 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-level Supervised Contrastive Learning Framework for Low-Resource Natural Language Inference
Paper and Code
May 31, 2022
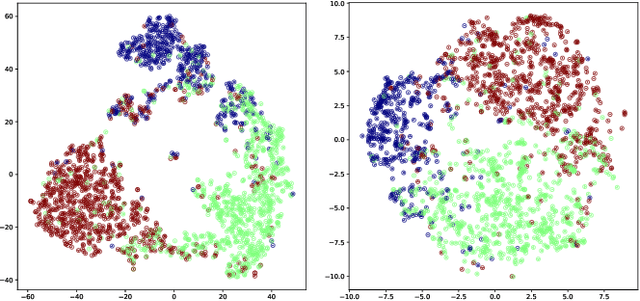

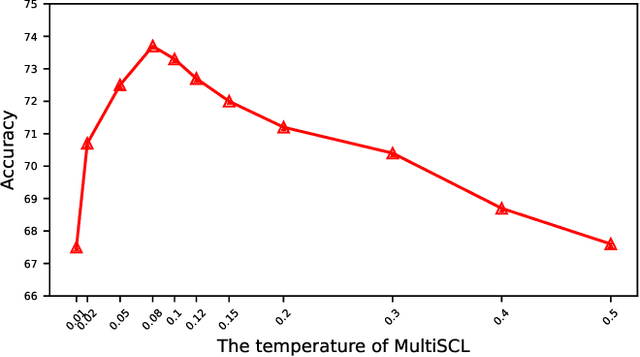
Natural Language Inference (NLI) is a growingly essential task in natural language understanding, which requires inferring the relationship between the sentence pairs (premise and hypothesis). Recently, low-resource natural language inference has gained increasing attention, due to significant savings in manual annotation costs and a better fit with real-world scenarios. Existing works fail to characterize discriminative representations between different classes with limited training data, which may cause faults in label prediction. Here we propose a multi-level supervised contrastive learning framework named MultiSCL for low-resource natural language inference. MultiSCL leverages a sentence-level and pair-level contrastive learning objective to discriminate between different classes of sentence pairs by bringing those in one class together and pushing away those in different classes. MultiSCL adopts a data augmentation module that generates different views for input samples to better learn the latent representation. The pair-level representation is obtained from a cross attention module. We conduct extensive experiments on two public NLI datasets in low-resource settings, and the accuracy of MultiSCL exceeds other models by 3.1% on average. Moreover, our method outperforms the previous state-of-the-art method on cross-domain tasks of text classification.