 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Lidar-Based Semantic Segmentation of Top-View Grid Maps by Learning Features in Complementary Representations
Paper and Code
Mar 02, 2022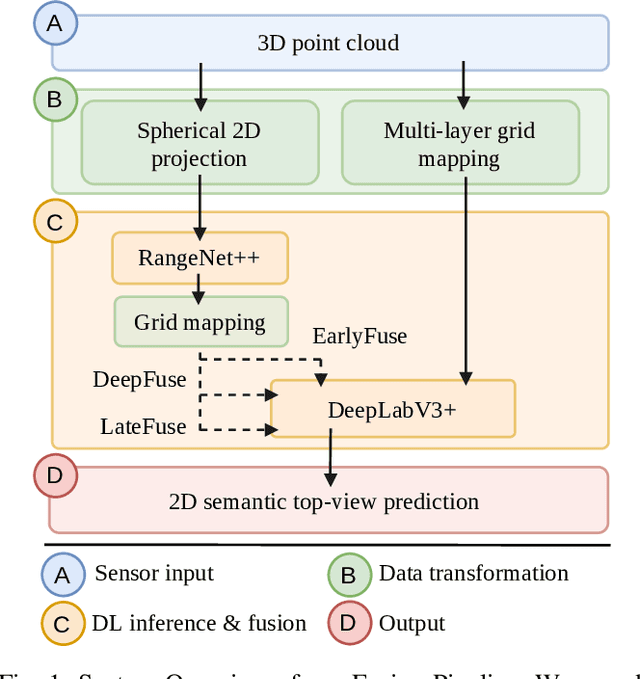
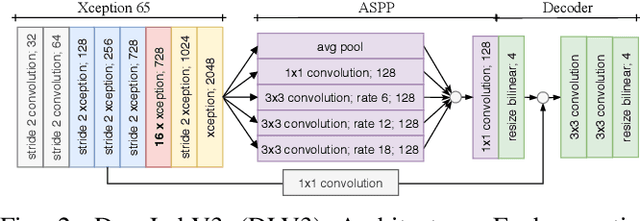
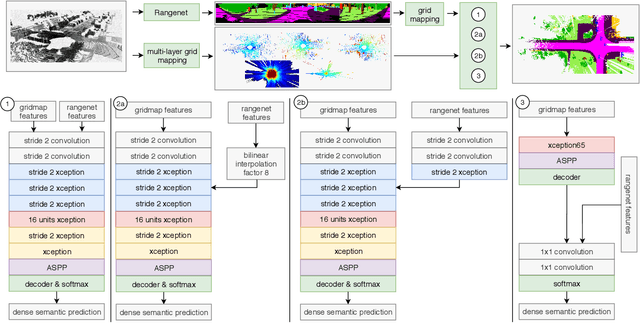

In this paper we introduce a novel way to predict semantic information from sparse, single-shot LiDAR measurements in the context of autonomous driving. In particular, we fuse learned features from complementary representations. The approach is aimed specifically at improving the semantic segmentation of top-view grid maps. Towards this goal the 3D LiDAR point cloud is projected onto two orthogonal 2D representations. For each representation a tailored deep learning architecture is developed to effectively extract semantic information which are fused by a superordinate deep neural network. The contribution of this work is threefold: (1) We examine different stages within the segmentation network for fusion. (2) We quantify the impact of embedding different features. (3) We use the findings of this survey to design a tailored deep neural network architecture leveraging respective advantages of different representations. Our method is evaluated using the SemanticKITTI dataset which provides a point-wise semantic annotation of more than 23.000 LiDAR measurements.