 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building a Multilingual Sememe Knowledge Base: Predicting Sememes for BabelNet Synsets
Dec 04, 2019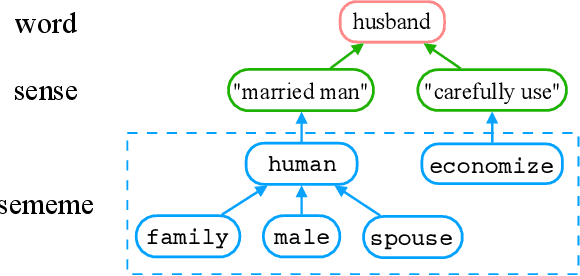


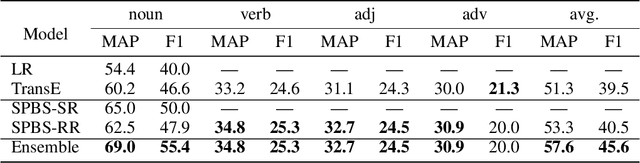
A sememe is defined as the minimum semantic unit of human languages. Sememe knowledge bases (KBs), which contain words annotated with sememes, have been successfully applied to many NLP tasks. However, existing sememe KBs are built on only a few languages, which hinders their widespread utilization. To address the issue, we propose to build a unified sememe KB for multiple languages based on BabelNet, a multilingual encyclopedic dictionary. We first build a dataset serving as the seed of the multilingual sememe KB. It manually annotates sememes for over $15$ thousand synsets (the entries of BabelNet). Then, we present a novel task of automatic sememe prediction for synsets, aiming to expand the seed dataset into a usable KB. We also propose two simple and effective models, which exploit different information of synsets. Finally, we conduct quantitative and qualitative analyses to explore important factors and difficulties in the task. All the source code and data of this work can be obtained on https://github.com/thunlp/BabelNet-Sememe-Prediction.
Enhancing Recurrent Neural Networks with Sememes
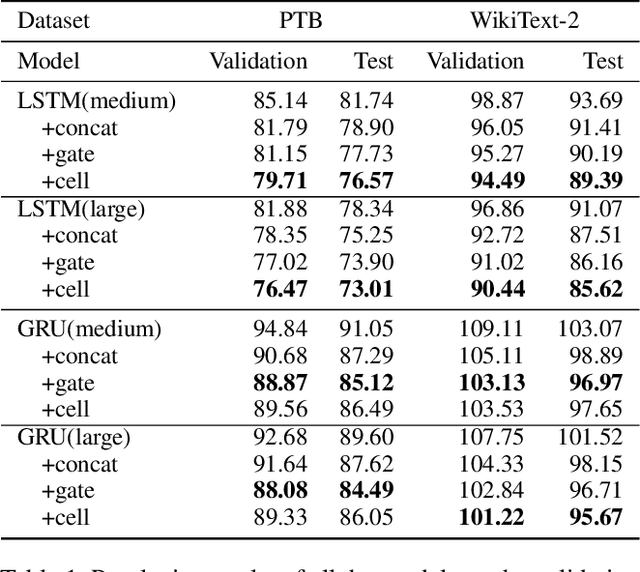
Oct 20, 2019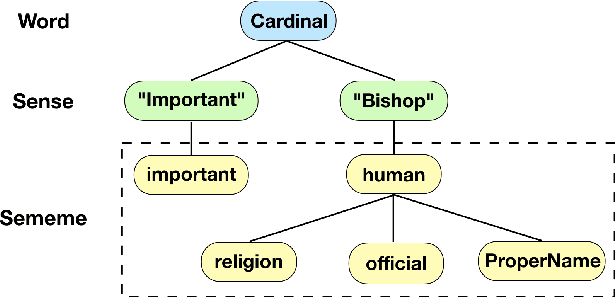
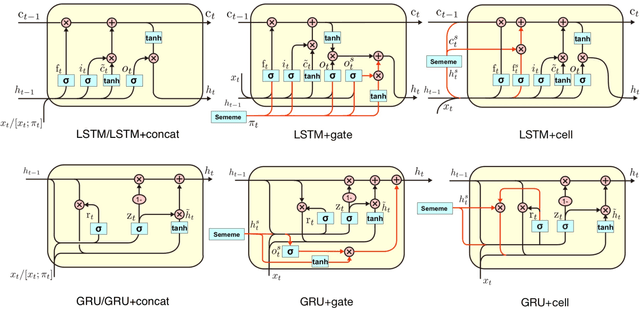
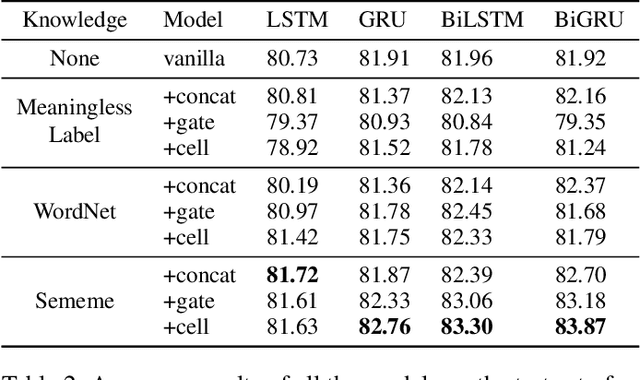
Sememes, the minimum semantic units of human languages, have been successfully utilized in various natural language processing applications. However, most existing studies exploit sememes in specific tasks and few efforts are made to utilize sememes more fundamentally. In this paper, we propose to incorporate sememes into recurrent neural networks (RNNs) to improve their sequence modeling ability, which is beneficial to all kinds of downstream tasks. We design three different sememe incorporation methods and employ them in typical RNNs including LSTM, GRU and their bidirectional variants. For evaluation, we use several benchmark datasets involving PTB and WikiText-2 for language modeling, SNLI for natural language inference. Experimental results show evident and consistent improvement of our sememe-incorporated models compared with vanilla RNNs, which proves the effectiveness of our sememe incorporation methods. Moreover, we find the sememe-incorporated models have great robustness and outperform adversarial training in defending adversarial attack. All the code and data of this work will be made available to the public.