 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Graph Coarsening: Weather and Weekday Prediction with London's Bike-Sharing Service using GNN
Aug 30, 2023

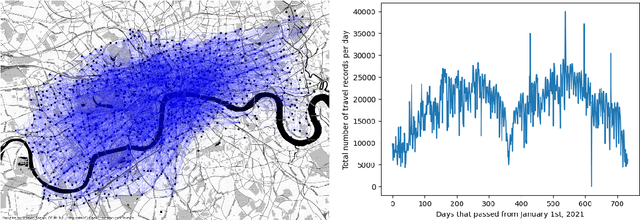

This study introduced the use of Graph Neural Network (GNN) for predicting the weather and weekday of a day in London, from the dataset of Santander Cycles bike-sharing system as a graph classification task. The proposed GNN models newly introduced (i) a concatenation operator of graph features with trained node embeddings and (ii) a graph coarsening operator based on geographical contiguity, namely "Spatial Graph Coarsening". With the node features of land-use characteristics and number of households around the bike stations and graph features of temperatures in the city, our proposed models outperformed the baseline model in cross-entropy loss and accuracy of the validation dataset.
MuRIL: Multilingual Representations for Indian Languages
Apr 02, 2021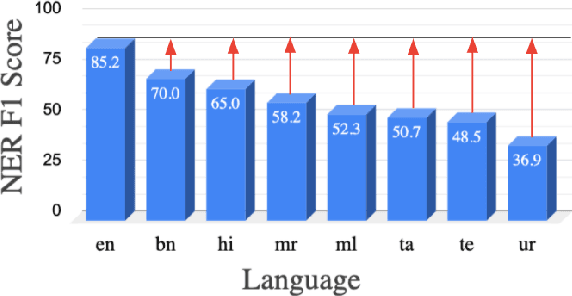


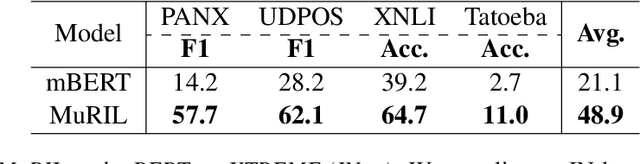
India is a multilingual society with 1369 rationalized languages and dialects being spoken across the country (INDIA, 2011). Of these, the 22 scheduled languages have a staggering total of 1.17 billion speakers and 121 languages have more than 10,000 speakers (INDIA, 2011). India also has the second largest (and an ever growing) digital footprint (Statista, 2020). Despite this, today's state-of-the-art multilingual systems perform suboptimally on Indian (IN) languages. This can be explained by the fact that multilingual language models (LMs) are often trained on 100+ languages together, leading to a small representation of IN languages in their vocabulary and training data. Multilingual LMs are substantially less effective in resource-lean scenarios (Wu and Dredze, 2020; Lauscher et al., 2020), as limited data doesn't help capture the various nuances of a language. One also commonly observes IN language text transliterated to Latin or code-mixed with English, especially in informal settings (for example, on social media platforms) (Rijhwani et al., 2017). This phenomenon is not adequately handled by current state-of-the-art multilingual LMs. To address the aforementioned gaps, we propose MuRIL, a multilingual LM specifically built for IN languages. MuRIL is trained on significantly large amounts of IN text corpora only. We explicitly augment monolingual text corpora with both translated and transliterated document pairs, that serve as supervised cross-lingual signals in training. MuRIL significantly outperforms multilingual BERT (mBERT) on all tasks in the challenging cross-lingual XTREME benchmark (Hu et al., 2020). We also present results on transliterated (native to Latin script) test sets of the chosen datasets and demonstrate the efficacy of MuRIL in handling transliterated data.
Pitch-Synchronous Single Frequency Filtering Spectrogram for Speech Emotion Recognition
Aug 07, 2019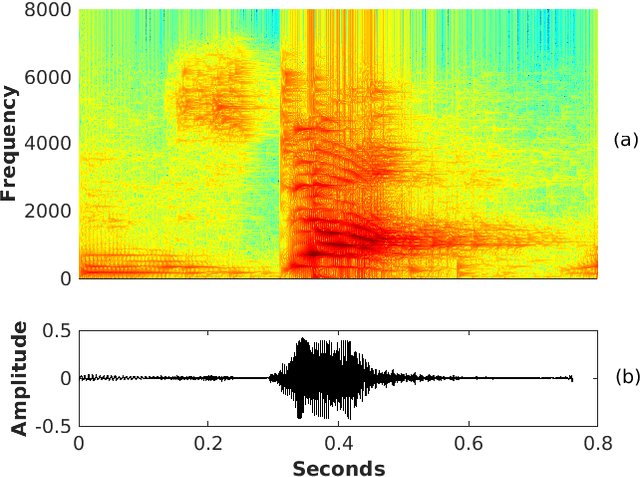
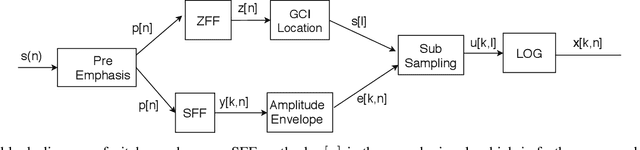
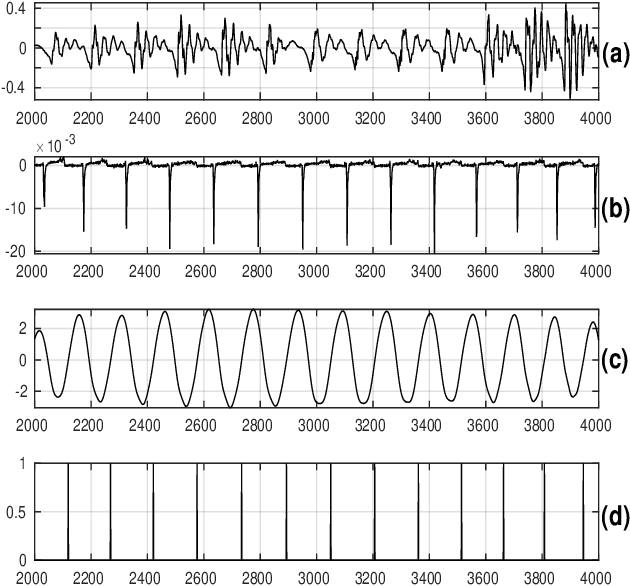
Convolutional neural networks (CNN) are widely used for speech emotion recognition (SER). In such cases, the short time fourier transform (STFT) spectrogram is the most popular choice for representing speech, which is fed as input to the CNN. However, the uncertainty principles of the short-time Fourier transform prevent it from capturing time and frequency resolutions simultaneously. On the other hand, the recently proposed single frequency filtering (SFF) spectrogram promises to be a better alternative because it captures both time and frequency resolutions simultaneously. In this work, we explore the SFF spectrogram as an alternative representation of speech for SER. We have modified the SFF spectrogram by taking the average of the amplitudes of all the samples between two successive glottal closure instants (GCI) locations. The duration between two successive GCI locations gives the pitch, motivating us to name the modified SFF spectrogram as pitch-synchronous SFF spectrogram. The GCI locations were detected using zero frequency filtering approach. The proposed pitch-synchronous SFF spectrogram produced accuracy values of 63.95% (unweighted) and 70.4% (weighted) on the IEMOCAP dataset. These correspond to an improvement of +7.35% (unweighted) and +4.3% (weighted) over state-of-the-art result on the STFT sepctrogram using CNN. Specially, the proposed method recognized 22.7% of the happy emotion samples correctly, whereas this number was 0% for state-of-the-art results. These results also promise a much wider use of the proposed pitch-synchronous SFF spectrogram for other speech-based applications.