 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Systematic Data Acquisition and Data-Driven Simulation for the Safety Testing of Automated Driving Functions
May 02, 2024
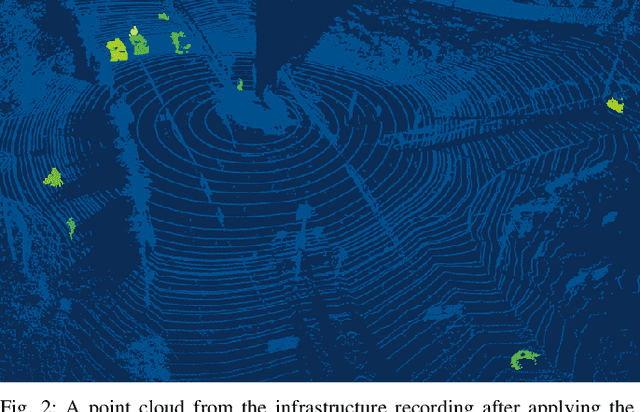
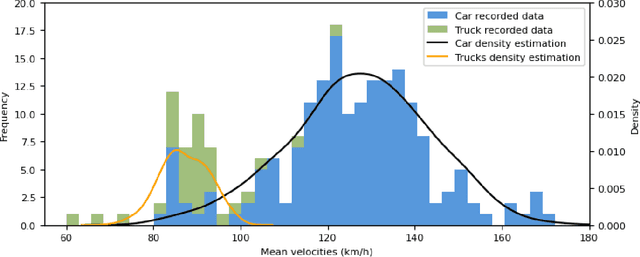
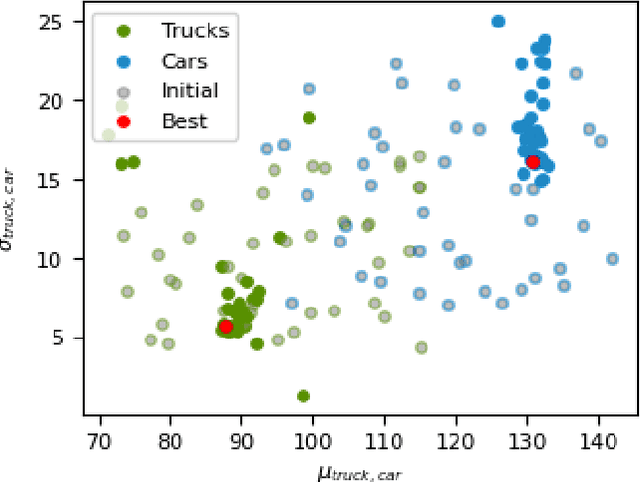
With growing complexity and criticality of automated driving functions in road traffic and their operational design domains (ODD), there is increasing demand for covering significant proportions of development, validation, and verification in virtual environments and through simulation models. If, however, simulations are meant not only to augment real-world experiments, but to replace them, quantitative approaches are required that measure to what degree and under which preconditions simulation models adequately represent reality, and thus, using their results accordingly. Especially in R&D areas related to the safety impact of the "open world", there is a significant shortage of real-world data to parameterize and/or validate simulations - especially with respect to the behavior of human traffic participants, whom automated driving functions will meet in mixed traffic. We present an approach to systematically acquire data in public traffic by heterogeneous means, transform it into a unified representation, and use it to automatically parameterize traffic behavior models for use in data-driven virtual validation of automated driving functions.
Improving Lidar-Based Semantic Segmentation of Top-View Grid Maps by Learning Features in Complementary Representations
Mar 02, 2022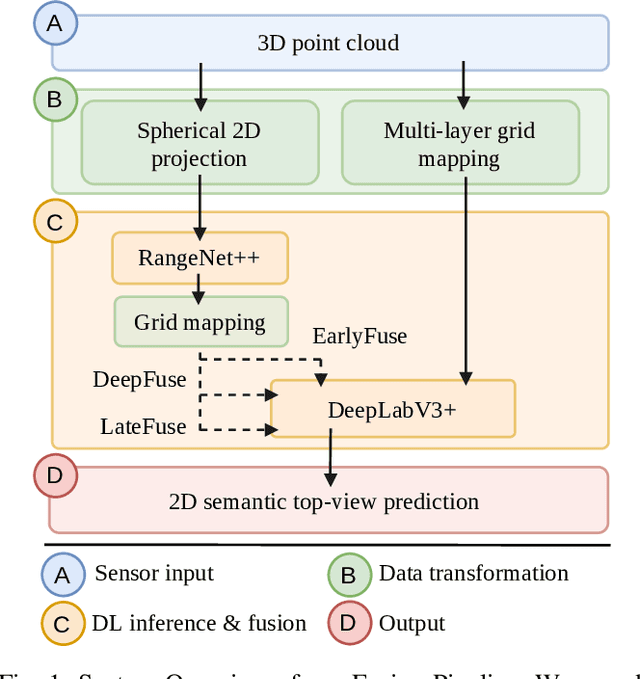
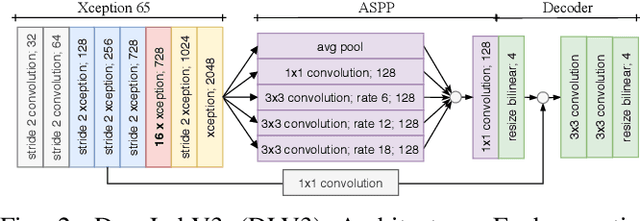
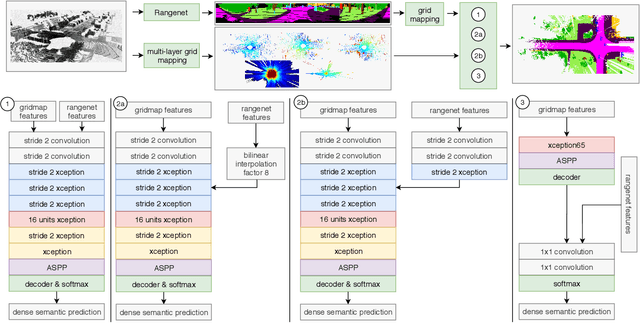

In this paper we introduce a novel way to predict semantic information from sparse, single-shot LiDAR measurements in the context of autonomous driving. In particular, we fuse learned features from complementary representations. The approach is aimed specifically at improving the semantic segmentation of top-view grid maps. Towards this goal the 3D LiDAR point cloud is projected onto two orthogonal 2D representations. For each representation a tailored deep learning architecture is developed to effectively extract semantic information which are fused by a superordinate deep neural network. The contribution of this work is threefold: (1) We examine different stages within the segmentation network for fusion. (2) We quantify the impact of embedding different features. (3) We use the findings of this survey to design a tailored deep neural network architecture leveraging respective advantages of different representations. Our method is evaluated using the SemanticKITTI dataset which provides a point-wise semantic annotation of more than 23.000 LiDAR measurements.