 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive-Adversarial and Diffusion: Exploring pre-training and fine-tuning strategies for sulcal identification
May 29, 2024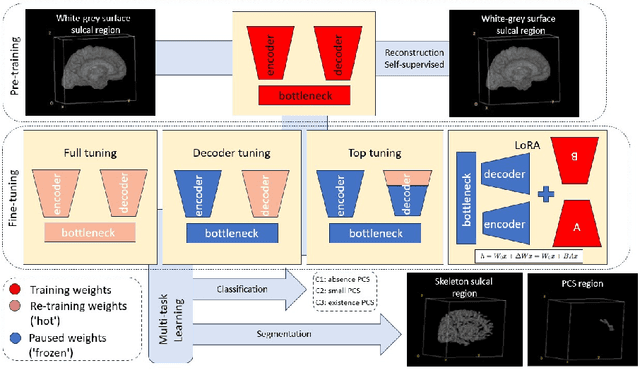
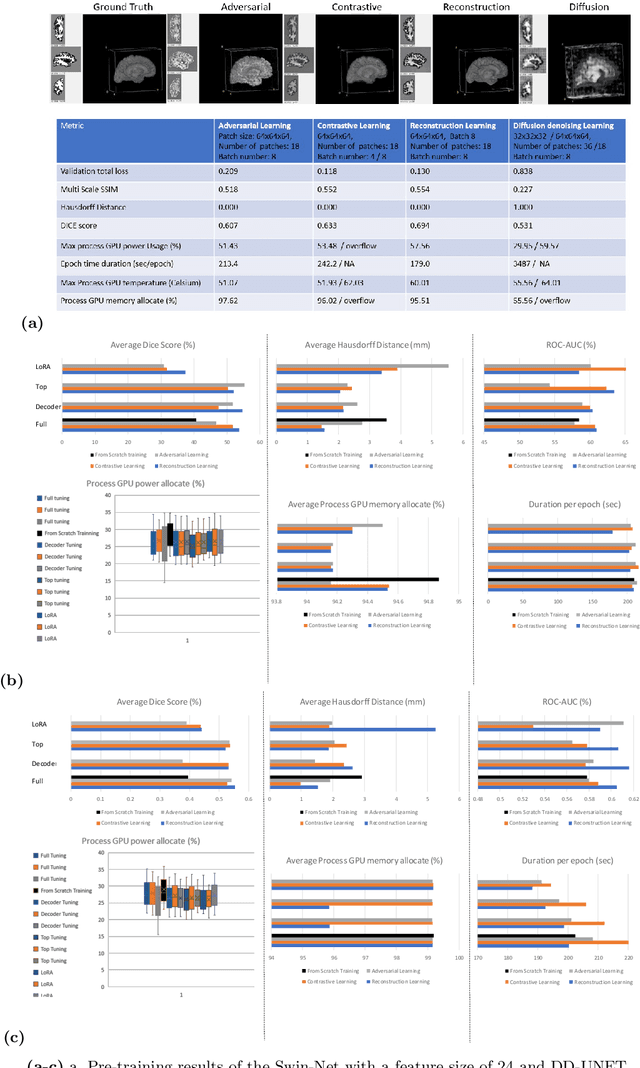
In the last decade, computer vision has witnessed the establishment of various training and learning approaches. Techniques like adversarial learning, contrastive learning, diffusion denoising learning, and ordinary reconstruction learning have become standard, representing state-of-the-art methods extensively employed for fully training or pre-training networks across various vision tasks. The exploration of fine-tuning approaches has emerged as a current focal point, addressing the need for efficient model tuning with reduced GPU memory usage and time costs while enhancing overall performance, as exemplified by methodologies like low-rank adaptation (LoRA). Key questions arise: which pre-training technique yields optimal results - adversarial, contrastive, reconstruction, or diffusion denoising? How does the performance of these approaches vary as the complexity of fine-tuning is adjusted? This study aims to elucidate the advantages of pre-training techniques and fine-tuning strategies to enhance the learning process of neural networks in independent identical distribution (IID) cohorts. We underscore the significance of fine-tuning by examining various cases, including full tuning, decoder tuning, top-level tuning, and fine-tuning of linear parameters using LoRA. Systematic summaries of model performance and efficiency are presented, leveraging metrics such as accuracy, time cost, and memory efficiency. To empirically demonstrate our findings, we focus on a multi-task segmentation-classification challenge involving the paracingulate sulcus (PCS) using different 3D Convolutional Neural Network (CNN) architectures by using the TOP-OSLO cohort comprising 596 subjects.