 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPL: A Relation-Aware Prototype Learning Approach for Few-Shot Document-Level Relation Extraction
Oct 24, 2023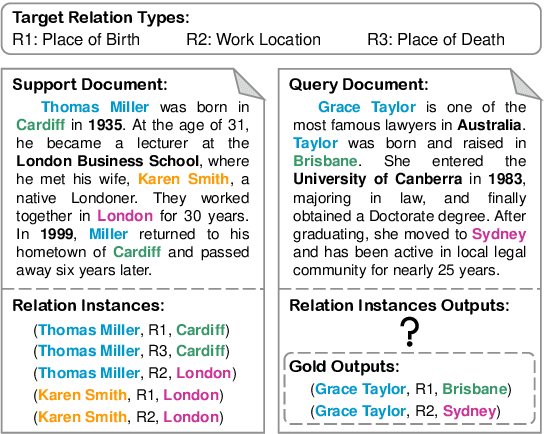
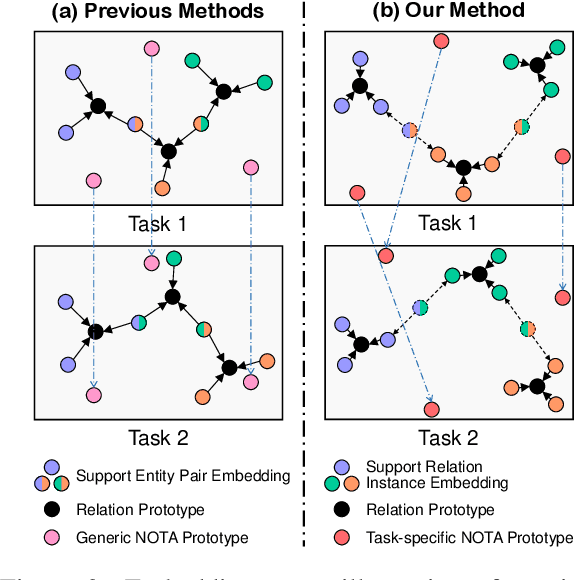

How to identify semantic relations among entities in a document when only a few labeled documents are available? Few-shot document-level relation extraction (FSDLRE) is crucial for addressing the pervasive data scarcity problem in real-world scenarios. Metric-based meta-learning is an effective framework widely adopted for FSDLRE, which constructs class prototypes for classification. However, existing works often struggle to obtain class prototypes with accurate relational semantics: 1) To build prototype for a target relation type, they aggregate the representations of all entity pairs holding that relation, while these entity pairs may also hold other relations, thus disturbing the prototype. 2) They use a set of generic NOTA (none-of-the-above) prototypes across all tasks, neglecting that the NOTA semantics differs in tasks with different target relation types. In this paper, we propose a relation-aware prototype learning method for FSDLRE to strengthen the relational semantics of prototype representations. By judiciously leveraging the relation descriptions and realistic NOTA instances as guidance, our method effectively refines the relation prototypes and generates task-specific NOTA prototypes. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches by average 2.61% $F_1$ across various settings of two FSDLRE benchmarks.
A Private Watermark for Large Language Models
Aug 02, 2023



Recently, text watermarking algorithms for large language models (LLMs) have been mitigating the potential harms of text generated by the LLMs, including fake news and copyright issues. However, the watermark detection of current text algorithms requires the key from the generation process, making them susceptible to breaches and counterfeiting. In this work, we propose the first private watermarking algorithm, which extends the current text watermarking algorithms by using two different neural networks respectively for watermark generation and detection, rather than using the same key at both stages. Meanwhile, part of the parameters of the watermark generation and detection networks are shared, which makes the detection network achieve a high accuracy very efficiently. Experiments show that our algorithm ensures high detection accuracy with minimal impact on generation and detection speed, due to the small parameter size of both networks. Additionally, our subsequent analysis demonstrates the difficulty of reverting the watermark generation rules from the detection network.
Gaussian Prior Reinforcement Learning for Nested Named Entity Recognition
May 12, 2023Named Entity Recognition (NER) is a well and widely studied task in natural language processing. Recently, the nested NER has attracted more attention since its practicality and difficulty. Existing works for nested NER ignore the recognition order and boundary position relation of nested entities. To address these issues, we propose a novel seq2seq model named GPRL, which formulates the nested NER task as an entity triplet sequence generation process. GPRL adopts the reinforcement learning method to generate entity triplets decoupling the entity order in gold labels and expects to learn a reasonable recognition order of entities via trial and error. Based on statistics of boundary distance for nested entities, GPRL designs a Gaussian prior to represent the boundary distance distribution between nested entities and adjust the output probability distribution of nested boundary tokens. Experiments on three nested NER datasets demonstrate that GPRL outperforms previous nested NER models.
Character-level White-Box Adversarial Attacks against Transformers via Attachable Subwords Substitution
Oct 31, 2022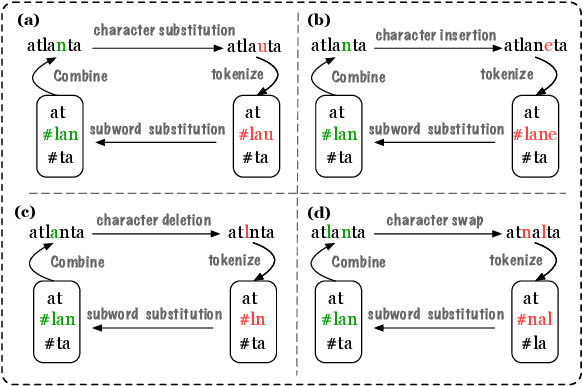
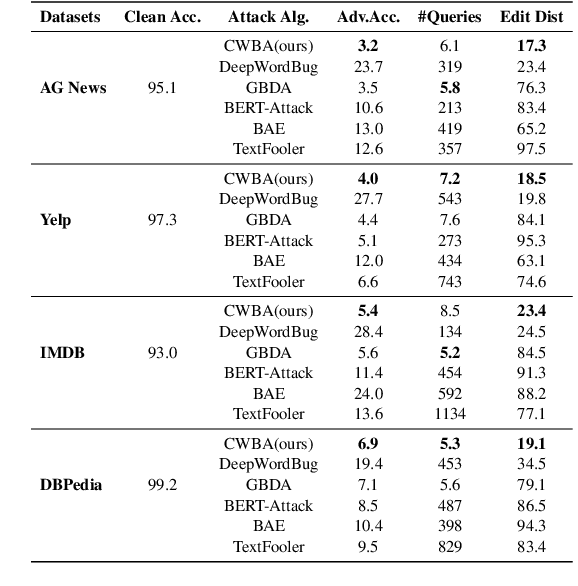
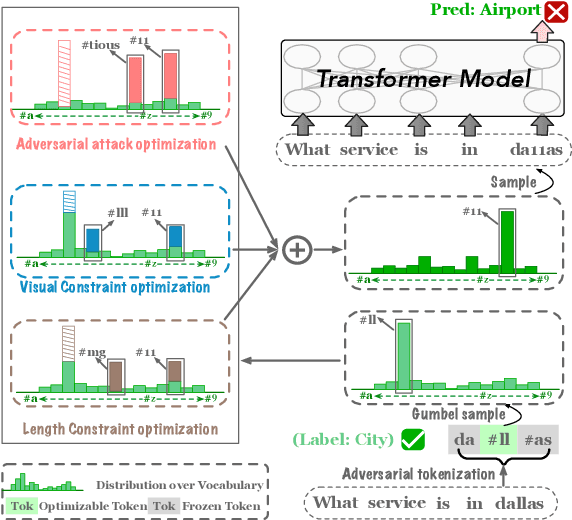
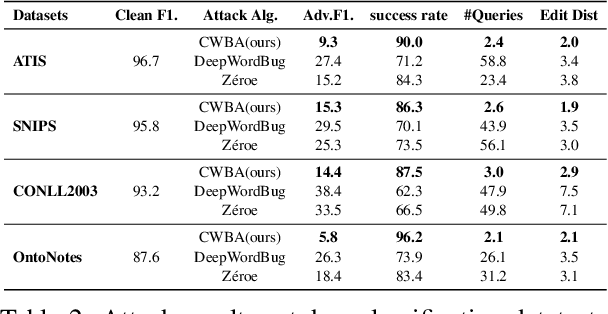
We propose the first character-level white-box adversarial attack method against transformer models. The intuition of our method comes from the observation that words are split into subtokens before being fed into the transformer models and the substitution between two close subtokens has a similar effect to the character modification. Our method mainly contains three steps. First, a gradient-based method is adopted to find the most vulnerable words in the sentence. Then we split the selected words into subtokens to replace the origin tokenization result from the transformer tokenizer. Finally, we utilize an adversarial loss to guide the substitution of attachable subtokens in which the Gumbel-softmax trick is introduced to ensure gradient propagation. Meanwhile, we introduce the visual and length constraint in the optimization process to achieve minimum character modifications. Extensive experiments on both sentence-level and token-level tasks demonstrate that our method could outperform the previous attack methods in terms of success rate and edit distance. Furthermore, human evaluation verifies our adversarial examples could preserve their origin labels.
* 13 pages, 3 figures. EMNLP 2022
A Multi-level Supervised Contrastive Learning Framework for Low-Resource Natural Language Inference
May 31, 2022

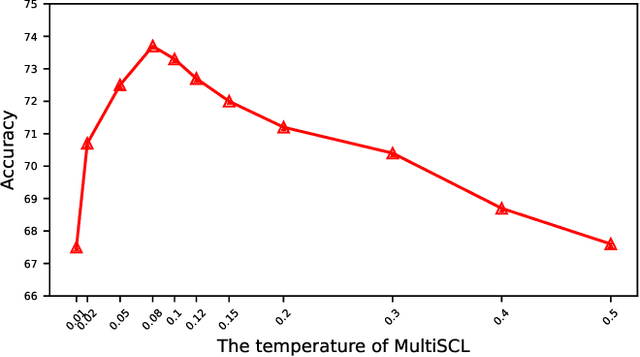
Natural Language Inference (NLI) is a growingly essential task in natural language understanding, which requires inferring the relationship between the sentence pairs (premise and hypothesis). Recently, low-resource natural language inference has gained increasing attention, due to significant savings in manual annotation costs and a better fit with real-world scenarios. Existing works fail to characterize discriminative representations between different classes with limited training data, which may cause faults in label prediction. Here we propose a multi-level supervised contrastive learning framework named MultiSCL for low-resource natural language inference. MultiSCL leverages a sentence-level and pair-level contrastive learning objective to discriminate between different classes of sentence pairs by bringing those in one class together and pushing away those in different classes. MultiSCL adopts a data augmentation module that generates different views for input samples to better learn the latent representation. The pair-level representation is obtained from a cross attention module. We conduct extensive experiments on two public NLI datasets in low-resource settings, and the accuracy of MultiSCL exceeds other models by 3.1% on average. Moreover, our method outperforms the previous state-of-the-art method on cross-domain tasks of text classification.
Pair-Level Supervised Contrastive Learning for Natural Language Inference
Jan 26, 2022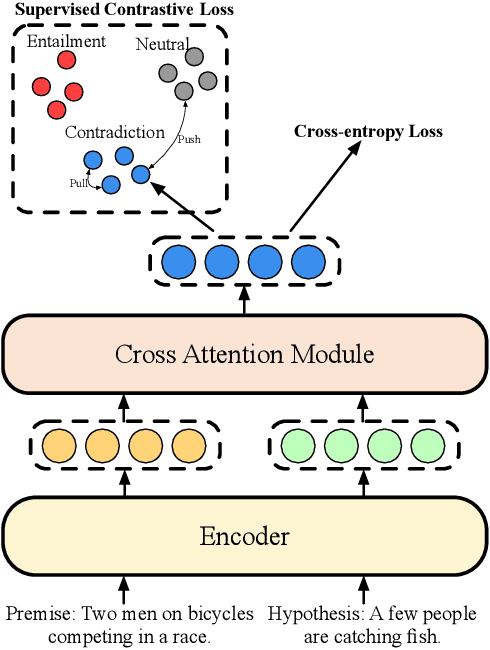



Natural language inference (NLI) is an increasingly important task for natural language understanding, which requires one to infer the relationship between the sentence pair (premise and hypothesis). Many recent works have used contrastive learning by incorporating the relationship of the sentence pair from NLI datasets to learn sentence representation. However, these methods only focus on comparisons with sentence-level representations. In this paper, we propose a Pair-level Supervised Contrastive Learning approach (PairSCL). We adopt a cross attention module to learn the joint representations of the sentence pairs. A contrastive learning objective is designed to distinguish the varied classes of sentence pairs by pulling those in one class together and pushing apart the pairs in other classes. We evaluate PairSCL on two public datasets of NLI where the accuracy of PairSCL outperforms other methods by 2.1% on average. Furthermore, our method outperforms the previous state-of-the-art method on seven transfer tasks of text classification.