 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Explanation Necessity for Healthcare AI
May 31, 2024


Explainability is often critical to the acceptable implementation of artificial intelligence (AI). Nowhere is this more important than healthcare where decision-making directly impacts patients and trust in AI systems is essential. This trust is often built on the explanations and interpretations the AI provides. Despite significant advancements in AI interpretability, there remains the need for clear guidelines on when and to what extent explanations are necessary in the medical context. We propose a novel categorization system with four distinct classes of explanation necessity, guiding the level of explanation required: patient or sample (local) level, cohort or dataset (global) level, or both levels. We introduce a mathematical formulation that distinguishes these categories and offers a practical framework for researchers to determine the necessity and depth of explanations required in medical AI applications. Three key factors are considered: the robustness of the evaluation protocol, the variability of expert observations, and the representation dimensionality of the application. In this perspective, we address the question: When does an AI medical application need to be explained, and at what level of detail?
Contrastive-Adversarial and Diffusion: Exploring pre-training and fine-tuning strategies for sulcal identification
May 29, 2024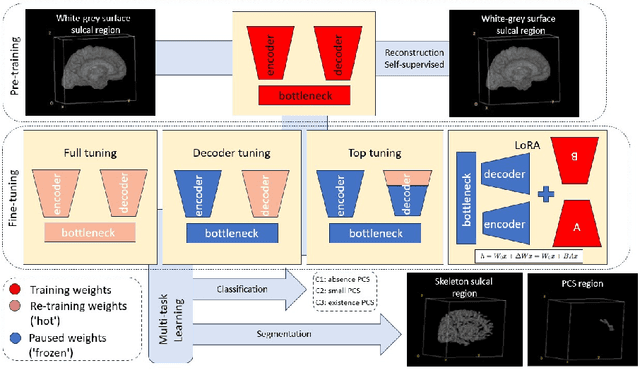
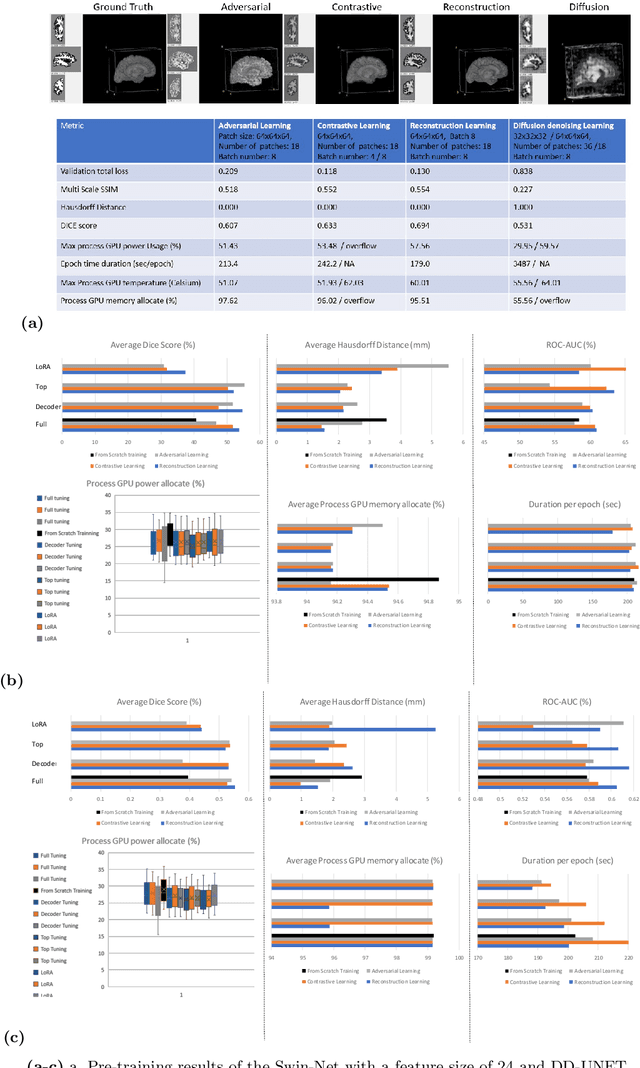
In the last decade, computer vision has witnessed the establishment of various training and learning approaches. Techniques like adversarial learning, contrastive learning, diffusion denoising learning, and ordinary reconstruction learning have become standard, representing state-of-the-art methods extensively employed for fully training or pre-training networks across various vision tasks. The exploration of fine-tuning approaches has emerged as a current focal point, addressing the need for efficient model tuning with reduced GPU memory usage and time costs while enhancing overall performance, as exemplified by methodologies like low-rank adaptation (LoRA). Key questions arise: which pre-training technique yields optimal results - adversarial, contrastive, reconstruction, or diffusion denoising? How does the performance of these approaches vary as the complexity of fine-tuning is adjusted? This study aims to elucidate the advantages of pre-training techniques and fine-tuning strategies to enhance the learning process of neural networks in independent identical distribution (IID) cohorts. We underscore the significance of fine-tuning by examining various cases, including full tuning, decoder tuning, top-level tuning, and fine-tuning of linear parameters using LoRA. Systematic summaries of model performance and efficiency are presented, leveraging metrics such as accuracy, time cost, and memory efficiency. To empirically demonstrate our findings, we focus on a multi-task segmentation-classification challenge involving the paracingulate sulcus (PCS) using different 3D Convolutional Neural Network (CNN) architectures by using the TOP-OSLO cohort comprising 596 subjects.