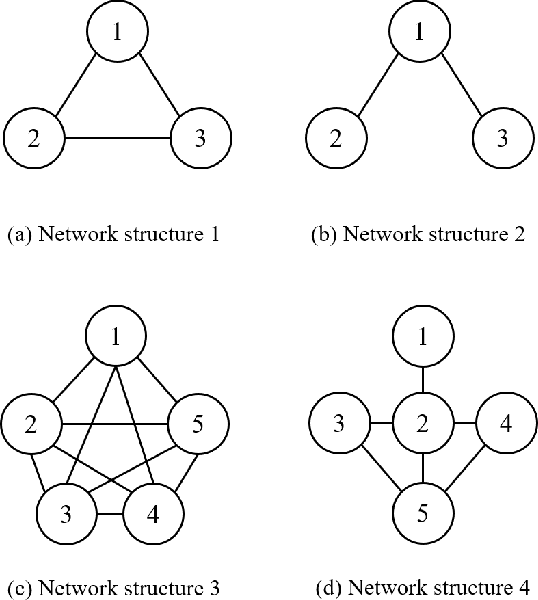
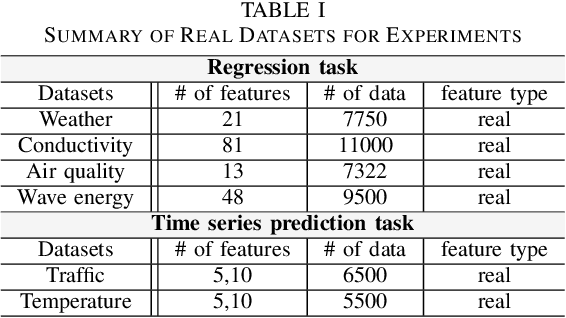
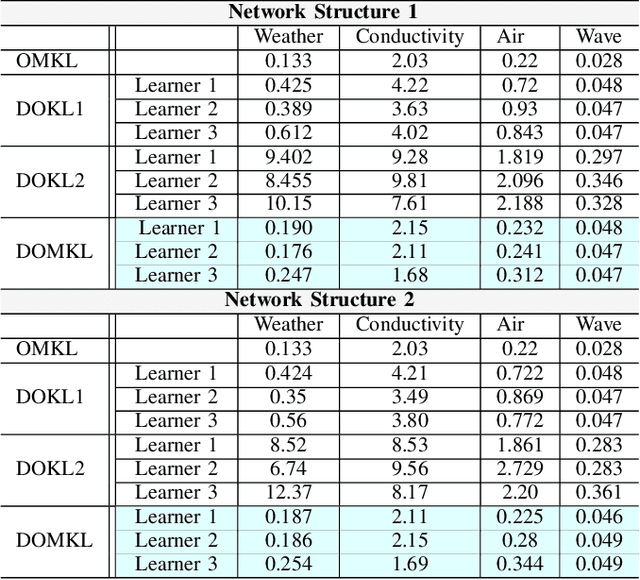
We consider the problem of learning a nonlinear function over a network of learners in a fully decentralized fashion. Online learning is additionally assumed, where every learner receives continuous streaming data locally. This learning model is called a fully distributed online learning (or a fully decentralized online federated learning). For this model, we propose a novel learning framework with multiple kernels, which is named DOMKL. The proposed DOMKL is devised by harnessing the principles of an online alternating direction method of multipliers and a distributed Hedge algorithm. We theoretically prove that DOMKL over T time slots can achieve an optimal sublinear regret, implying that every learner in the network can learn a common function which has a diminishing gap from the best function in hindsight. Our analysis also reveals that DOMKL yields the same asymptotic performance of the state-of-the-art centralized approach while keeping local data at edge learners. Via numerical tests with real datasets, we demonstrate the effectiveness of the proposed DOMKL on various online regression and time-series prediction tasks.