 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
On the Expressivity of Multidimensional Markov Reward
Jul 22, 2023We consider the expressivity of Markov rewards in sequential decision making under uncertainty. We view reward functions in Markov Decision Processes (MDPs) as a means to characterize desired behaviors of agents. Assuming desired behaviors are specified as a set of acceptable policies, we investigate if there exists a scalar or multidimensional Markov reward function that makes the policies in the set more desirable than the other policies. Our main result states both necessary and sufficient conditions for the existence of such reward functions. We also show that for every non-degenerate set of deterministic policies, there exists a multidimensional Markov reward function that characterizes it
Benchmarking Actor-Critic Deep Reinforcement Learning Algorithms for Robotics Control with Action Constraints
Apr 18, 2023



This study presents a benchmark for evaluating action-constrained reinforcement learning (RL) algorithms. In action-constrained RL, each action taken by the learning system must comply with certain constraints. These constraints are crucial for ensuring the feasibility and safety of actions in real-world systems. We evaluate existing algorithms and their novel variants across multiple robotics control environments, encompassing multiple action constraint types. Our evaluation provides the first in-depth perspective of the field, revealing surprising insights, including the effectiveness of a straightforward baseline approach. The benchmark problems and associated code utilized in our experiments are made available online at github.com/omron-sinicx/action-constrained-RL-benchmark for further research and development.
Axioms in Model-based Planners
Jun 07, 2017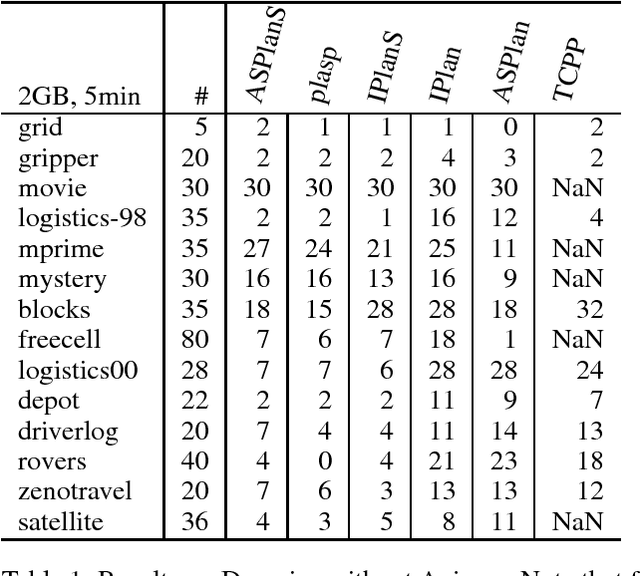

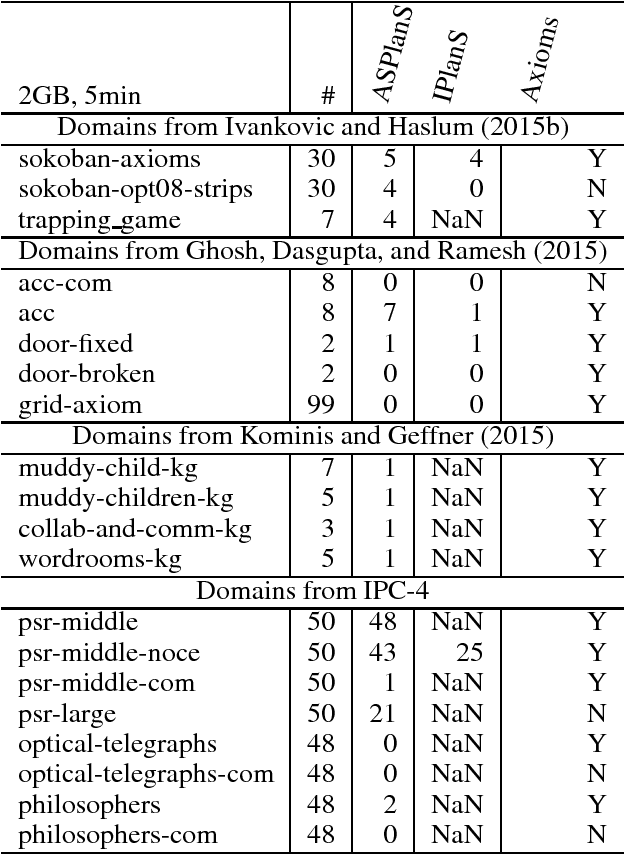
Axioms can be used to model derived predicates in domain- independent planning models. Formulating models which use axioms can sometimes result in problems with much smaller search spaces and shorter plans than the original model. Previous work on axiom-aware planners focused solely on state- space search planners. We propose axiom-aware planners based on answer set programming and integer programming. We evaluate them on PDDL domains with axioms and show that they can exploit additional expressivity of axioms.